TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025105553
公報種別
公開特許公報(A)
公開日
2025-07-10
出願番号
2024228437
出願日
2024-12-25
発明の名称
音高に基づく音声変換モデルのトレーニング方法及び音声変換システム
出願人
ナンジン シリコン インテリジェンス テクノロジー カンパニー リミテッド
代理人
個人
,
個人
,
個人
,
個人
,
個人
主分類
G10L
21/007 20130101AFI20250703BHJP(楽器;音響)
要約
【課題】音高に基づく音声変換モデルのトレーニング方法及び音声変換システムを提供する。
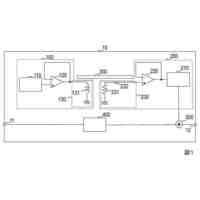
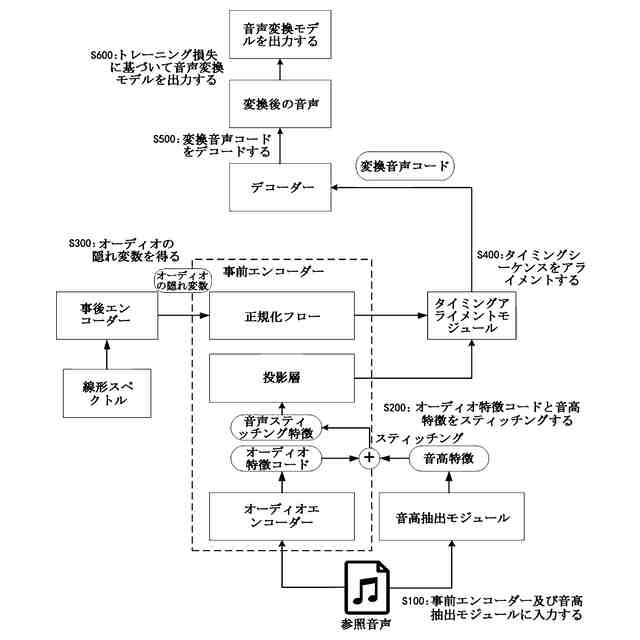
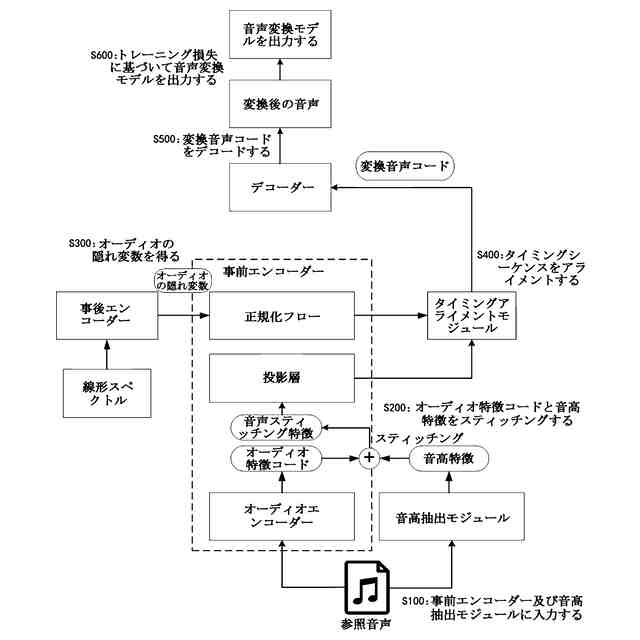
【解決手段】トレーニング方法は、事前エンコーダーによりオーディオ特徴コードを出力するステップと、音高抽出モジュールにより音高特徴を抽出するステップと、参照音声に対応する線形スペクトルを事後エンコーダーに入力してオーディオの隠れ変数を取得するステップと、オーディオ特徴コード及び音高特徴をスティッチングして音声スティッチング特徴を取得するステップと、得られた音声スティッチング特徴及びオーディオの隠れ変数をタイミングアライメントモジュールに入力して変換音声コードを取得するステップと、デコーダーにより変換音声コードをデコードして変換後の音声を取得するステップと、変換後の音声のトレーニング損失を計算して音声変換モデルの収束程度を判断するステップと、を含む。
【選択図】図1
特許請求の範囲
【請求項1】
事前エンコーダー、事後エンコーダー、タイミングアライメントモジュール、デコーダー及び音高抽出モジュールを含む音声変換モデルをトレーニングするために用いられ、
参照音声を前記事前エンコーダー及び前記音高抽出モジュールに入力して、前記事前エンコーダーによりオーディオ特徴コードを抽出し、前記音高抽出モジュールにより音高特徴を抽出するステップと、
前記オーディオ特徴コードと前記音高特徴に対して特徴スティッチングを実行し、音声スティッチング特徴を得るステップと、
前記参照音声に対応する線形スペクトルを前記事後エンコーダーに入力し、オーディオの隠れ変数を得るステップと、
前記タイミングアライメントモジュールにより前記音声スティッチング特徴と前記オーディオの隠れ変数のタイミングシーケンスをアライメントし、変換音声コードを得るステップと、
前記デコーダーにより前記変換音声コードをデコードして変換後の音声を得るステップと、
