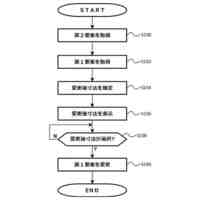
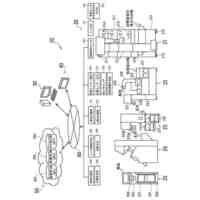
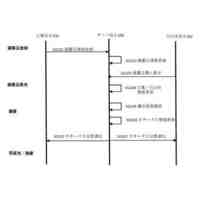
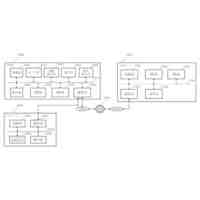
TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025113278
公報種別
公開特許公報(A)
公開日
2025-08-01
出願番号
2025079077
出願日
2025-05-10
発明の名称
マルチモーダル理解に基づく適応型分散圧縮システム
出願人
ニューヨークゼネラルグループインク
,
Nyu-Yo-ku Zeneral Guru-pu, Inku.
代理人
主分類
G06N
3/0495 20230101AFI20250725BHJP(計算;計数)
要約
【課題】本発明は、大規模言語モデル(LLM)と分散コンピューティングを組み合わせたデータ圧縮システムに関する。従来の圧縮技術は統計的冗長性のみを考慮し、意味論的構造や文脈情報を活用できないという課題があった。また、大規模モデルベースの圧縮はリソース要求が高く、マルチモーダルデータの相互関係を十分に活用できていなかった。
【解決手段】本発明は、マルチモーダル理解モジュールによる異なるデータ形式間の相互関係活用、適応型モデル選択モジュールによるデータ特性と通信環境に応じた最適なモデル選択、分散協調圧縮モジュールによる端末間の共有知識活用、知識蒸留モジュールによる大規模モデルの圧縮能力の軽量モデルへの転送、適応型算術符号化モジュールによる効率的な符号化を統合することで、リソース制約環境でも高効率な圧縮を実現する。
【選択図】なし
特許請求の範囲
【請求項1】
データを圧縮する方法であって、複数のモダリティを含むデータの相互関係を分析するステップと、データ特性と通信環境に基づいて最適な圧縮モデルを選択するステップと、送信側と受信側の共有知識に基づいて差分情報を抽出するステップと、選択されたモデルを用いて差分情報を圧縮するステップとを含むことを特徴とするデータ圧縮方法。
続きを表示(約 490 文字)
【請求項2】
請求項1に記載のデータ圧縮方法において、前記複数のモダリティはテキスト、画像、音声、動画のうち少なくとも2つを含み、前記相互関係の分析はクロスモーダル注意機構を用いて異なるモダリティ間の意味的対応関係をモデル化するステップを含み、前記最適な圧縮モデルの選択はデータの複雑さ、通信帯域幅、端末のリソース制約に基づく多目的最適化によって行われ、前記共有知識はドメイン固有知識、過去の通信内容、一般的世界知識のうち少なくとも1つを含むことを特徴とするデータ圧縮方法。
【請求項3】
データを圧縮するシステムであって、複数のモダリティを含むデータの相互関係を分析するマルチモーダル理解モジュールと、データ特性と通信環境に基づいて最適な圧縮モデルを選択する適応型モデル選択モジュールと、送信側と受信側の共有知識に基づいて差分情報を抽出する分散協調圧縮モジュールと、大規模モデルの圧縮能力を軽量モデルに蒸留する知識蒸留モジュールと、選択されたモデルを用いて差分情報を圧縮する適応型算術符号化モジュールとを備えることを特徴とするデータ圧縮システム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、データ圧縮技術、特に大規模言語モデル(LLM)と分散コンピューティングを組み合わせた革新的なデータ圧縮システムに関するものである。具体的には、テキスト、画像、音声、動画などの多様なデータ形式に対して、端末間の協調的理解と適応的モデル選択により超高効率な可逆圧縮を実現するシステムに関する。また、本発明は次世代通信技術(6G等)、エッジコンピューティング、モバイルデバイス、IoTシステムなどにおけるデータ転送効率の飛躍的向上を目的とした技術に関連する。さらに、リソース制約環境における高度な人工知能技術の応用、特にマルチモーダルデータの意味論的理解と分散処理に基づく新たなパラダイムのデータ圧縮アーキテクチャに関するものである。
続きを表示(約 7,100 文字)
【背景技術】
【0002】
