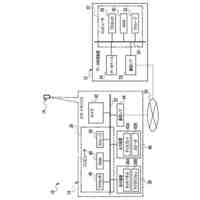
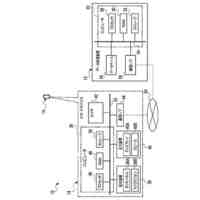
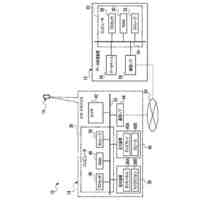
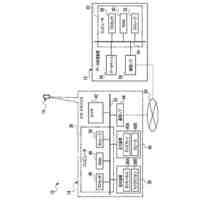
TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025065135
公報種別
公開特許公報(A)
公開日
2025-04-17
出願番号
2025003657,2022104204
出願日
2025-01-09,2017-09-11
発明の名称
ディープニューラルネットワークを使用する端末間話者認識
出願人
ピンドロップ セキュリティー、インコーポレイテッド
代理人
弁理士法人浅村特許事務所
主分類
G10L
17/00 20130101AFI20250410BHJP(楽器;音響)
要約
【課題】
トリプレットネットワークアーキテクチャを有するディープニューラルネットワーク(DNN)を利用して、フロントエンド特徴抽出器を訓練するシステムを提供する。
【解決手段】
DNNは、負の訓練サンプルのコホートセットを利用するバッチ処理に従って訓練される、3つのフィードフォワードニューラルネットワークを含む。訓練サンプルの各バッチが処理された後、DNNは、正および負のマージンと共に、例えば、それぞれのサンプル間の余弦類似度を利用する、損失関数に従って訓練されて、声紋の堅牢な表現を提供する。
【選択図】図2A
特許請求の範囲
【請求項1】
話者認識デバイスであって、
会話サンプルを記憶するメモリデバイスであって、前記会話サンプルが、
同一話者による会話サンプルのデュアルセット、
前記デュアルセットと同一話者によらない会話サンプルのコホートセット、および
話者モデルセット、を含む、メモリデバイスと、
トリプレットネットワークアーキテクチャを有するディープニューラルネットワークをモデル化するように構成されたプロセッサ基盤デバイスと、を備え、
前記プロセッサ基盤デバイスが、前記会話サンプルのデュアルセットが前記会話サンプルのコホートセットとの組み合わせで前記ディープニューラルネットワークを通して供給される、バッチ処理に従って前記ディープニューラルネットワークを訓練し、
前記プロセッサ基盤デバイスが、前記訓練されたディープニューラルネットワークを通して認識会話サンプルを供給し、前記認識会話サンプルおよび前記話者モデルの少なくとも1つに応じて、前記訓練されたディープニューラルネットワークの出力に基づいてユーザを検証または識別する、話者認識デバイス。
続きを表示(約 3,300 文字)
【請求項2】
前記ディープニューラルネットワークが、
第1の入力を受信および処理して、第1のネットワーク出力を生成する第1のフィードフォワードニューラルネットワークと、
第2の入力を受信および処理して、第2のネットワーク出力を生成する第2のフィードフォワードニューラルネットワークと、
第3の入力を受信および処理して、第3のネットワーク出力を生成する第3のフィードフォワードニューラルネットワークと、を含み、
複数の話者の各々に関して、前記メモリデバイスが、前記話者によるP個の会話サンプルの第1のセット
JPEG
2025065135000088.jpg
7
36
および前記話者によるP個の会話サンプルの第2のセット
JPEG
2025065135000089.jpg
7
36
を含み、Pが、2以上の整数であり、
前記ディープニューラルネットワークが、前記プロセッサ基盤デバイスによって訓練され、それにより、前記複数の話者の各々に関して、