前記変換後の音声のトレーニング損失を計算し、前記トレーニング損失がトレーニング損失閾値以下であれば、トレーニング対象モデルの現在パラメータに基づいて音声変換モデルを出力し、前記トレーニング損失が前記トレーニング損失閾値よりも大きければ、前記音声変換モデルに対して反復トレーニングを実行するステップであって、前記トレーニング対象モデルは、収束までトレーニングされなかった音声変換モデルであるステップと、を含む、ことを特徴とする音高に基づく音声変換モデルのトレーニング方法。
続きを表示(約 2,800 文字)
【請求項2】
前記音高抽出モジュールは、エンコーダー層、フィルタ層、中間層及びデコーダー層を含み、
前記エンコーダー層、前記中間層及び前記デコーダー層は、前記音高抽出モジュールの第1エンコードブランチを形成し、前記エンコーダー層、前記フィルタ層及び前記デコーダー層は、前記音高抽出モジュールの第2エンコードブランチを形成する、ことを特徴とする請求項1に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項3】
前記エンコーダー層は、平均プーリング層及び畳み込みネットワークを含み、前記音高抽出モジュールにより音高特徴を抽出するステップは、
前記畳み込みネットワークにより前記参照音声の音高特徴ベクトルを抽出するステップと、
前記平均プーリング層により前記音高特徴ベクトルに対してダウンサンプリングを実行し、音高特徴コードを得るステップと、
前記デコーダー層により前記音高特徴コードに対してデコードを実行し、前記音高特徴を得るステップと、を含む、ことを特徴とする請求項2に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項4】
前記畳み込みネットワークは、畳み込みブロックを含み、前記畳み込みブロックは、2D畳み込み層、バッチ正規化層及びrelu関数を含み、前記畳み込みネットワークにより前記参照音声の音高特徴ベクトルを抽出するステップは、
前記2D畳み込み層により深層のオーディオベクトルを抽出するステップと、
前記バッチ正規化層により前記深層のオーディオベクトルに対して高速収束処理を実行して、前記深層のオーディオベクトルから収束音高特徴を抽出するステップと、
前記relu関数により前記収束音高特徴に非線形関係を追加し、前記音高特徴ベクトルを得るステップと、を含む、ことを特徴とする請求項3に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項5】
前記畳み込みネットワークの入力端と前記畳み込みネットワークの出力端との間には、ショートカット畳み込み層が設置され、前記relu関数により前記収束音高特徴に非線形関係を追加するステップの前に、
前記ショートカット畳み込み層によりショートカット音高特徴を抽出するステップと、
前記ショートカット音高特徴及び前記収束音高特徴をスティッチングし、音高スティッチング特徴を得るステップと、
前記relu関数により前記音高スティッチング特徴の間の非線形関係を追加し、前記音高特徴ベクトルを得るステップと、をさらに含む、ことを特徴とする請求項4に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項6】