データ圧縮技術は、デジタル通信の基盤として長年研究開発されてきた。従来の圧縮技術は主にクロード・シャノンによって確立された情報理論的枠組みに基づいており、ZIP、FLAC、PNG、H.264/H.265などの標準的な圧縮方式が広く普及している。これらの方式は、データ内の統計的冗長性を検出し、より効率的な表現に変換することで圧縮を実現している。例えば、ハフマン符号化やランレングス符号化などのエントロピー符号化技術、予測符号化、変換符号化(DCT、ウェーブレット変換など)が広く用いられている。
【0003】
これらの伝統的な圧縮技術は、シャノンの情報理論に基づく理論的限界(シャノンエントロピー)に制約されており、データの統計的性質のみを考慮している。そのため、データの意味論的構造や文脈情報を十分に活用できないという本質的な限界がある。例えば、「ニューヨークは米国の都市である」という文は、「ニューヨーク」と「米国」の意味的関係を理解できなければ、単なる文字列の統計的性質に基づいた圧縮しかできない。
【0004】
近年、Li等の研究(arXiv:2407.07723v3)により、大規模言語モデル(LLM)を活用した「LMCompress」が提案された。この技術は「理解はすなわち圧縮である」という洞察に基づき、大規模モデルの理解能力を活用することで、従来の圧縮技術を大幅に上回る圧縮率を実現している。LMCompressは、ソロモノフ帰納(Solomonoff induction)の計算不可能な概念を大規模モデルによって近似することで、データの深い理解に基づく圧縮を実現する新たなパラダイムを提示した。
【0005】
具体的には、LMCompressはテキストデータでbz2の約4倍、画像データでJPEG-XLの約2倍、音声データでFLACの約2倍、動画データでH.264の約2倍の圧縮率を達成している。この画期的な成果は、大規模モデルがデータの統計的特性だけでなく、意味論的構造や文脈情報を理解し活用できることを示している。
【0006】
しかしながら、LMCompressには以下のような課題が残されている。
1. 大規模モデルの計算リソース要求が高く、モバイル端末などのリソース制約環境での実装が困難である。例えば、iGPT(image-GPT)やLLaMA3などの大規模モデルは数十億から数千億のパラメータを持ち、数百GBのメモリと高性能GPUを必要とする。これらのリソース要件は、バッテリー駆動のモバイルデバイスやIoT機器では満たすことが困難である。
2. 単一モデルによる圧縮のため、マルチモーダルデータの相互関係を十分に活用できていない。例えば、プレゼンテーションファイルにおけるスライド画像とナレーション音声の間には強い相関関係があるが、LMCompressではこれらを独立したデータとして処理するため、相互補完的な情報を活用した圧縮ができない。
3. 通信環境やデータ特性に応じた適応的な圧縮戦略が欠如している。LMCompressは固定的なモデルを使用するため、帯域幅や遅延などの通信条件が変化する環境や、データの複雑さが異なる状況に対して最適な圧縮を提供できない。例えば、低帯域幅環境では圧縮率よりも処理速度を優先すべき場合があるが、そのような適応的な切り替えができない。
4. 分散環境における協調的圧縮の枠組みが確立されていない。送信側と受信側が共有知識を活用して協調的に圧縮・展開を行うことで、通信効率をさらに向上させる可能性があるが、LMCompressではこのような協調的アプローチが採用されていない。
5. 大規模モデルの知識を軽量モデルに効率的に転送する手法が確立されていない。リソース制約環境でも高効率圧縮を実現するためには、大規模モデルの圧縮能力を軽量モデルに蒸留する技術が必要だが、LMCompressではこの点が考慮されていない。
【0007】
これらの課題は、LMCompressの実用化において重要な障壁となっている。特に、モバイルデバイスやIoT機器など、リソースが限られた環境での応用を考えると、これらの課題を解決することが不可欠である。また、次世代通信技術(6G等)においては、多様な通信環境に適応し、端末間で協調的に動作する圧縮システムが求められている。
【先行技術文献】
【非特許文献】
【0008】
Ziguang Li, Chao Huang, Xuliang Wang, Haibo Hu, Cole Wyeth, Dongbo Bu, Quan Yu, Wen Gao, Xingwu Liu, Ming Li, “Lossless data compression by large models,” arXiv preprint arXiv:2407.07723, Jun. 2024 (rev. Apr. 30, 2025)
【発明の概要】
