TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024119383
公報種別
公開特許公報(A)
公開日
2024-09-03
出願番号
2023026245
出願日
2023-02-22
発明の名称
対話理解装置、および対話理解方法
出願人
本田技研工業株式会社
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
15/22 20060101AFI20240827BHJP(楽器;音響)
要約
【課題】対話システムへの入力を破損する可能性のある異常を検出することができる対話理解装置、および対話理解方法を提供することを目的とする。
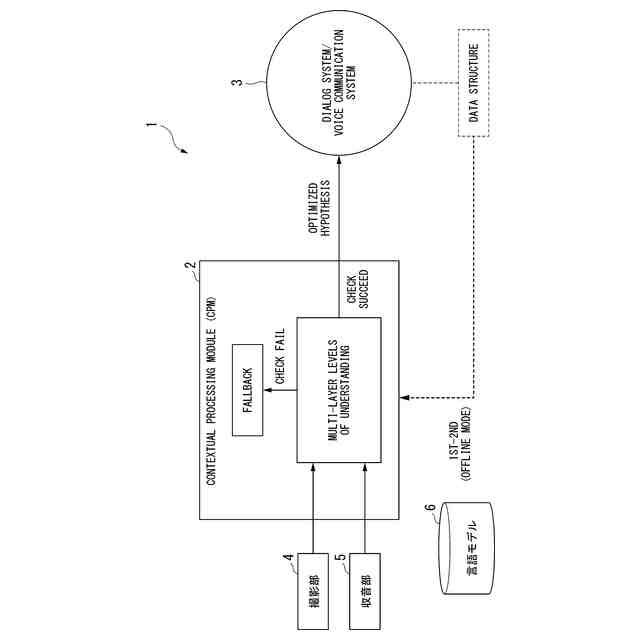
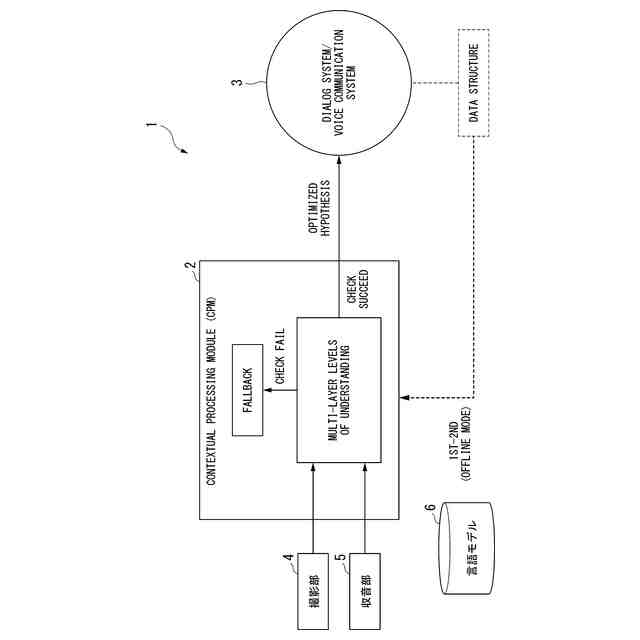
【解決手段】対話理解装置は、音声信号を収音する収音部と、文脈処理部と、人間との対話を行う対話システムと、を備え、文脈理解部は、収音部から得た情報を処理する層を複数層備え、複数の各層において、収音された音声信号に対しての所定の処理が成功しない場合のフォールバック処理部を層毎に備え、フォールバック処理部が行うフォールバック処理に応じた対応を行った後、次の層の処理に進み、文脈理解部での処理が完了した音声信号を前記対話システムに入力する。
【選択図】図1
特許請求の範囲
【請求項1】
音声信号を収音する収音部と、
文脈処理部と、
人間との対話を行う対話システムと、を備え、
前記文脈処理部は、前記収音部から得た情報を処理する層を複数備え、
前記複数の各層において、収音された音声信号に対しての所定の処理が成功しない場合のフォールバック処理部を前記層毎に備え、
前記フォールバック処理部が行うフォールバック処理に応じた対応を行った後、次の層の処理に進み、
前記文脈処理部での処理が完了した音声信号を前記対話システムに入力する、
対話理解装置。
続きを表示(約 1,700 文字)
【請求項2】
前記文脈処理部は、収音された音声信号に対しての所定の処理を行うことで、音声信号をテキスト化し、前記テキスト化したフレーズから固有名詞であるエンティティを検出し、前記テキスト化されたフレーズを、言語モデルを用いて理解して発言者の発話意図を推定する、
請求項1に記載の対話理解装置。
【請求項3】
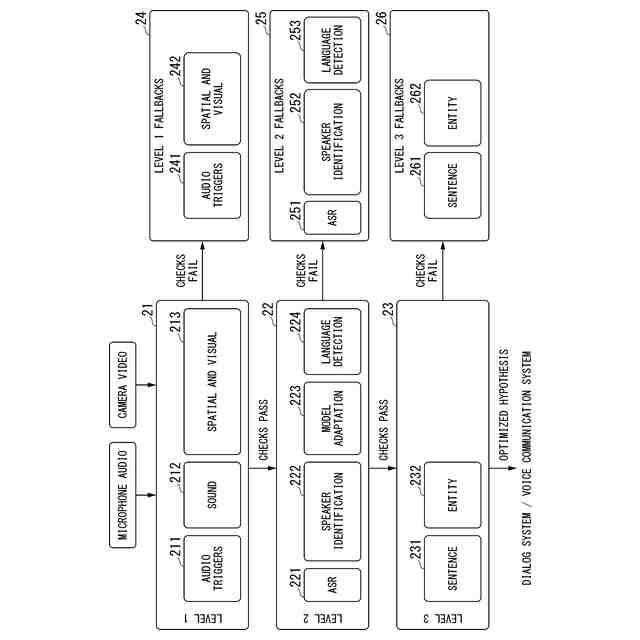
前記複数層は3層であり、
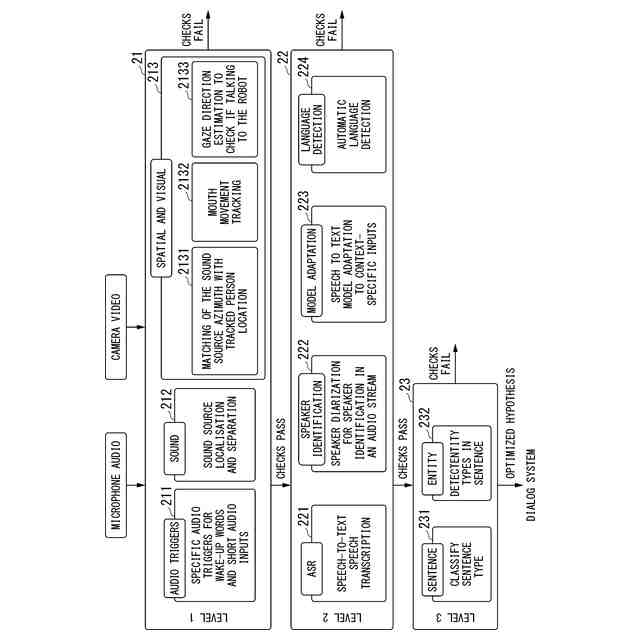
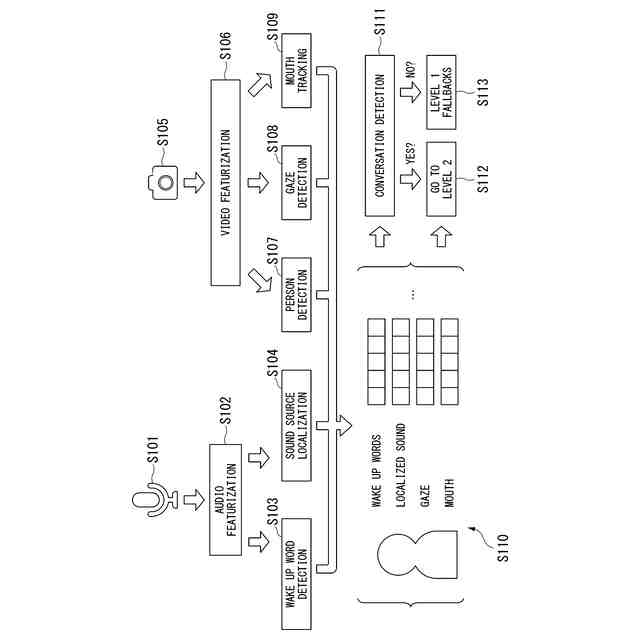
第1の層は、ウェイクアップワードの検出を行うオーディオトリガー部と、音源の位置特定と音源分離処理を行うサウンド部を備え、
第2の層は、前記第1の層が処理した結果の音声信号に対して、音声からテキストへ変換するASR部と、オーディオストリームの話者識別のための話者ダイアラゼーション処理を行う話者識別部と、文脈依存の入力に対応するSpeech to Textモデルの適応を行うモデル適応部と、自部が備える言語モデルを参照して認識された言語が何語であるか検出する言語検出部を備え、
第3の層は、前記第2の層でテキスト化された文の種類を分類する文章処理部と、前記テキスト化された文中のエンティティタイプの検出を行う文章判別部を備える、