前記デコーダー層は、逆畳み込み層及び前記畳み込みネットワークを含み、前記デコーダー層により前記音高特徴コードに対してデコードを実行するステップは、
前記逆畳み込み層により前記音高特徴コードに対して逆畳み込み計算を実行し、逆畳み込み特徴ベクトルを得るステップと、
前記畳み込みネットワークにより前記逆畳み込み特徴ベクトルに対してデコードを実行し、前記音高特徴を得るステップと、を含む、ことを特徴とする請求項4に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項7】
前記タイミングアライメントモジュールにより前記音声スティッチング特徴及び前記オーディオの隠れ変数のタイミングシーケンスをアライメントするステップは、
タイミングアライメントモジュールのテンプレート音声シーケンスを得るステップと、
前記テンプレート音声シーケンスに基づいて前記音声スティッチング特徴及び前記オーディオの隠れ変数のタイミングシーケンスをアライメントするステップと、
アライメントされた前記音声スティッチング特徴及び前記オーディオの隠れ変数に対してエンコードを実行し、前記変換音声コードを得るステップと、を含む、ことを特徴とする請求項1に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項8】
前記音声変換モデルは、スタイルエンコーダーをさらに含み、前記オーディオ特徴コード及び前記音高特徴に対して特徴スティッチングを実行するステップの後に、
前記スタイルエンコーダーにより前記参照音声のスタイル特徴を抽出するステップと、
前記スタイル特徴を前記音声スティッチング特徴にマッピングして、前記音声スティッチング特徴を更新するステップと、をさらに含む、ことを特徴とする請求項1に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項9】
前記トレーニング損失は、スペクトル損失を含み、前記変換後の音声のトレーニング損失を計算するステップは、
前記参照音声のスペクトル精度を取得し、前記変換後の音声のスペクトル精度を取得するステップと、
以下の式により参照音声のスペクトル精度及び前記変換後の音声のスペクトル精度に基づいて前記スペクトル損失を計算するステップであって、
TIFF
2025105553000009.tif
9
170
ここで、L
recon
は、前記スペクトル損失であり、x
mel
は、前記参照音声のスペクトル精度であり、x
^
mel
は、前記変換後の音声のスペクトル精度であるステップと、を含む、ことを特徴とする請求項1に記載の音高に基づく音声変換モデルのトレーニング方法。
【請求項10】
請求項1~9のいずれか1項に記載の音高に基づく音声変換モデルのトレーニング方法に基づいてトレーニングして取得するものであり、事前エンコーダー、事後エンコーダー、タイミングアライメントモジュール、デコーダー及び音高抽出モジュールを含む音声変換モデルを含み、前記事前エンコーダーは、参照音声のオーディオ特徴コードを抽出するように構成され、
