TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025127413
公報種別
公開特許公報(A)
公開日
2025-09-01
出願番号
2024037628
出願日
2024-02-20
発明の名称
発話終端検出を不要とする音声対話システム、Webサイト埋め込み型音声対話Q&Aシステム
出願人
ThinkX株式会社
代理人
主分類
G10L
15/28 20130101AFI20250825BHJP(楽器;音響)
要約
【課題】発話終端検出(EOU)処理に伴う遅延がゼロとなり、全体の応答速度が大幅に改善される音声対話システム及び音声対話QAシステムを提供する。
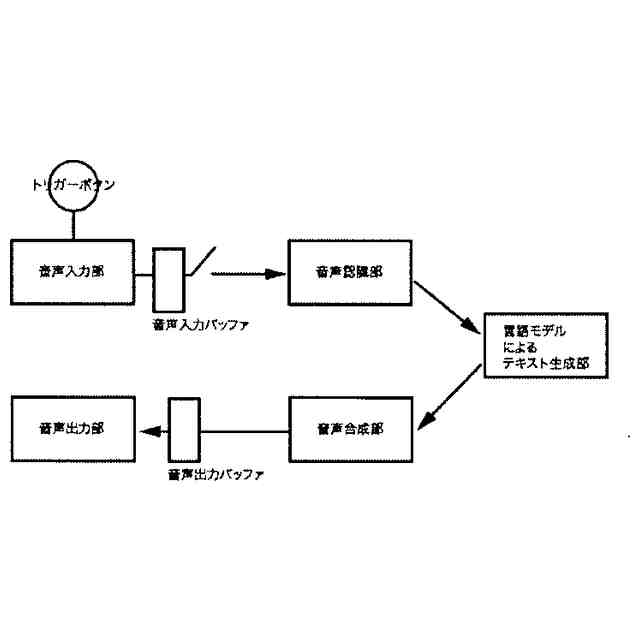
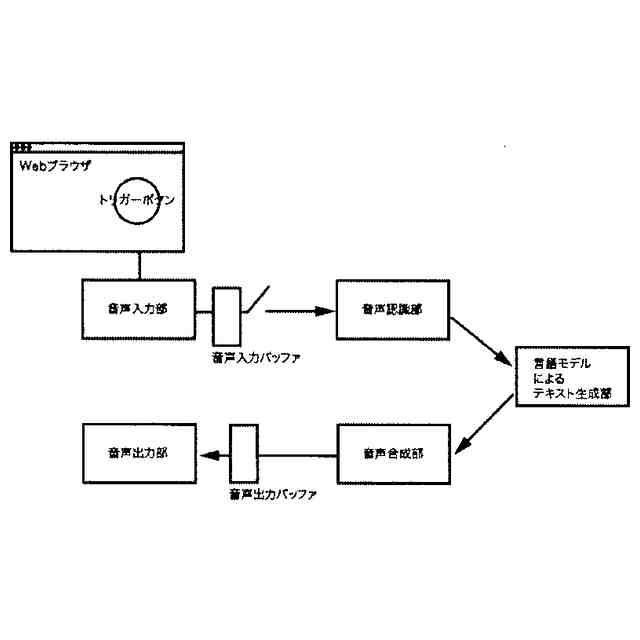
【解決手段】音声入力部、音声入力バッファ、発話終端検出部、音声認識部、言語モデルによるテキスト生成部、音声合成部、音声出力部、を有する一般的な音声対話システムから、発話終端検出部を取り除き、代わりに音声信号入力中であることを能動的に示すトリガーボタンを追加する。このトリガーボタンを押している間、音声入力信号を音声入力バッファに保持し、離した時点で音声信号を音声認識部に転送する。
【選択図】図1b
特許請求の範囲
【請求項1】
計算機端末上で動作する音声対話システムにおいて、
音声入力部、音声入力バッファ、音声認識部、言語モデルによるテキスト生成部、音声合成部、音声出力部、トリガーボタンの各部を有し、
前記音声入力部から入力された音声は前記音声バッファに蓄積されたのち前記音声認識部でテキストに変換され、その入力テキストへの応答テキストを前記テキスト生成部が出力した後、応答テキストは前記音声合成部で音声信号に変換され、音声信号が音声出力部から物理的音波として出力される音声対話システムについて、
前記トリガーボタンを押している間音声信号を前記音声入力バッファに入力し、トリガーボタンを離すや、それまで蓄積された音声信号が音声認識部に送られ、以降の処理が実行されることで、
発話終端検出(End of Utterance)処理を不要とし、発話終端検出処理に伴う遅延をゼロにすることで、高速な応答を実現すること、
を特徴とする音声対話システム。
続きを表示(約 170 文字)
【請求項2】
請求項1に記載の音声対話システムにより、
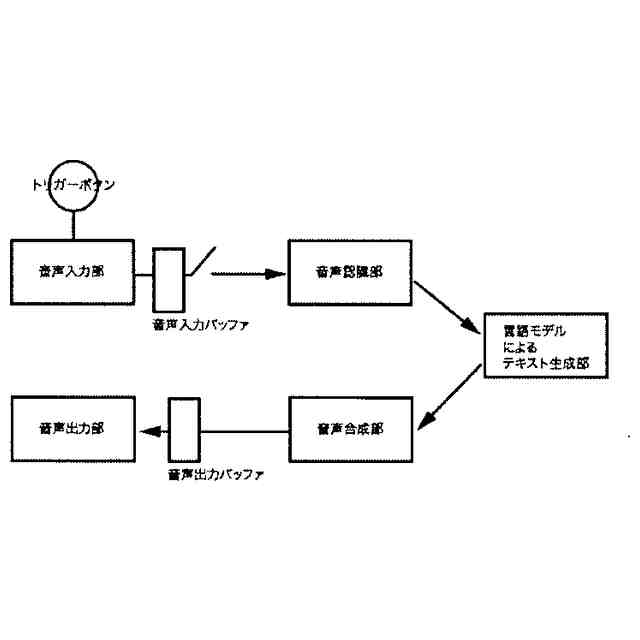
Webブラウザ上で動作するHTML要素を用いて請求項1に記載のトリガーボタンを構成し、このトリガーボタンを任意のWebサイト上に設置することで、当該Webサイトにオペレーターとしての音声対話機能を設けることのできる、
Webサイト埋め込み型音声対話Q&Aシステム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識モデル、音声合成モデル、および言語モデルを含む機械学習モデルを用いた音声対話システムに関する。
