TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025123172
公報種別
公開特許公報(A)
公開日
2025-08-22
出願番号
2024201507
出願日
2024-11-19
発明の名称
大規模言語モデルを用いたコード生成のための、言語サーバベースのコンテキスト提供
出願人
エスアーペー エスエー
代理人
個人
,
個人
,
個人
主分類
G06F
8/34 20180101AFI20250815BHJP(計算;計数)
要約
【課題】大規模言語モデルを用いたコード生成のための、言語サーバベースのコンテキスト提供を行うこと。
【解決手段】例示的な一実施形態では、統合開発環境(IDE)に接続された言語サーバを使用して、所与の入力コードから、関数、変数などさまざまなコードアーチファクトを識別し、次いで、それらの識別されたコードアーチファクトに関係のある宣言、定義、および参照があるかどうか、コードファイルのリポジトリを検索する。次いで、それらの宣言、定義、および参照を、コンテキストとしてLLMに渡すことができる。
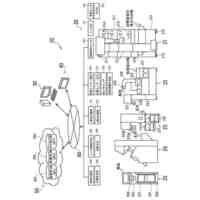
【選択図】図1
特許請求の範囲
【請求項1】
システムであって、
少なくとも1つのハードウェアプロセッサと、
命令を記憶する非有形のコンピュータ可読媒体とを備え、前記命令が、前記少なくとも1つのハードウェアプロセッサによって実行されると、前記少なくとも1つのハードウェアプロセッサに、
コンピュータコードをユーザの代わりに生成せよとの要求を受信することと、
前記受信することに応答して、前記ユーザによって現在編集されている第1のファイルを識別することと、
前記第1のファイルの識別情報を、前記第1のファイルをパースして前記第1のファイル内の1つまたは複数のアーチファクトを識別せよとのコマンドとともに、言語サーバに送信することと、
識別された1つまたは複数のアーチファクトの一覧を、前記言語サーバから受信することと、
コードリポジトリ内に格納されており、前記識別された1つまたは複数のアーチファクトに関連のある、1つまたは複数のコードスニペットを特定せよとのコマンドを、前記言語サーバに送信することと、
前記識別された1つまたは複数のアーチファクトに関連のある前記1つまたは複数のコードスニペットの識別情報を、前記言語サーバから受信することと、
大規模言語モデル(A large language model: LLM)に対するプロンプトを生成することであって、前記プロンプトが、前記識別された1つまたは複数のアーチファクトをコンテキストとして使用することに基づいてコードを生成せよとの命令を含む、生成することと、
前記プロンプトを前記LLMに送出することと、および
前記LLMから、生成されたコンパイル可能コードを受信することと
を含む動作を実施させる、システム。
続きを表示(約 1,600 文字)
【請求項2】
前記要求を受信することが、前記ユーザが現在対話しているグラフィカルユーザインターフェースから指令を受け取ることであって、前記指令が前記ユーザからの明示的な要求に基づいて生成される、受け取ることを含む、請求項1に記載のシステム。
【請求項3】
前記要求を受信することが、前記ユーザが現在対話しているグラフィカルユーザインターフェースから指令を受け取ることであって、前記指令が前記ユーザからの明示的な要求なく生成される、受け取ることを含む、請求項1に記載のシステム。
【請求項4】
前記動作が、前記要求を受信することに応答して、
前記第1のファイルの前記編集についてのコンテキスト情報を識別すること
をさらに含み、