前記ディープニューラルネットワークが、バッチ処理を実施し、その間に、前記対応する会話サンプルの第1のセットが前記第1のフィードフォワードニューラルネットワークを通して供給され、前記対応する会話サンプルの第2のセットが前記第2のフィードフォワードニューラルネットワークを通して供給され、前記会話サンプルのコホートセットが前記第3のフィードフォワードニューラルネットワークを通して供給され、
前記バッチ処理が完了すると、前記対応する会話サンプルの第1のセット、前記対応する会話サンプルの第2のセット、および前記会話サンプルのコホートセットにそれぞれ基づいて取得された、前記第1のネットワーク出力、前記第2のネットワーク出力、および前記第3のネットワーク出力に基づいて、損失関数が算出され、
前記算出された損失関数が、バックプロパゲーション法によって前記第1、第2および第3のフィードフォワードニューラルネットワークの各々の接続重みを修正するために使用される、請求項1に記載の話者認識デバイス。
【請求項3】
前記損失関数が、
前記会話サンプルの第1のセットのうちの1つ
JPEG
2025065135000090.jpg
4
3
に応じた前記第1のネットワーク出力と、前記対応する会話サンプルの第2のセットのうちの1つ
JPEG
2025065135000091.jpg
5
5
に応じた前記第2のネットワーク出力との間の類似度S
+
に対応する正の距離d
+
と、
前記会話サンプルの第1のセットのうちの前記1つ
JPEG
2025065135000092.jpg
4
3
に応じた前記第1のネットワーク出力と、前記コホートセットのそれぞれの会話サンプルに応じた前記第3のネットワーク出力のうちの最も類似の1つとの間の類似度S
-
に対応する負の距離d
-
と、に基づく、請求項2に記載の話者認識デバイス。
【請求項4】
前記正の距離d
+
および前記負の距離d
-
が、前記対応する類似度S
+
、S
-
に異なるそれぞれのマージンM
+
、M
-
を適用することによって決定される、請求項3に記載の話者認識デバイス。
【請求項5】
前記損失関数が、
JPEG
2025065135000093.jpg
10
59
によって定義され、式中、
JPEG
2025065135000094.jpg
7
31
であり、
d
+
=2(1-min((S
+
+M
+
),1)であり、
d
-
=2(1-max((S
+
+M
-
-1),0)であり、
JPEG
2025065135000095.jpg
9
80
であり、
JPEG
2025065135000096.jpg
9
115
であり、
JPEG
2025065135000097.jpg
3
4
が、N回の反復中に供給されたN個の負の会話サンプルのうちのn番目のものであり、
JPEG
2025065135000098.jpg
6
14
が、前記会話サンプルの第1のセットのうちの1つに応じた前記第1のネットワーク出力であり、
JPEG
2025065135000099.jpg
6
14
が、前記会話サンプルの第2のセットのうちの1つに応じた前記第2のネットワーク出力であり、
JPEG
2025065135000100.jpg
7
16
が、前記負の会話サンプル
JPEG
2025065135000101.jpg
3
4
に応じた前記第3のネットワーク出力であり、
JPEG
2025065135000102.jpg
7
20
であり、
JPEG
2025065135000103.jpg
7
22
であり、
Kが、定数である、請求項4に記載の話者認識デバイス。
【請求項6】