続きを表示(約 3,800 文字)
【背景技術】
【0002】
音声対話システムのパイプラインを改善する方法がこれまで様々に検討されてきた。高精度の音声認識と複雑な返答内容テキストの生成、および高品質な合成音声を組み合わせつつ、応答までのレイテンシーを短縮しリアルタイム性能を向上することが動機である。
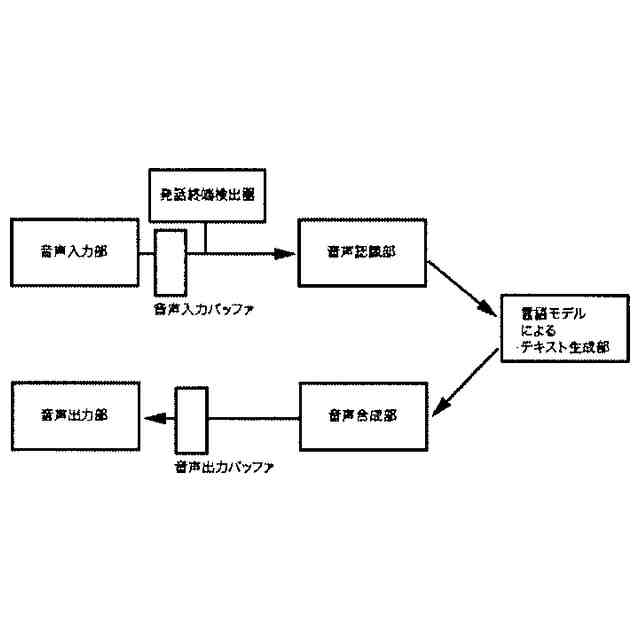
【0003】
例えばホームスピーカー製品に内蔵される音声対話システムでは話者が屋内空間を自由に移動しながらシステムに音声入力を行うため、システムは音声入力それ自体の情報を用いて発話終端を検出する必要がある。発話終端検出(EOU)処理は原始的には無音区間をカウントし、その持続時間が閾値を超えたとき終端と判断する方法から始まり、より近年では基本周波数F0を中心とする音韻情報や音声認識から得られた発話内容を入力する機械学習モデルを訓練することで検出性能を向上させる方法がある。
非特許文献1では、ASR仮説埋め込みと音響埋め込みを比較し、音響埋め込みによる音韻情報が最もモデルの性能に寄与することを示している。
非特許文献2では、音声とテキストによるマルチモーダルモデルを訓練することで、とりわけユーザー状態検出機能により発話終了や割り込み可能状態を意思決定するターンテイキング能力を構築している。
一方で、どのような方法でも実際の発話終了から終端が検出されるまでに一定の遅延時間を避けることができない。音響情報を用いた最先端の手法によっても0.5秒前後の遅延が発話終端検出のために必要とされた。これは多層的なパイプラインで構成される音声対話システム全体で多くを占め、リアルタイム性を損なう制約要因であった。
【先行技術文献】
【非特許文献】
【0004】
「Maas,Roland,et al.“Combining acoustic embeddings and decoding features for end-of-utterance detection in real-time far-field speech recognition systems.”2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).IEEE,2018」
「Lin,Ting-En,et al.“Duplex conversation:Towards human-like interaction in spoken dialogue systems.”Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.2022.」
【発明の概要】
【発明が解決しようとする課題】
【0005】