識別情報を前記言語サーバに前記送信することが、前記第1のファイルの前記編集についての前記コンテキスト情報を前記言語サーバに送信することをさらに含む、
請求項1に記載のシステム。
【請求項5】
前記コンテキスト情報が、前記ユーザによって操作されているグラフィカルユーザインターフェース内に表示された、前記第1のファイル内のカーソルのロケーションを含む、請求項4に記載のシステム。
【請求項6】
前記識別された1つまたは複数のアーチファクトに関連のある前記1つまたは複数のコードスニペットの前記識別情報が、前記コンテキスト情報に基づき関連のあるコードスニペットの識別情報のみに限定される、請求項4に記載のシステム。
【請求項7】
前記1つまたは複数のコードスニペットのうちの少なくとも1つが、現在閉じられているファイル内に含まれる、請求項1に記載のシステム。
【請求項8】
方法であって、
コンピュータコードをユーザの代わりに生成せよとの要求を受信するステップと、
前記受信するステップに応答して、前記ユーザによって現在編集されている第1のファイルを識別するステップと、
前記第1のファイルの識別情報を、前記第1のファイルをパースして前記第1のファイル内の1つまたは複数のアーチファクトを識別せよとのコマンドとともに、言語サーバに送信するステップと、
識別された1つまたは複数のアーチファクトの一覧を、前記言語サーバから受信するステップと、
コードリポジトリ内に格納されており、前記識別された1つまたは複数のアーチファクトに関連のある、1つまたは複数のコードスニペットを特定せよとのコマンドを、前記言語サーバに送信するステップと、
前記識別された1つまたは複数のアーチファクトに関連のある前記1つまたは複数のコードスニペットの識別情報を、前記言語サーバから受信するステップと、
大規模言語モデル(A large language model: LLM)に対するプロンプトを生成するステップであって、前記プロンプトが、前記識別された1つまたは複数のアーチファクトをコンテキストとして使用することに基づいてコードを生成せよとの命令を含む、ステップと、
前記プロンプトを前記LLMに送出するステップと、
前記LLMから、生成されたコンパイル可能コードを受信するステップと
を含む、方法。
【請求項9】
前記要求を受信するステップが、前記ユーザが現在対話しているグラフィカルユーザインターフェースから指令を受け取るステップであって、前記指令が前記ユーザからの明示的な要求に基づいて生成される、ステップを含む、請求項8に記載の方法。
【請求項10】
前記要求を受信するステップが、前記ユーザが現在対話しているグラフィカルユーザインターフェースから指令を受け取るステップであって、前記指令が前記ユーザからの明示的な要求なく生成される、ステップを含む、請求項8に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本書は一般に、コンピュータシステムに関する。より詳細には、本書は、大規模言語モデルの使用に関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
大規模言語モデル(A large language model: LLM)とは、人間の言語を理解し生成するように大量のデータセットに対してトレーニングされた人工知能(AI)システムを指す。これらのモデルは、モデルが質問に答え、会話し、テキストを生成し、さまざまな言語関連のタスクを実施することのできるような形で、自然言語を処理し理解するように設計される。
【発明の概要】
【課題を解決するための手段】
【0003】
本開示は、同様の参照符号が類似の要素を示す添付の図面の図中に、限定ではなく例として示されている。