前記第1、第2および第3のフィードフォワードニューラルネットワークの各々が、少なくとも1つの重畳層および完全に接続された層を含む、請求項1に記載の話者認識デバイス。
【請求項7】
前記第1、第2および第3のフィードフォワードニューラルネットワークの各々が、少なくとも1つの最大プーリング層および後続の完全に接続された層をさらに含む、請求項6に記載の話者認識デバイス。
【請求項8】
前記第1、第2および第3のフィードフォワードニューラルネットワークのそれぞれ1つに入力される、各会話サンプルが、
基礎会話信号を複数のオーバーラッピングウィンドウにパーティション分割することと、
複数の特徴を前記オーバーラッピングウィンドウの各々から抽出することと、によって、前処理される、請求項6に記載の話者認識デバイス。
【請求項9】
前記第1、第2および第3のフィードフォワードニューラルネットワークが、前記前処理された会話サンプルを受信する第1の重畳層を含み、
前記第1の重畳層が、数N
C
の重畳フィルタを含み、
前記N
C
個の重畳フィルタの各々が、F×w
f
個のニューロンを有し、Fが、前記第1の重畳層の高さに対応し、w
f
が、前記重畳層の幅に対応し、
Fが、前記オーバーラッピングウィンドウの各々から抽出された前記特徴の数に等しく、w
f
が、5以下である、請求項8に記載の話者認識デバイス。
【請求項10】
前記デバイスが、前記ユーザが自己識別を入力する話者検証タスクを実施するように構成され、前記認識会話サンプルが、前記ユーザの識別情報が前記自己識別と同一であることを確認するために使用される、請求項1に記載の話者認識デバイス。
(【請求項11】以降は省略されています)
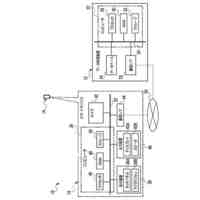
発明の詳細な説明
【技術分野】
【0001】
本出願は、2016年9月12日に出願された米国非仮特許出願第15/262,748号の優先権を主張し、この開示全体は、参照によって本明細書に組み込まれる。
本発明は、話者検証および/または話者の識別を含む音声認識を対象とする。さらに、本発明は、テキスト独立型話者認識を行うために使用され得る。
続きを表示(約 4,500 文字)
【背景技術】
【0002】
話者認識に対する現在の最新の手法は、音響混合ガウス分布(GMM)(全体の内容が参照によって本明細書に組み込まれる、Douglas A.Reynolds et al.,“Speaker Verification Using Adapted Gaussian Mixture Models,”Digital Signal Processing,2000を参照されたい)、または音声認識ディープニューラルネットワークアーキテクチャ(全体の内容が参照によって本明細書に組み込まれる、Y.Lei et al.,“A Novel Scheme for Speaker Recognition Using a Phonetically-Aware Deep Neural Network,”Proceedings of ICASSP 2014を参照されたい)のいずれかを使用して推定されるユニバーサルバックグラウンドモデル(UBM)に基づく。最も有効な技術は、全変動パラダイムを使用してUBMモデルを全ての会話発声に適合させることからなる(全体の内容が参照によって本明細書に組み込まれる、N.Dehak et al.,“Front-End Factor Analysis for Speaker Verification,”IEEE Transactions on Audio,Speech,and Language Processing,Vol.19,No.4,pp.788-798,May 2011を参照されたい)。全変動パラダイムは、話者およびチャネルに関する全情報を保存する「iベクトル」として知られる低次元特徴ベクトルを抽出することを目的とする。チャネル補償技術の適用後、結果として生じるiベクトルは、話者の声紋または音声署名とみなされ得る。