請求項1または請求項2に記載の対話理解装置。
【請求項4】
前記第1の層に対する第1のフォールバック処理部は、ウェイクアップワードが検出されるまで、音声入力を無視し、
前記第2の層に対する第2のフォールバック処理部は、前記第2の層で音声認識処理ができない場合に入力された音声信号をノイズとして無視し、前記第2の層で発言者の交代を検出した場合に予め定められている所定の反応を行い、前記第2の層で前記発言者の発話している言語がサポートされている場合に動的に言語を切り替え、前記発言者がサポートされていない言語で話している場合に話し手に通知し、
前記第3の層に対する第3のフォールバック処理部は、想定内の質問を受けた場合に具体的なリアクションを挿入し、想定外の質問を受けた場合に具体的なリアクションを挿入し、前記発言者の文に必要なエンティティが検出されなかった場合にフォローアップの質問をする、
請求項3に記載の対話理解装置。
【請求項5】
発言者の画像を撮影する撮影部を備え、
前記第3の層は、前記撮影された画像を用いて、前記音源の方位と追跡された人物の位置のマッチングを行い、前記発言者の口の動きのトラッキングを行、前記対話システムと前記発言者の会話を確認するための視線方向推定処理を行う空間視覚部を備え、
前記第1の層に対する第1のフォールバック処理部は、前記発言者の音源方向と撮像された画像から検出される人物とが空間的に一致しない場合に前記音声をノイズとして無視し、前記撮影された画像から前記発言者の口の動きが検出されなかった場合に前記音声をノイズとして無視し、前記発言者が他の人を見ていたり前記対話システムを見ていない場合に前記音声をノイズとして無視する、
請求項3に記載の対話理解装置。
【請求項6】
前記文脈処理部の学習時、前記文脈処理部には、1回目に前記対話システムからシステム情報が入力され、2回目でデータ構造と他の要求に基づいて異なるレベルの理解や文脈を構築する、
請求項1または請求項2に記載の対話理解装置。
【請求項7】
収音部と文脈処理部と対話システムを備える対話理解装置における対話理解方法であって、
前記文脈処理部が、前記収音部から得た情報を処理する層を複数備え、前記複数の各層において収音された音声信号に対しての所定の処理が成功しない場合のフォールバック処理部を前記層毎に備え、
収音部が、音声信号を収音し、
対話システムが、人間との対話を行い、
前記文脈処理部が、前記フォールバック処理部が行うフォールバック処理に応じた対応を行った後、次の層の処理に進め、
前記文脈処理部が、処理が完了した音声信号を前記対話システムに入力する、
対話理解方法。
発明の詳細な説明
【技術分野】
【0001】
本発明は、対話理解装置、および対話理解方法に関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
近年、音声による指示や、利用者と音声によるコミュニケーションを行うロボットや装置が開発されている。音声コマンド処理システムのダイアログシステムは、ロボットとコミュニケーションをとる際に非常に有効である。これにより、ロボットはコマンドを理解し、そのコマンドを適宜実行することができるようになる。このような対話システムは、音声認識結果から得たテキストデータを用いている。また、対話システムでは、例えば、想定される対話について複数のシナリオを有し、このようなシナリオに基づいて、対話を行っている(例えば参考文献1参照)。
【先行技術文献】
【特許文献】