【発明が解決しようとする課題】
【0009】
本発明が解決しようとする課題は以下の通りである。
1. リソース制約環境(モバイル端末等)でも効率的に動作する、軽量かつ高性能な圧縮システムの提供
モバイルデバイス、IoT機器、ウェアラブルデバイスなどのリソース制約環境においても、大規模モデルに匹敵する圧縮性能を実現することが課題である。具体的には、メモリ使用量を数GB以下に抑えつつ、CPU/GPUの処理能力を効率的に活用し、バッテリー消費を最小限に抑える軽量な圧縮システムが求められている。例えば、スマートフォンでは2GB以下のメモリ使用量、1秒あたり10MB以上の圧縮処理速度、1時間あたり5パーセント以下のバッテリー消費という制約条件を満たす必要がある。
2. マルチモーダルデータ間の相互関係を活用した、より高度な圧縮手法の確立
テキスト、画像、音声、動画などの異なるモダリティ間の相互関係を理解し、その理解に基づいて圧縮率を向上させる手法の開発が課題である。例えば、プレゼンテーションファイルにおけるスライド画像とナレーション音声の間の意味的対応関係、ウェブページにおけるテキストと画像の補完関係、動画における映像トラックと音声トラックの同期関係などを活用した圧縮が求められている。これにより、各モダリティを独立に圧縮する場合と比較して、15-30パーセント以上の圧縮率向上を目指す。
3. 通信環境やデータ特性に応じて最適な圧縮戦略を動的に選択する適応型圧縮フレームワークの構築
帯域幅、遅延、パケットロス率などの通信パラメータや、データの複雑さ、構造的特徴、予測可能性などのデータ特性に応じて、最適な圧縮モデルと圧縮パラメータを動的に選択するフレームワークの開発が課題である。例えば、高帯域幅環境では圧縮率を最大化するモデルを、低帯域幅環境では処理速度を優先するモデルを選択するなど、状況に応じた適応的な切り替えが求められている。また、バッテリー残量やCPU/GPU負荷などの端末状態も考慮した最適化が必要である。
4. 複数端末間での協調的圧縮による通信効率の最大化
送信側と受信側が共有知識を活用して協調的に圧縮・展開を行うことで、通信効率を最大化する手法の開発が課題である。具体的には、両端末が共通のドメイン知識を持つ場合、その知識から推論可能な情報は省略し、差分情報のみを伝送することで、通信オーバーヘッドを最小化する技術が求められている。また、継続的な通信セッションにおいては、過去の通信内容に基づく共有コンテキストを構築し、そのコンテキストを活用した圧縮を実現することも課題である。
5. 大規模モデルの圧縮能力を軽量モデルに効率的に転送する知識蒸留技術の確立
大規模モデル(iGPT、LLaMA3など)の圧縮能力を、パラメータ数が1/10から1/100の軽量モデルに効率的に蒸留する技術の開発が課題である。具体的には、大規模モデルの予測分布を教師信号として軽量モデルを訓練し、予測分布の近似精度を最大化する手法や、特定ドメインに特化した知識蒸留によりドメイン特化型の軽量モデルを構築する技術が求められている。
6. プライバシーとセキュリティを考慮した安全な圧縮システムの実現
個人情報や機密情報を含むデータの圧縮において、プライバシーとセキュリティを確保する技術の開発が課題である。具体的には、端末内処理によるプライバシー保護、差分プライバシーに基づく安全な知識共有、暗号化と圧縮の効率的な統合などが求められている。特に、医療データや金融データなどの機密性の高い情報を扱う場合には、データの機密性を維持しつつ高効率な圧縮を実現することが重要である。
これらの課題を総合的に解決することで、次世代通信技術(6G等)に対応する超高効率なデータ転送システムの基盤技術を確立することを目指す。
【課題を解決するための手段】
【0010】
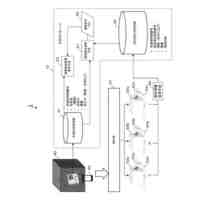
本発明は、「マルチモーダル理解に基づく適応型分散圧縮システム」を提案する。本システムは、LMCompressの基本概念である「理解に基づく圧縮」を拡張し、分散環境における協調的理解と適応的モデル選択を組み合わせることで、より効率的かつ柔軟なデータ圧縮を実現する。
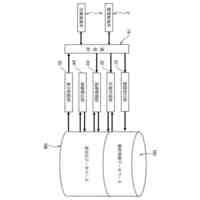
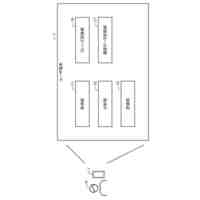
本システムは以下の主要コンポーネントから構成される。
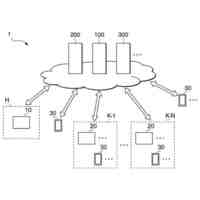