【0003】
かかる手法の主な欠点は、人間の知覚システムを再生するように設計された手作りの特徴のみを使用することによって、それらの手法が、話者を認識または検証するために重要である有用な情報を破棄する傾向にあることである。典型的には、上記の手法は、メル周波数ケプストラム係数(MFCC)等の低位の特徴を利用し、それらをガウス分布の定数(典型的には、1024または2048ガウス)に当てはめることを試みる。これは、ガウス仮定が必ずしも保たれない特徴空間内の複雑な構造をモデル化することを困難にする。
【発明の概要】
【0004】
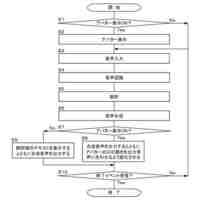
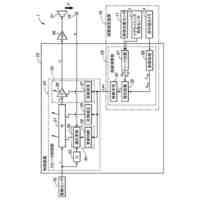
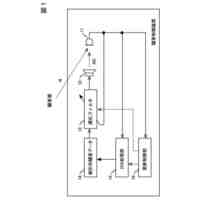
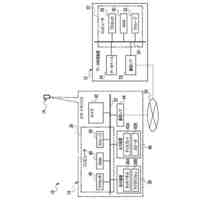
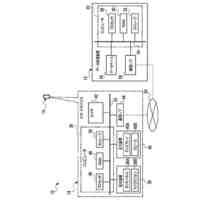
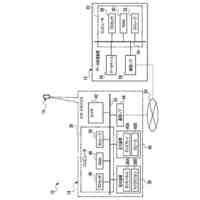
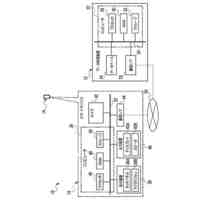
本発明は、トリプレットネットワークアーキテクチャを有するディープニューラルネットワークを利用して、フロントエンド特徴抽出器を訓練するシステムを対象とし、話者の識別情報の検証、または既知の話者の閉集合の中から話者を識別するタスクを実施するために使用される。
【0005】
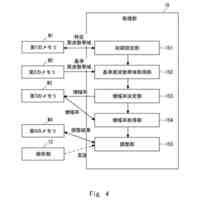
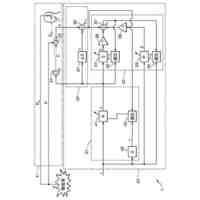
代表的な実施形態によると、システムは、メモリデバイスおよびプロセッサ基盤デバイスからなる。メモリデバイスは、同一話者による会話サンプルのデュアルセット、デュアルセットと同一話者によらない会話サンプルのコホートセット、および話者モデルセットを含む、会話サンプルを記憶する。さらに、プロセッサ基盤デバイスは、トリプレットネットワークアーキテクチャを有するディープニューラルネットワークをモデル化するように構成される。プロセッサ基盤デバイスは、会話サンプルのデュアルセットが会話サンプルのコホートセットとの組み合わせでディープニューラルネットワークを通して供給される、バッチ処理に従ってディープニューラルネットワークを訓練する。
【0006】
さらなる代表的な実施形態によると、ディープニューラルネットワークは、第1の入力を受信および処理して第1の出力を生成する第1のフィードフォワードニューラルネットワークと、第2の入力を受信および処理して第2の出力を生成する第2のフィードフォワードニューラルネットワークと、第3の入力を受信および処理して第3の出力を生成する第3のフィードフォワードニューラルネットワークと、を含み得る。また、複数の話者の各々に関して、メモリデバイスが、話者によるP個の会話サンプルの第1のセット
JPEG
2025065135000002.jpg
7
36
および話者によるP個の会話サンプルの第2のセット
JPEG
2025065135000003.jpg
8
39