【0003】
特開2019-84598号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来技術では、会話におけるシナリオから外れていたり、発言者の発話内容が想定されてる構造になっていない場合など、対話システムがうまく機能しない場合がある。例えば、仮説が破損していたり、相手の会話スタイルが対話入力の構造に合っていない場合、対話システムはうまく機能しなかった。
【0005】
本発明は、上記の問題点に鑑みてなされたものであって、対話システムへの入力を破損する可能性のある異常を検出することができる対話理解装置、および対話理解方法を提供することを目的とする。
【課題を解決するための手段】
【0006】
(1)上記目的を達成するため、本発明の一態様に係る対話理解装置は、音声信号を収音する収音部と、文脈処理部と、人間との対話を行う対話システムと、を備え、前記文脈処理部は、前記収音部から得た情報を処理する層を複数備え、前記複数の各層において、収音された音声信号に対しての所定の処理が成功しない場合のフォールバック処理部を前記層毎に備え、前記フォールバック処理部が行うフォールバック処理に応じた対応を行った後、次の層の処理に進み、前記文脈処理部での処理が完了した音声信号を前記対話システムに入力する、対話理解装置である。
【0007】
(2)(1)の対話理解装置において、前記文脈処理部は、収音された音声信号に対しての所定の処理を行うことで、音声信号をテキスト化し、前記テキスト化したフレーズから固有名詞であるエンティティを検出し、前記テキスト化されたフレーズを、言語モデルを用いて理解して発言者の発話意図を推定するようにしてもよい。
【0008】
(3)(1)または(2)の対話理解装置において、前記複数層は3層であり、
第1の層は、ウェイクアップワードの検出を行うオーディオトリガー部と、音源の位置特定と音源分離処理を行うサウンド部を備え、第2の層は、前記第1の層が処理した結果の音声信号に対して、音声からテキストへ変換するASR部と、オーディオストリームの話者識別のための話者ダイアラゼーション処理を行う話者識別部と、文脈依存の入力に対応するSpeech to Textモデルの適応を行うモデル適応部と、自部が備える言語モデルを参照して認識された言語が何語であるか検出する言語検出部を備え、第3の層は、前記第2の層でテキスト化された文の種類を分類する文章処理部と、前記テキスト化された文中のエンティティタイプの検出を行う文章判別部を備えるようにしてもよい。
【0009】
(4)(3)の対話理解装置において、前記第1の層に対する第1のフォールバック処理部は、ウェイクアップワードが検出されるまで、音声入力を無視し、前記第2の層に対する第2のフォールバック処理部は、前記第2の層で音声認識処理ができない場合に入力された音声信号をノイズとして無視し、前記第2の層で発言者の交代を検出した場合に予め定められている所定の反応を行い、前記第2の層で前記発言者の発話している言語がサポートされている場合に動的に言語を切り替え、前記発言者がサポートされていない言語で話している場合に話し手に通知し、前記第3の層に対する第3のフォールバック処理部は、想定内の質問を受けた場合に具体的なリアクションを挿入し、想定外の質問を受けた場合に具体的なリアクションを挿入し、前記発言者の文に必要なエンティティが検出されなかった場合にフォローアップの質問をするようにしてもよい。
【0010】