【図面の簡単な説明】
【0004】
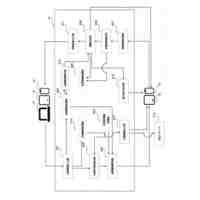
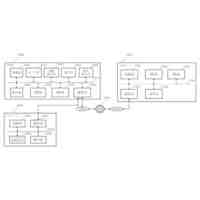
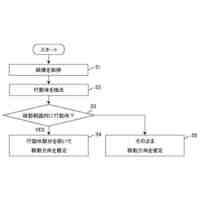
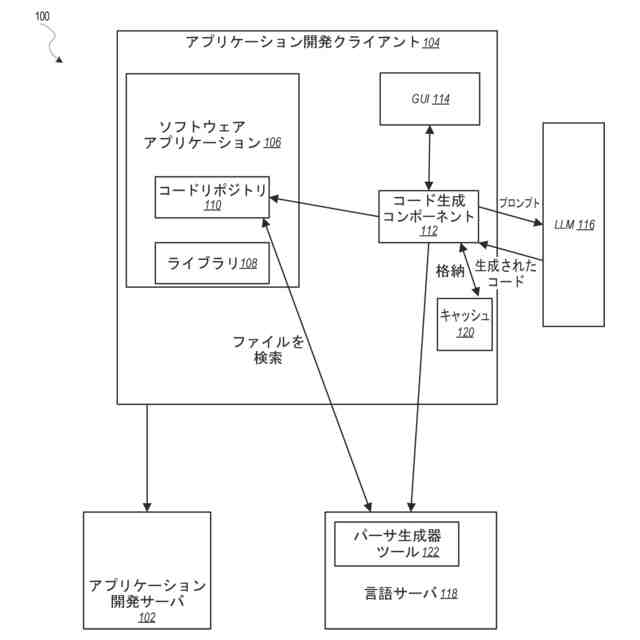
例示的な一実施形態による、コンピュータコードを自動的に生成するためのシステムを示すブロック図である。
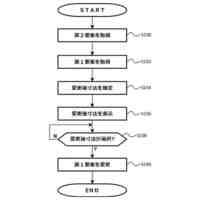
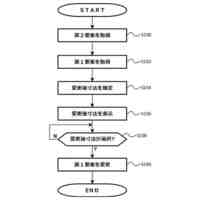
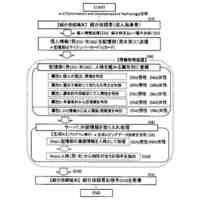
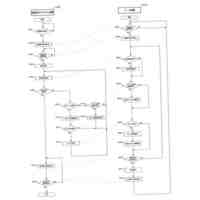
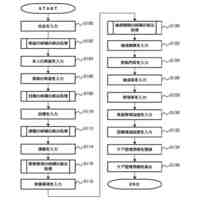
例示的な一実施形態による、コンピュータコードを自動的に生成するための方法を示すフロー図である。
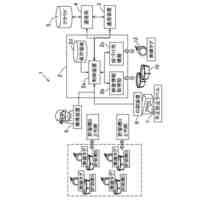
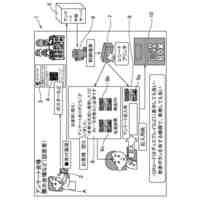
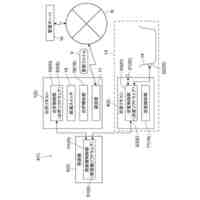
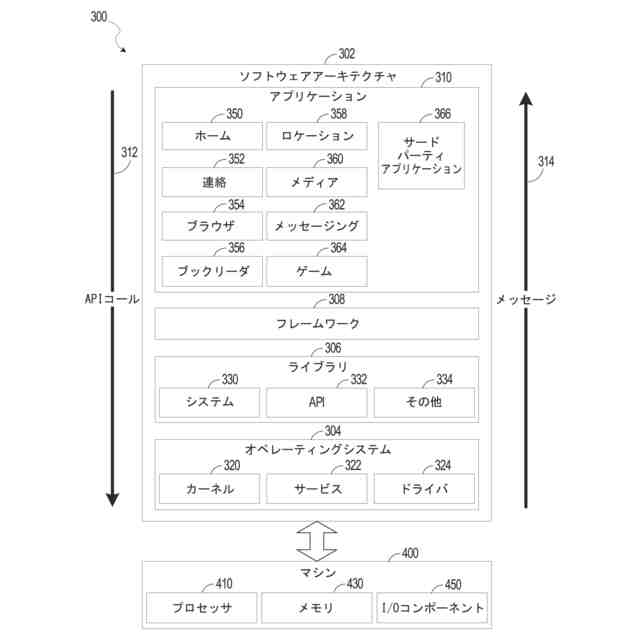
上述したデバイスのうちのいずれか1つまたは複数上にインストールすることのできるソフトウェアのアーキテクチャを示すブロック図である。
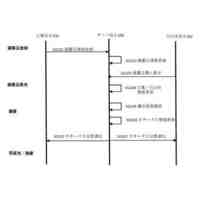
例示的な一実施形態による、コンピュータシステムの形態をとるマシンであって、本明細書において論じる方法のうちのいずれか1つまたは複数をマシンに実施させるための命令のセットがその中で実行されることの可能な、マシンの概略図である。
【発明を実施するための形態】
【0005】
次に続く説明では、例示的なシステム、方法、技法、命令シーケンス、およびコンピューティングマシンプログラム製品について論じる。以下の説明では、説明を目的として、本主題のさまざまな例示的な実施形態の理解をもたらすために多数の具体的詳細が記載される。しかし、これらの具体的詳細なしでも本主題のさまざまな例示的な実施形態を実践できることが、当業者には明白となろう。
【0006】
LLMは、テキスト、さらには(実行用のソフトウェアにコンパイルされる)コンピュータコードをも、生成する能力が高い。しかし、LLMの既存の知識がLLMのトレーニングデータによって制限されるため、LLMには制限がある。その結果、出力が常に正しいとは限らない。適切なシステムメッセージを作成すること、生成された関数呼び出しを通じて外部データを追加すること、または基盤モデルをファインチューニングすることなどによってこの制限の影響を低減させる方法があるが、これらの解決策は、完全ではなく、引き続き誤った出力をもたらす。これらの制限は、出力の中身が正しいことが重要となるのみならず、文法およびフォーマッティングが正しいことも重要となるコンパイル可能コンピュータコードをLLMが出力しているときに、増幅される。
【0007】
実際のところ、特定のタイプのコンパイル可能コンピュータコードは、コンパイル可能コンピュータコードのタイプが、プロプライエタリまたは少なくとも部分的にプロプライエタリなものである(したがってLLMをそれに対してトレーニングすることが困難なフォーマットである)ことや、コンパイル可能コンピュータコードのタイプが、生成された後で変更することが困難なものであることなど、いくつかの要因のため、LLMにとって正しく生成することがさらにいっそう困難なことがある。