前記音高抽出モジュールは、前記参照音声の音高特徴を抽出するように構成され、
前記事後エンコーダーは、前記参照音声に対応する線形スペクトルに基づいてオーディオの隠れ変数を生成するように構成され、
前記タイミングアライメントモジュールは、音声スティッチング特徴及び前記オーディオの隠れ変数のタイミングシーケンスをアライメントし、変換音声コードを得るように構成され、前記音声スティッチング特徴は、前記オーディオ特徴コード及び前記音高特徴が組み合わせて得られ、
前記デコーダーは、前記変換音声コードに対してデコードを実行し、変換後の音声を得るように構成される、ことを特徴とする音声変換システム。
発明の詳細な説明
【技術分野】
【0001】
本願は、音声変換の技術分野に関し、特に、音高に基づく音声変換モデルのトレーニング方法及び音声変換システムに関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
音声変換技術は、音声変換モデルにより、ある人物の音声を別の人物の音声に変換する技術であるが、高品質な人物の音声を得るために、大量のサンプルデータを用いて音声変換モデルをトレーニングする必要があり、こうすることで音声変換技術を通じてよりリアルな人物の音声を得る。
【0003】
実際のトレーニング過程において、大量のサンプルデータを取得することが困難であることが多いため、少量のサンプルデータを用いて音声変換モデルをトレーニングすることしかできない。しかしながら、人間の自然な音声の表現力が豊富であるため、音色及びリズムにおける人物の音声の変化が大きい一方、少量のサンプルデータによりトレーニングして得られた音声変換モデルで生成された人物の音声は、実際の人物の音声と一定の違いが存在する。
【0004】
音声の違いを低下させるために、少量のサンプルデータを用いて音声変換モデルをトレーニングする場合、プレトレーニングとモデルの微調整の方式を採用することができ、すなわち、まず大量のオーディオデータのデータセットに音声変換モデルのプレトレーニングを行い、その後に少量のサンプルデータを用いて音声変換モデルを微調整する。しかしながら、少量のサンプルデータの場合、変換後の人物の音声とリアルな人物の音声との音高類似度が低いという問題が依然として存在する。
【発明の概要】
【発明が解決しようとする課題】
【0005】
少量のサンプルデータの場合、変換後の人物の音声とリアルな人物の音声との音高類似度が低いという問題を減少させるためである。
【課題を解決するための手段】
【0006】
第1態様において、本願の一部の実施例は、音声変換モデルをトレーニングすることに応用される音高に基づく音声変換モデルのトレーニング方法を提供し、音声変換モデルは、事前エンコーダー、事後エンコーダー、タイミングアライメントモジュール、デコーダー及び音高抽出モジュールを含み、前記方法は、