近年、Amazon AlexaやGoogle Homeをはじめとする音声対話システムの応答速度を改善するため、特に韻律情報を入力とする機械学習モデルによる発話終端検出(EOU)が用いられたが、このユニット単独で0.5秒前後の遅延増加が避けられず、音声入力から応答までのレイテンシは1秒以上を要した。人間同士の音声対話の応答速度は通常1秒未満であるため、常時1秒以上応答までに要する対話システムは対人間との音声対話体験のような快適さを感じられず、無意識にストレスや抵抗を感じざるを得なかった。
したがって、音声の入出力をインターフェースとするインタラクティブシステムが本格的に社会実装されるにはこの応答速度の問題を解決する必要があった。
【課題を解決するための手段】
【0006】
本発明の計算機端末上で動作する音声対話システムは、
音声入力部、音声入力バッファ、音声認識部、言語モデルによるテキスト生成部、音声合成部、音声出力部、に加えて、音声信号入力中に押下するトリガーボタンを設ける。このトリガーボタンを押している間音声入力信号を音声入力バッファに保持し、トリガーボタンを離すや、それまで保持された音声信号が音声認識部に送られ、以降の処理が実行されることで、発話終端検出(EOU)処理に伴う遅延がゼロとなり、全体の応答速度は音声認識部、言語モデル、音声合成部、音声出力部、およびデータ転送や圧縮エンコードおよびデコードなどにかかるオーバーヘッド等の遅延の合計となる。
【発明の効果】
【0007】
本発明では、機械学習モデルを主に用いる音声対話システムの全体の遅延を構成する、音声入力、発話終端検出(EOU)、音声認識、言語モデルによるテキスト生成、音声合成、音声出力、およびデータ転送や圧縮エンコードおよびデコードなどにかかるオーバーヘッド、のパイプラインのうち、発話終端検出処理にかかる遅延をゼロにする。
発話終端検出が占める割合はこの中でも30%~50%前後に達することがあり、これを削減することで全体の遅延は大幅に短縮され、応答速度は大幅に向上する。例えば700億パラメーター規模の大規模言語モデルによるテキスト生成処理を挟んでも、各処理部の最適化や、各部を繋ぐネットワーキングと各処理部の並列化等を併せることで、全体の遅延を0.5秒以内に抑えることが可能となり、これによって音声対話システムのリアルタイム性能は人間同士の会話と同等の遅延レベルに達する。
【図面の簡単な説明】
【0008】
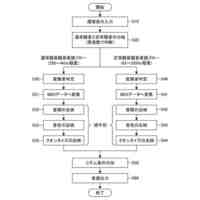
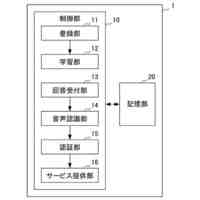
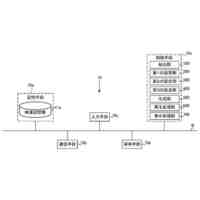
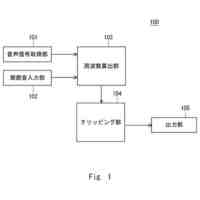
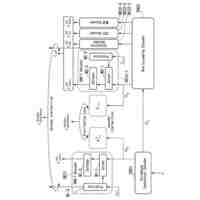
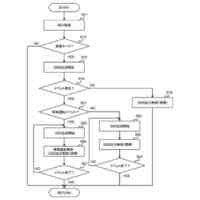
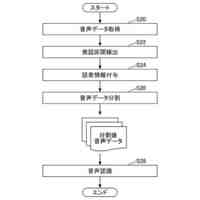
発話終端検出処理を含む、機械学習モデルを主に用いた従来の一般的な音声対話システムのパイプラインを図示した概念図である。