を含み、Pが、2以上の整数である。ディープニューラルネットワークは、プロセッサ基盤デバイスによって訓練され、それにより、複数の話者の各々に関して、ディープニューラルネットワークは、バッチ処理を実施し、その間に、対応する会話サンプルの第1のセットが第1のフィードフォワードニューラルネットワークを通して供給され、対応する会話サンプルの第2のセットが第2のフィードフォワードニューラルネットワークを通して供給され、会話サンプルのコホートセットが第3のフィードフォワードニューラルネットワークを通して供給される。バッチ処理が完了すると、対応する会話サンプルの第1のセット、対応する会話サンプルの第2のセット、および会話サンプルのコホートセットにそれぞれ基づいて取得された、第1のネットワーク出力、第2のネットワーク出力、および第3のネットワーク出力に基づいて、損失関数が算出される。算出された損失関数は、バックプロパゲーション法によって第1、第2および第3のフィードフォワードニューラルネットワークの各々の接続重みを修正するために使用される。
【0007】
さらなる代表的な実施形態によると、上記の損失関数は、会話サンプルの第1のセットのうちの1つ
JPEG
2025065135000004.jpg
4
3
に応じた第1のネットワーク出力と、対応する会話サンプルの第2のセットのうちの1つ
JPEG
2025065135000005.jpg
5
5
に応じた第2のネットワーク出力との間の類似度S
+
に対応する正の距離d
+
と、会話サンプルの第1のセットのうちの1つ
JPEG
2025065135000006.jpg
4
3
に応じた第1のネットワーク出力と、コホートセットのそれぞれの会話サンプルに応じた第3のネットワーク出力のうちの最も類似の1つとの間の類似度S
-
に対応する負の距離d
-
と、に基づき得る。さらに、正の距離d
+
および負の距離d
-
が、対応する類似度S
+
、S
-
に異なるそれぞれのマージンM
+
、M
-
を適用することによって決定され得る。特に、損失関数は、
JPEG
2025065135000007.jpg
8
50
として定義され得、式中、
JPEG
2025065135000008.jpg
7
31
であり、d
+
=2(1-min((S
+
+M
+
),1)であり、d
-
=2(1-max((S
+
+M
-
-1),0)であり、
JPEG
2025065135000009.jpg
9
84
であり、
JPEG
2025065135000010.jpg
11
116
であり、
TIFF
2025065135000011.tif
3
4
は、N回の反復中に供給されたN個の負の会話サンプルのうちのn番目のものであり、
JPEG
2025065135000012.jpg
6
14
は、会話サンプルの第1のセットのうちの1つに応じた第1のネットワーク出力であり、
JPEG
2025065135000013.jpg
6
14
は、会話サンプルの第2のセットのうちの1つに応じた第2のネットワーク出力であり、
JPEG
2025065135000014.jpg
7
16
は、負の会話サンプル
JPEG
2025065135000015.jpg
3
4
に応じた第3のネットワーク出力であり、Kは、定数である。
【0008】
代替的な代表的な実施形態によると、損失関数は、等価エラー率(EER)メトリックに関連し得る。この場合において、損失関数は、
JPEG
2025065135000016.jpg
12
52
として定義され得、式中、μ
+
および
TIFF
2025065135000017.tif
3
4
は、ガウス分布に基づく正の認識スコアの平均および標準偏差であり、
TIFF