1. マルチモーダル理解モジュール:複数のデータ形式間の相互関係を理解・活用する
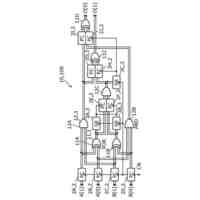
マルチモーダル理解モジュールは、異なるデータ形式(テキスト、画像、音声、動画など)間の相互関係を分析し、相互補完的な情報を抽出する。具体的には、クロスモーダル注意機構(Cross-Modal Attention)を用いて異なるモダリティ間の意味的対応関係をモデル化し、共有意味表現(Shared Semantic Representation)を構築する。
例えば、プレゼンテーションファイルの場合、スライド画像とナレーション音声の間の意味的対応関係を分析し、ナレーション音声から推論可能なスライド内容や、スライド画像から推論可能なナレーション内容を特定する。これにより、各モダリティを独立に圧縮する場合と比較して、冗長情報を効率的に削減できる。
また、マルチモーダル理解モジュールは、異なるモダリティ間の相互予測モデル(Cross-Modal Prediction Model)を構築する。このモデルは、あるモダリティの情報から他のモダリティの情報を予測することで、予測可能な部分の情報量を削減する。例えば、音声内容からスライド画像の一部を予測したり、映像フレームから音声の特徴を予測したりすることが可能になる。
2. 適応型モデル選択モジュール:データ特性と通信環境に応じて最適なモデルを選択する
適応型モデル選択モジュールは、データ特性(複雑さ、構造的特徴、予測可能性など)と通信環境(帯域幅、遅延、パケットロス率など)に基づいて、複数の圧縮モデルから最適なモデルを動的に選択する。具体的には、以下の機能を提供する。
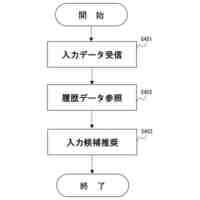
a) データ複雑性評価機能:エントロピー推定、構造的特徴抽出、予測可能性評価などの技術を用いて、データの複雑さを定量的に評価する。例えば、画像データの場合、エッジ密度やテクスチャ複雑性などの特徴を抽出し、複雑度スコアを算出する。
b) 通信環境監視機能:帯域幅測定、遅延推定、パケットロス検出などの技術を用いて、現在の通信環境を継続的に監視する。これにより、通信条件の変化に応じて圧縮戦略を動的に調整できる。
c) 端末状態監視機能:CPU/GPU使用率、メモリ使用量、バッテリー残量などの端末状態を監視し、リソース制約に応じた最適なモデル選択を行う。
d) モデル性能予測機能:各モデルの圧縮率、計算コスト、メモリ使用量などの性能指標を予測し、現在の状況に最適なモデルを選択する。この予測は、過去の実行データに基づく機械学習モデルによって行われる。
e) 最適モデル選択アルゴリズム:多目的最適化アルゴリズムを用いて、圧縮率、処理速度、リソース使用量などの複数の目標を考慮した最適なモデル選択を行う。例えば、帯域幅が限られた環境では圧縮率を重視し、バッテリー残量が少ない場合は処理効率を重視するなど、状況に応じた重み付けを行う。
3. 分散協調圧縮モジュール:複数端末間で協調的に圧縮処理を行う
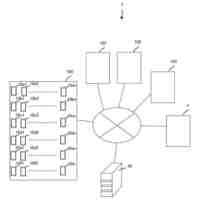
分散協調圧縮モジュールは、送信側と受信側の共有知識を活用して協調的な圧縮・展開を実現する。具体的には、以下の機能を提供する。
a) 共有知識管理機能:送信側と受信側で共有される知識ベース(ドメイン知識、過去の通信内容、一般的世界知識など)を管理する。この知識ベースは、分散キーバリューストアとして実装され、効率的なアクセスと更新が可能である。
b) 差分情報抽出機能:共有知識から推論可能な情報と差分情報を分離する。具体的には、送信データを共有知識に基づいて予測し、予測誤差(差分情報)のみを抽出する。この差分情報は、元のデータよりも大幅に小さいサイズとなる。
c) 協調的符号化機能:差分情報を効率的に符号化する。予測誤差の統計的特性に最適化された算術符号化やレンジ符号化などの技術を用いて、差分情報を高効率に圧縮する。
d) 知識同期機能:端末間の知識ベースを定期的に同期する。差分更新や増分学習などの技術を用いて、最小限の通信オーバーヘッドで知識ベースの一貫性を維持する。
e) コンテキスト構築機能:継続的な通信セッションにおいて、過去の通信内容に基づく共有コンテキストを構築する。このコンテキストは、短期記憶(直近の通信内容)と長期記憶(頻繁に出現するパターン)の階層的構造を持ち、効率的な圧縮の基盤となる。
4. 知識蒸留モジュール:大規模モデルの知識を軽量モデルに蒸留する