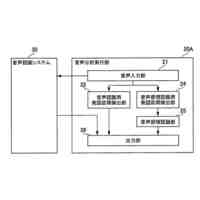
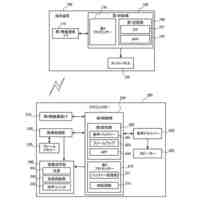
請求項1に記載された、本発明の音声対話システムを構成する全体のパイプラインを図示した概念図である。
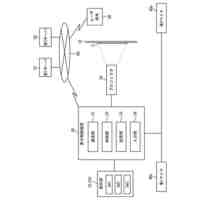
さらに請求項2に記載された、トリガーボタンがWebブラウザ上のHTML要素として実現されたWebサイト埋め込み型音声対話Q&Aシステム全体のパイプラインを図示した概念図である。
【発明を実施するための形態】
【0009】
本発明の音声対話システムは、計算機端末上で動作するものであり、先述した音声入力部から音声出力部までの各部を備えてさえいれば、そのいずれかの要素が異なる端末上に分散していても構わない。例えばインターネットを経由せずにローカル端末内のみで実現される音声対話システムは各部が単一の計算機端末に配置される。一方、クラウド方式の音声対話システムでは音声入力部と音声出力部のみがローカル端末上に配置され、それ以外はインターネットで接続されたサーバー端末上に配置されるか、あるいは音声認識部や音声合成部がローカル端末上に配置される場合もある。その組み合わせは任意であり、本発明にとってどのような組み合わせでも構わない。
【0010】
本発明の想定する、音声対話システムを構成する各部の役割を説明する。
音声入力部は一般にマイク機器を通じ物理的な空気中の振動を電気的信号に変換し、アナログ信号をデジタル方式の計算機端末であればPCMをはじめとする離散表現を用い変換し、さらにバイナリやWAV、mp3等の形式で計算機上のメモリ空間に格納することで音声情報を取り込む。音声入力部は物理的に発話された音声信号をメモリ空間に記録できるものであればどのようなものでも構わない。
音声入力バッファは連続入力される音声信号を次の処理部である音声認識部に転送されるまでの間保持する計算機端末上のメモリ領域である。
音声認識部は音声入力部で記録され音声入力バッファより転送される音声信号を入力し、その音声信号によって発話していると推測される自然言語表現をテキストデータで出力する。出力されるテキストデータはUnicodeやASCII文字列、サブワードトークンのインデックスの列など、どのようにエンコードされたものでも構わない。
言語モデルによるテキスト生成部は、音声認識部から出力されたテキストデータ、さらに必要に応じ任意の付随情報を加えた入力を受け付け、その入力に対応する応答内容または必要に応じて付随する情報をテキストデータで出力する。出力されるテキストデータの形式は音声認識部で説明したのと同様、どのようにエンコードされていても構わない。また応答内容に付随する情報がどのようであっても構わない。例えば画像などが付随されて出力されても構わない。