2025065135000018.tif
3
4
および
TIFF
2025065135000019.tif
2
4
は、ガウス分布に基づく負の認識スコアの平均および標準偏差である。
【0009】
代表的な実施形態によると、トリプレットネットワークアーキテクチャに採用されるフィードフォワードニューラルネットワークの各々は、少なくとも1つの重畳層、少なくとも1つの最大プーリング層、および完全に接続された層を含み得る。
【0010】
さらに、一代表的な実施形態において、本発明は、ユーザが自己識別を入力する話者検証タスクを実施するために使用され得、認識会話サンプルは、ユーザの識別情報が自己識別と同一であることを確認するために使用される。別の代表的な実施形態において、本発明は、それぞれの会話サンプルを伴って記憶された複数の潜在的識別情報からユーザを識別するために認識会話サンプルが使用される、話者識別タスクを実施するために使用され得る。上記の実施形態は、相互排他的ではなく、同一トリプレットネットワークアーキテクチャが、両方のタスクを実施するために使用され得る。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
リアルタイム翻訳システム
5日前
株式会社SOU
保護具
18日前
三井化学株式会社
防音構造
12日前
三井化学株式会社
防音構造体
13日前
三井化学株式会社
遮音構造体
19日前
東レ・セラニーズ株式会社
混繊不織布
18日前
株式会社エクシング
カラオケシステム
27日前
スマートライフサプライ合同会社
楽器スタンド
18日前
株式会社ルミカ
カード型保安用品
27日前
ヤマハ株式会社
楽器用響板および弦楽器
1か月前
トヨタ自動車株式会社
電動車両の制御装置
27日前
リオン株式会社
雑音抑制処理方法及び聴取装置
29日前
横浜ゴム株式会社
多層空洞音響材
26日前
中強光電股ふん有限公司
電子システム及びその制御方法
18日前
ヤマハ株式会社
ギターのボディ構造体およびギター
1か月前
トヨタ自動車株式会社
情報処理装置
5日前
株式会社第一興商
カラオケ装置
14日前
ドリックス株式会社
消音パネル
15日前
ヤマハ株式会社
板材、楽器及び弦楽器
1か月前
カシオ計算機株式会社
電子機器
18日前
株式会社JVCケンウッド
聴音装置、聴音方法及びプログラム
18日前
株式会社しくみ
音声翻訳プログラム
今日
株式会社第一興商
カラオケシステム
28日前
本田技研工業株式会社
車載音響制御装置
1か月前
カシオ計算機株式会社
電子鍵盤楽器
18日前
アルプスアルパイン株式会社
能動騒音制御システム
27日前
本田技研工業株式会社
能動型騒音低減装置
1か月前
ソフトバンクグループ株式会社
システム
15日前
ソフトバンクグループ株式会社
システム
14日前
ソフトバンクグループ株式会社
システム
14日前
ソフトバンクグループ株式会社
システム
18日前
ソフトバンクグループ株式会社
システム
14日前
ソフトバンクグループ株式会社
システム
18日前
ソフトバンクグループ株式会社
システム
14日前
ソフトバンクグループ株式会社
システム
15日前
ソフトバンクグループ株式会社
システム
15日前
続きを見る
他の特許を見る

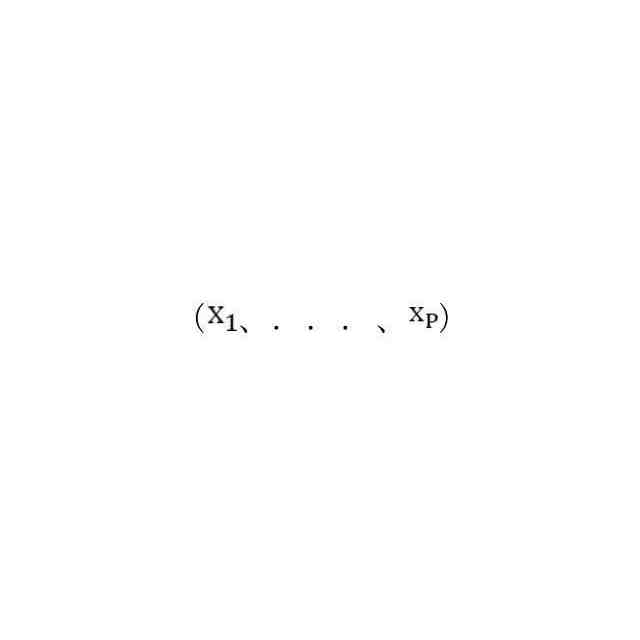
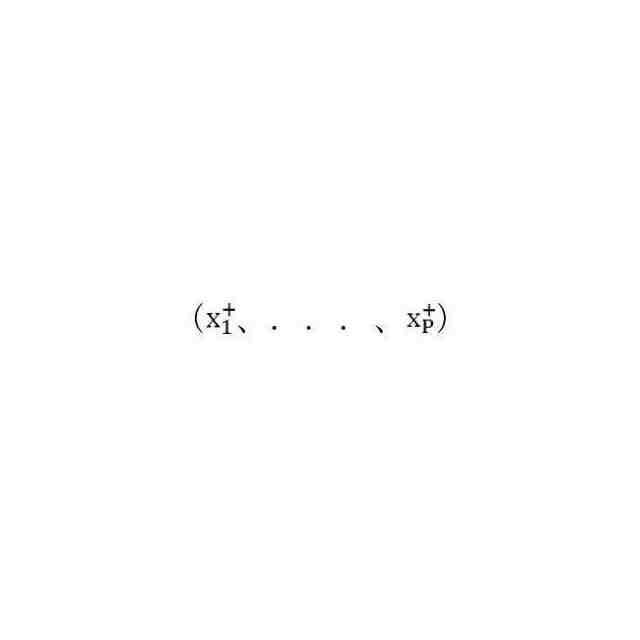



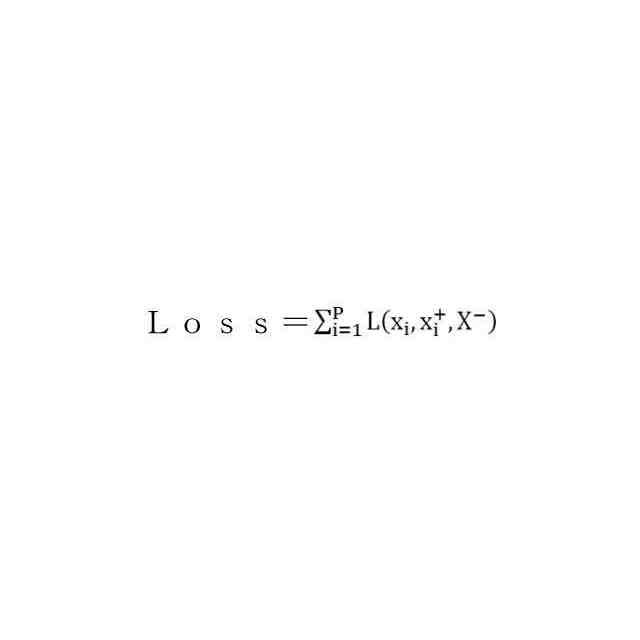
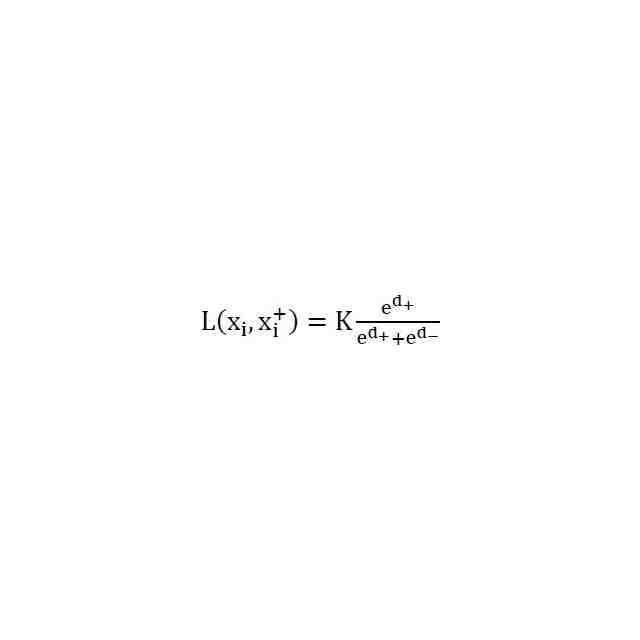


 特許ウォッチ
特許ウォッチ