知識蒸留モジュールは、大規模モデル(iGPT、LLaMA3など)の圧縮能力を軽量モデルに効率的に転送する。具体的には、以下の機能を提供する。
a) 教師モデル選択機能:最高性能を持つ大規模モデルを教師モデルとして選択する。例えば、画像圧縮の場合はiGPT、テキスト圧縮の場合はLLaMA3などを選択する。
b) 生徒モデル設計機能:リソース制約に応じた軽量な生徒モデルを設計する。例えば、トランスフォーマーアーキテクチャの層数や隠れ層の次元を削減したり、量子化やプルーニングを適用したりすることで、モデルサイズを大幅に削減する。
c) 蒸留学習機能:教師モデルの予測分布を模倣するよう生徒モデルを訓練する。具体的には、教師モデルの出力する次トークン予測確率分布を教師信号として、生徒モデルのパラメータを最適化する。この際、知識蒸留損失(KL発散など)と直接予測損失(クロスエントロピーなど)を組み合わせた目的関数を用いる。
d) ドメイン適応機能:特定ドメインのデータに特化した知識蒸留を行う。例えば、医療ドメインのテキストデータや特定種類の画像データに特化した軽量モデルを構築することで、汎用モデルよりも高い圧縮性能を実現する。
e) 量子化・プルーニング機能:蒸留後の生徒モデルをさらに軽量化する。例えば、重みの量子化(32ビット浮動小数点から8ビット整数への変換など)やモデルプルーニング(重要度の低いパラメータの削除)を適用することで、モデルサイズと計算コストを削減する。
5. 適応型算術符号化モジュール:予測分布に基づいてデータを効率的に符号化する
適応型算術符号化モジュールは、生成モデルの出力する予測分布に基づいて、データを効率的に符号化する。具体的には、以下の機能を提供する。
a) 確率分布変換機能:モデルの出力する予測分布を算術符号化に適した形式に変換する。例えば、連続的な確率分布を離散化したり、低確率イベントを効率的に処理するための特殊処理を行ったりする。
b) 適応型符号化機能:データの特性に応じて符号化パラメータを動的に調整する。例えば、エントロピーの高い領域では精度を上げ、エントロピーの低い領域では計算効率を優先するなど、適応的な処理を行う。
c) 並列処理機能:大規模データの高速処理を実現するため、データを複数のチャンクに分割し、並列に符号化する。この際、チャンク間の依存関係を考慮した効率的な並列化アルゴリズムを用いる。
d) エラー耐性機能:通信エラーに対する耐性を持つ符号化を実現する。例えば、重要なデータ部分に冗長性を持たせたり、エラー検出・訂正コードを組み込んだりすることで、パケットロスや破損に対する堅牢性を確保する。
【発明の効果】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
裁判のAI化
17日前
個人
情報処理システム
24日前
個人
記入設定プラグイン
1か月前
個人
検査システム
26日前
個人
介護情報提供システム
3日前
個人
設計支援システム
9日前
個人
設計支援システム
9日前
株式会社サタケ
籾摺・調製設備
25日前
キヤノン電子株式会社
携帯装置
25日前
個人
不動産売買システム
1か月前
株式会社カクシン
支援装置
12日前
個人
備蓄品の管理方法
24日前
キヤノン株式会社
情報処理装置
25日前
キヤノン株式会社
情報処理装置
25日前
サクサ株式会社
中継装置
25日前
個人
ジェスチャーパッドのガイド部材
2日前
ホシデン株式会社
タッチ入力装置
1か月前
キヤノン電子株式会社
名刺管理システム
26日前
株式会社寺岡精工
システム
2日前
アスエネ株式会社
排水量管理方法
25日前
東洋電装株式会社
操作装置
25日前
株式会社東芝
電子機器
1か月前
株式会社ワコム
電子消去具
1か月前
東洋電装株式会社
操作装置
25日前
個人
パターン抽出方法及び通信多重化方法
1か月前
日本電気株式会社
システム及び方法
11日前
株式会社アザース
企業連携システム
3日前
株式会社JVCケンウッド
管理装置
26日前
株式会社CBE-A
情報処理システム
1か月前
大王製紙株式会社
RFIDタグ
1か月前
個人
会話評価装置
9日前
国立大学法人大阪大学
漏洩情報抑制回路
9日前
株式会社寺岡精工
顔認証システム
26日前
株式会社セラク
集出荷方法及びシステム
10日前
アスエネ株式会社
廃棄物排出量管理方法
25日前
個人
竹資源の生産・販売・分配システム
6日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