音声合成部は言語モデルが生成した応答内容としてのテキストデータを入力し、その読み上げ音声としての音声信号を出力する。出力される音声信号のデータ形式はバイナリやWAVまたは任意の圧縮形式でエンコードされた形式など、どのような形式であっても構わない。
音声出力部は音声合成部が出力する音声信号のデジタルデータをヒト聴覚で知覚可能な物理的振動に変換し、スピーカーやヘッドフォンなど任意の機器を通じ出力する。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
破裂爆発波動体感バルーン
1か月前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社豊田中央研究所
吸音構造体
1日前
川崎重工業株式会社
表面材
29日前
日本音響エンジニアリング株式会社
騒音低減装置
1か月前
株式会社イノアックコーポレーション
吸音材
20日前
株式会社フジタ
環境音快音化システム
1か月前
個人
歌唱技術表示装置および歌唱技術表示方法
1か月前
KDDI株式会社
認証装置、認証方法及び認証プログラム
20日前
株式会社第一興商
カラオケ装置
29日前
株式会社第一興商
カラオケ装置
21日前
株式会社第一興商
カラオケ装置
1日前
中原大學
能動騒音除去機能を持つレンジフード
1日前
個人
楽曲検索装置、楽曲検索方法、及び楽曲検索プログラム
1か月前
株式会社JVCケンウッド
クリッピング装置及びクリッピング方法
1日前
トヨタ自動車株式会社
電気自動車
21日前
宮澤フル-ト製造株式会社
タンポ及び木管楽器
1か月前
ローランド株式会社
打楽器および打面の形成方法
28日前
カシオ計算機株式会社
演奏装置、方法およびプログラム
1か月前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
ローランド株式会社
打楽器および取付部材の取付方法
28日前
株式会社SOKEN
吸音構造体
1か月前
株式会社日立製作所
音声分析システム及び音声分析方法
5日前
本田技研工業株式会社
音声認識装置、音声認識方法、及びプログラム
1日前
株式会社東芝
異常要因推定システム、方法及びプログラム
1か月前
公立大学法人広島市立大学
音質改善装置、音質改善方法及びプログラム
1か月前
株式会社リコー
音声認識装置、音声認識システム、音声認識方法及びプログラム
4日前
トヨタ自動車株式会社
車両制御方法及び車両制御装置
29日前
トヨタ自動車株式会社
音制御システム及び電気自動車
12日前
株式会社河合楽器製作所
ドロップアクションを有するピアノ
11日前
セイコーエプソン株式会社
音声出力方法、プロジェクター及びプログラム
1か月前
京セラ株式会社
表示システム、表示制御装置及び表示制御プログラム
20日前
京セラ株式会社
表示システム、表示制御装置及び表示制御プログラム
20日前
トヨタ自動車株式会社
車両管理システム及び電気自動車
1か月前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