(5)(3)の対話理解装置において、発言者の画像を撮影する撮影部を備え、前記第3の層は、前記撮影された画像を用いて、前記音源の方位と追跡された人物の位置のマッチングを行い、前記発言者の口の動きのトラッキングを行、前記対話システムと前記発言者の会話を確認するための視線方向推定処理を行う空間視覚部を備え、前記第1の層に対する第1のフォールバック処理部は、前記発言者の音源方向と撮像された画像から検出される人物とが空間的に一致しない場合に前記音声をノイズとして無視し、前記撮影された画像から前記発言者の口の動きが検出されなかった場合に前記音声をノイズとして無視し、前記発言者が他の人を見ていたり前記対話システムを見ていない場合に前記音声をノイズとして無視するようにしてもよい。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
本田技研工業株式会社
車体構造
4日前
本田技研工業株式会社
回転電機
5日前
本田技研工業株式会社
回転電機
5日前
本田技研工業株式会社
車体構造
4日前
本田技研工業株式会社
揺動式車両
4日前
本田技研工業株式会社
無段変速機
8日前
本田技研工業株式会社
無段変速機
8日前
本田技研工業株式会社
運転制御装置
11日前
本田技研工業株式会社
電源システム
11日前
本田技研工業株式会社
車両システム
8日前
本田技研工業株式会社
車両の床構造
5日前
本田技研工業株式会社
回転電機のステータコア
5日前
株式会社ダイフク
搬送装置
4日前
本田技研工業株式会社
鞍乗り型車両の車体前部構造
8日前
本田技研工業株式会社
ロータの製造方法及びロータ
4日前
本田技研工業株式会社
情報処理装置、情報処理方法、及びプログラム
8日前
本田技研工業株式会社
車両制御装置、車両制御方法、及び、プログラム
4日前
本田技研工業株式会社
姿勢推定装置、姿勢推定方法、およびプログラム
5日前
本田技研工業株式会社
車両制御装置、車両制御方法、及び、プログラム
4日前
本田技研工業株式会社
車両制御装置、車両制御方法、及び、プログラム
4日前
本田技研工業株式会社
車両管理装置、車両管理方法、およびプログラム
4日前
本田技研工業株式会社
車両制御装置、車両制御方法、及び、プログラム
4日前
本田技研工業株式会社
車両公開情報管理装置、車両公開方法及びプログラム
4日前
本田技研工業株式会社
車両公開情報管理装置、車両公開方法及びプログラム
4日前
本田技研工業株式会社
車両公開情報管理装置、車両公開方法及びプログラム
4日前
本田技研工業株式会社
情報処理装置、情報処理方法、記憶媒体及びプログラム
5日前
本田技研工業株式会社
電力制御システム、電力制御装置、および電力制御方法
8日前
本田技研工業株式会社
車両輸送支援装置、車両輸送支援方法、およびプログラム
5日前
本田技研工業株式会社
個人間取引仲介装置、個人間取引仲介方法、およびプログラム
8日前
株式会社第一興商
カラオケ装置
11日前
株式会社今仙電機製作所
自動車用警報音発生装置
8日前
株式会社河合楽器製作所
鍵盤装置
11日前
株式会社河合楽器製作所
鍵盤装置
5日前
株式会社河合楽器製作所
鍵盤装置
5日前
個人
アコースティック・ギター用単弦牽引装置のための台座
11日前
株式会社イノアックコーポレーション
防音構造
4日前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