参照音声を前記事前エンコーダー及び前記音高抽出モジュールに入力して、前記事前エンコーダーによりオーディオ特徴コードを抽出し、前記音高抽出モジュールにより音高特徴を抽出するステップと、
前記オーディオ特徴コードと前記音高特徴に対して特徴スティッチングを実行し、音声スティッチング特徴を得るステップと、
前記参照音声に対応する線形スペクトルを前記事後エンコーダーに入力し、オーディオの隠れ変数を得るステップと、
前記タイミングアライメントモジュールにより前記音声スティッチング特徴と前記オーディオの隠れ変数のタイミングシーケンスをアライメントし、変換音声コードを得るステップと、
前記デコーダーにより前記変換音声コードをデコードして変換後の音声を得るステップと、
前記変換後の音声のトレーニング損失を計算し、前記トレーニング損失がトレーニング損失閾値以下であれば、トレーニング対象モデルの現在パラメータに基づいて音声変換モデルを出力し、前記トレーニング損失が前記トレーニング損失閾値よりも大きければ、前記音声変換モデルに対して反復トレーニングを実行するステップであって、前記トレーニング対象モデルは、収束までトレーニングされなかった音声変換モデルであるステップと、を含む。
【0007】
いくつかの実施例において、前記音高抽出モジュールは、エンコーダー層、フィルタ層、中間層及びデコーダー層を含み、
前記エンコーダー層、前記中間層及び前記デコーダー層は、前記音高抽出モジュールの第1エンコードブランチを形成し、前記エンコーダー層、前記フィルタ層及び前記デコーダー層は、前記音高抽出モジュールの第2エンコードブランチを形成する。
【0008】
いくつかの実施例において、前記エンコーダー層は、平均プーリング層及び畳み込みネットワークを含み、前記音高抽出モジュールにより音高特徴を抽出するステップは、
前記畳み込みネットワークにより前記参照音声の音高特徴ベクトルを抽出するステップと、
前記平均プーリング層により前記音高特徴ベクトルに対してダウンサンプリングを実行し、音高特徴コードを得るステップと、
前記デコーダー層により前記音高特徴コードに対してデコードを実行し、前記音高特徴を得るステップと、を含む。
【0009】
いくつかの実施例において、前記畳み込みネットワークは、畳み込みブロックを含み、前記畳み込みブロックは、2D畳み込み層、バッチ正規化層及びrelu関数を含み、前記畳み込みネットワークにより前記参照音声の音高特徴ベクトルを抽出するステップは、
前記2D畳み込み層により深層のオーディオベクトルを抽出するステップと、
前記バッチ正規化層により前記深層のオーディオベクトルに対して高速収束処理を実行して、前記深層のオーディオベクトルから収束音高特徴を抽出するステップと、
前記relu関数により前記収束音高特徴に非線形関係を追加し、前記音高特徴ベクトルを得るステップと、を含む。
【0010】
いくつかの実施例において、前記畳み込みネットワークの入力端と前記畳み込みネットワークの出力端との間には、ショートカット畳み込み層が設置され、前記relu関数により前記収束音高特徴に非線形関係を追加するステップの前に、