【0008】
LLMをコード生成に使用することに関与する最大の技術的課題の1つが、正しいコンテキストを提供することである。LLMは、生成要求そのもの(例えば「Xをするための何らかのコードを私に生成してください」)を提供されているときのみならず、新規に生成されたコードが配置されるべきコードのロケーションや、重要な定義を有する関連ファイルなど、何らかのコンテキスト情報を提供されているときにも、より良好に機能する。LLMが要求のためのコンテキストを得れば得るほど、コード生成の信頼性が良好になる。仮に、アプリケーション全体分のコード内のあらゆるコードスニペットがLLMに提供されるなら、結果として得られる生成されたコードは、非常に信頼性の高いものとなる。
【0009】
問題は、LLMには典型的に、要求とともに提供することのできるコンテキストの数の制限(例えば入力トークンの最大数)があり、そのような制限が存在しない、または制限に完全には達していない場合でさえ、追加のコンテキストを追加することにより、(例えば金銭の点または速度の点で)推論コストが増す、ということである。したがって、要求のための関連のあるコンテキストをLLMに提供することは重要であるが、関連のないコンテキストを提供しないことも重要である。しかし、関連のあるコンテキストを識別することは、技術的に困難となり得る。
【0010】
1つの解決策は、開いた全てのファイルを識別し、次いで、開いた全てのファイルの(例えばジャッカード距離を使用して)現在の周囲コードと最も近いスニペットを送出する、というものである。しかし、この方法は、関連のあるファイルが開かれていない場合、失敗することになる。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
裁判のAI化
1か月前
個人
工程設計支援装置
9日前
個人
フラワーコートA
17日前
個人
情報処理システム
1か月前
個人
検査システム
1か月前
個人
介護情報提供システム
24日前
個人
設計支援システム
1か月前
個人
携帯情報端末装置
10日前
個人
設計支援システム
1か月前
株式会社サタケ
籾摺・調製設備
1か月前
キヤノン電子株式会社
携帯装置
1か月前
個人
不動産売買システム
1か月前
個人
結婚相手紹介支援システム
6日前
株式会社カクシン
支援装置
1か月前
個人
アンケート支援システム
19日前
個人
備蓄品の管理方法
1か月前
個人
ジェスチャーパッドのガイド部材
23日前
キヤノン株式会社
情報処理装置
1か月前
サクサ株式会社
中継装置
20日前
キヤノン株式会社
情報処理装置
1か月前
サクサ株式会社
中継装置
1か月前
大阪瓦斯株式会社
住宅設備機器
3日前
株式会社ワコム
電子消去具
1か月前
東洋電装株式会社
操作装置
1か月前
東洋電装株式会社
操作装置
1か月前
ホシデン株式会社
タッチ入力装置
1か月前
株式会社村田製作所
ラック
5日前
キヤノン電子株式会社
名刺管理システム
1か月前
アスエネ株式会社
排水量管理方法
1か月前
株式会社東芝
電子機器
1か月前
株式会社アジラ
移動方向推定装置
18日前
株式会社寺岡精工
システム
23日前
個人
リテールレボリューションAIタグ
16日前
株式会社アザース
企業連携システム
24日前
飛鳥興産株式会社
物品買取システム
12日前
株式会社ゼロワン
ケア支援システム
9日前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