前記ショートカット畳み込み層によりショートカット音高特徴を抽出するステップと、
前記ショートカット音高特徴及び前記収束音高特徴をスティッチングし、音高スティッチング特徴を得るステップと、
前記relu関数により前記音高スティッチング特徴の間の非線形関係を追加し、前記音高特徴ベクトルを得るステップと、をさらに含む。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
三井化学株式会社
遮音構造体
9日前
三井化学株式会社
遮音構造体
9日前
個人
弦楽器用押弦補助具及び弦楽器
9日前
三井化学株式会社
吸音構造体
4日前
三井化学株式会社
遮音構造体
16日前
林テレンプ株式会社
防音カバー
9日前
株式会社ドクター中松創研
歌及び歌の制作方法
19日前
株式会社総合車両製作所
吸音パネル
3日前
株式会社JVCケンウッド
車載装置
10日前
株式会社HOWA
遮音構造
16日前
個人
電気自動車等の「接近音」における最適な「音の種類」
12日前
カシオ計算機株式会社
楽器
16日前
株式会社第一興商
カラオケ装置
3日前
個人
電子管楽器
9日前
株式会社JVCケンウッド
情報処理装置及び情報処理方法
4日前
株式会社第一興商
カラオケ装置
4日前
株式会社コルグ
電子楽器用アナログエフェクタ
2日前
ヤマハ株式会社
発音制御装置
10日前
川上産業株式会社
吸音シート
23日前
ヤマハ株式会社
鍵盤装置用の鍵
25日前
AOBAENERGY株式会社
サービス提供機器
9日前
トヨタ自動車株式会社
電気自動車
11日前
トヨタ自動車株式会社
音響式遮音材の製造方法
10日前
井関農機株式会社
作業車の操縦者用騒音低減装置
3日前
ローランド株式会社
鍵盤装置および押鍵情報の検出方法
4日前
ローランド株式会社
鍵盤装置および押鍵情報の検出方法
4日前
ローランド株式会社
鍵盤装置および鍵の揺動の規制方法
4日前
日本電波工業株式会社
音声再生装置及び音声再生方法
3日前
株式会社パトライト
メール読み上げテキスト生成プログラム
23日前
ブラザー工業株式会社
カラオケシステム、及び、カラオケ装置
4日前
ヤマハ株式会社
音響測定装置、音響測定方法および音響測定プログラム
10日前
カシオ計算機株式会社
音響処理装置、音響処理システム、音響処理方法及びプログラム
17日前
トヨタ自動車株式会社
車両管理システム及び電気自動車
11日前
ピクシーダストテクノロジーズ株式会社
遮音システムおよび区画設備
25日前
株式会社丸高工業
防音板及びその附属品
4日前
ブラザー工業株式会社
カラオケシステム、カラオケ装置、及びカラオケ装置用のプログラム
3日前
続きを見る
他の特許を見る

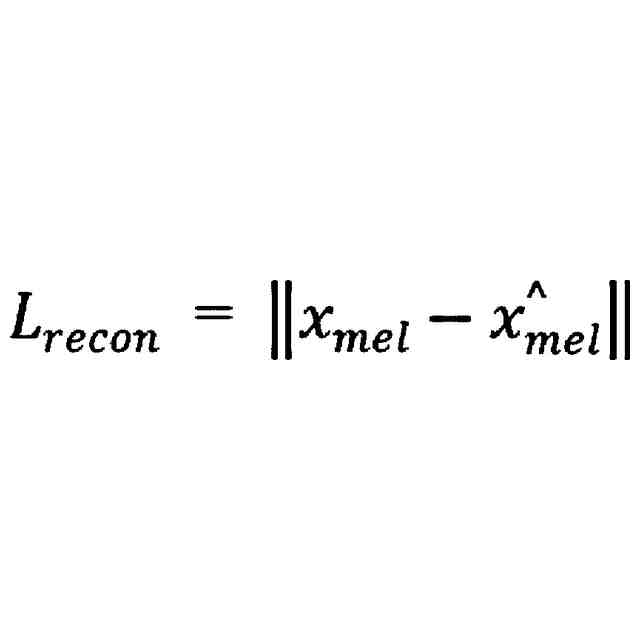
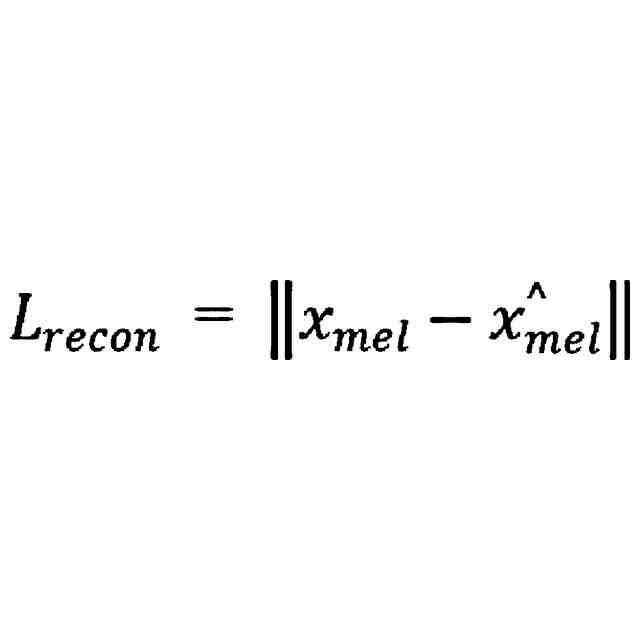
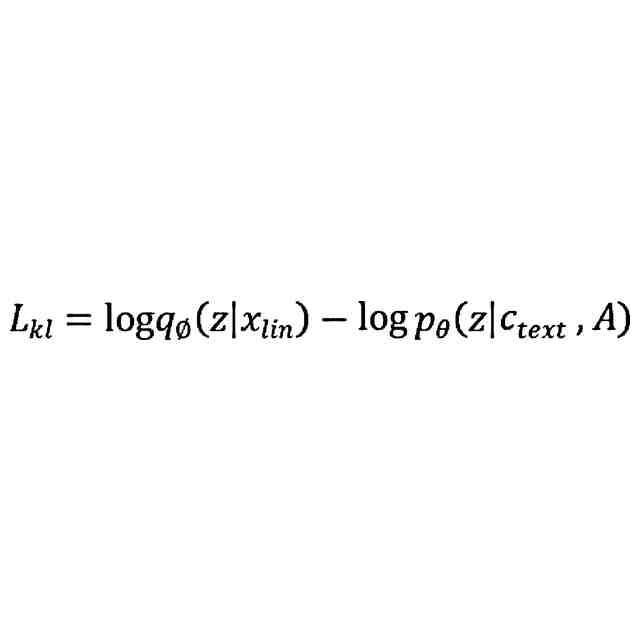


 特許ウォッチ
特許ウォッチ