TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025122269
公報種別
公開特許公報(A)
公開日
2025-08-21
出願番号
2024017574
出願日
2024-02-08
発明の名称
画像センサ
出願人
株式会社キーエンス
代理人
弁理士法人前田特許事務所
主分類
G06T
7/00 20170101AFI20250814BHJP(計算;計数)
要約
【課題】文字認識のための学習済みモデルの性能を活かしつつ、ユーザによる学習が容易に行えるようにする。
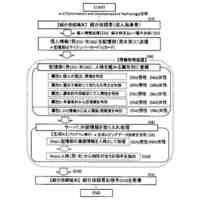
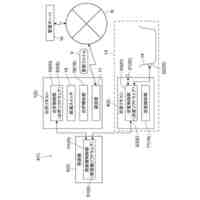
【解決手段】画像センサは、学習データ生成部及び学習実行部として機能する制御部と、第一文字種クラスのクラスごとに文字画像の特徴量を代表する文字種クラス代表特徴量を記憶する記憶部とを備えている。事前学習済みモデルは、特徴量抽出部と文字種出力部とを備えている。学習データ生成部は、画像領域データと指定文字種情報とを有する学習データを生成する。学習実行部は、学習データの画像領域データを指定された文字種である第二文字種に分類するように、学習データの画像領域データから抽出される特徴量に基づいて、第一文字種クラスの文字種クラス代表特徴量と異なる第二文字種クラスの文字種クラス代表特徴量を記憶部に記憶させる。
【選択図】図3
特許請求の範囲
【請求項1】
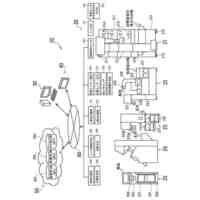
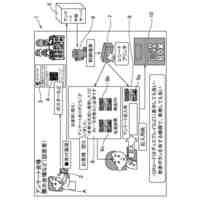
入力される画像データの画像中の一部である画像領域を、第一文字種クラスへ分類する、事前学習済みの文字認識モデルが実行され、文字認識結果に応じたセンサ出力をする画像センサであって、
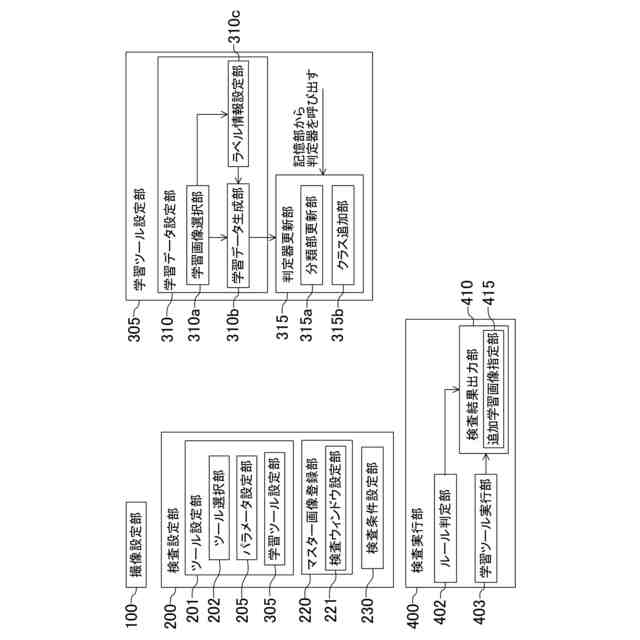
前記事前学習済みモデルを実行し、学習データを生成する学習データ生成部、及び前記学習データに基づく前記事前学習済みモデルの更新を実行する学習実行部、として機能する制御部と、
前記第一文字種クラスのクラスごとに、当該クラスに分類される文字画像の特徴量を代表する文字種クラス代表特徴量を記憶する記憶部と、を備え、
前記事前学習済みモデルは、
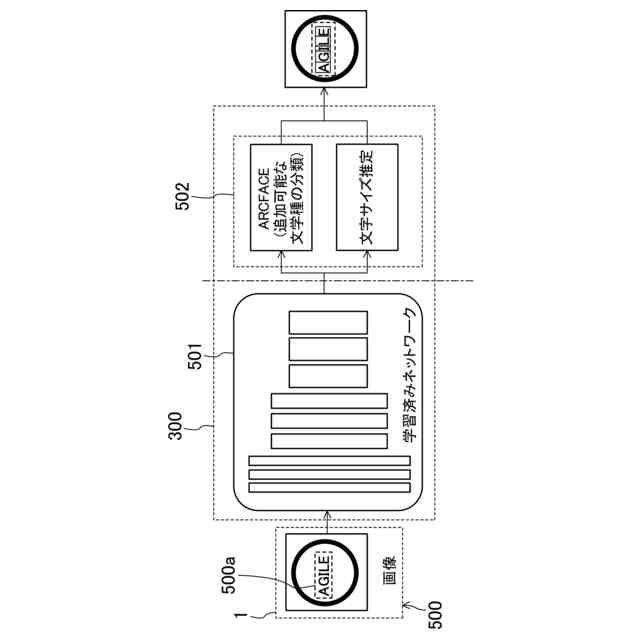
入力される前記画像データの前記画像領域から前記画像領域の特徴を示す特徴量として文字種クラスに係る特徴量を抽出する文字種クラス特徴量抽出部を含む特徴量抽出部と、
前記文字種クラス特徴量抽出部により抽出される前記特徴量と、前記記憶部の前記文字種クラス代表特徴量とに基づいて、前記画像領域の文字種を出力する文字種出力部と、を備え、
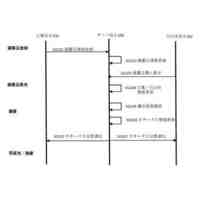
前記学習データ生成部は、画像領域データと、当該画像領域データに示される文字種を指定する指定文字種情報と、を有する学習データを生成し、
前記学習実行部は、前記学習データの前記画像領域データを前記指定された文字種である第二文字種に分類するように、前記学習データの前記画像領域データから抽出される前記特徴量に基づいて、前記第一文字種クラスの前記文字種クラス代表特徴量と異なる第二文字種クラスの前記文字種クラス代表特徴量を、前記記憶部に記憶させる、画像センサ。
続きを表示(約 1,400 文字)
【請求項2】
請求項1に記載の画像センサであって、
前記文字種出力部は、前記第一文字種クラスに分類される画像領域データに基づいて、距離学習の手法で事前学習される、画像センサ。
【請求項3】
請求項1に記載の画像センサにおいて、
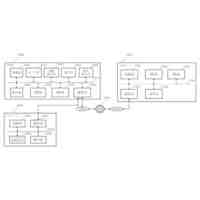
前記制御部は、前記特徴量抽出部としての畳み込みニューラルネットワークの演算を実行する畳み込み演算ネットワーク推論アクセラレータを有する、画像センサ。
【請求項4】
請求項1に記載の画像センサにおいて、
前記制御部により実行される前記事前学習済みモデルは、
前記画像領域のサイズに係る特徴量であるサイズ特徴量を抽出するサイズ特徴量抽出部と、
前記画像領域が前景か背景かを示す特徴量である前景特徴量を抽出する対象物特徴量抽出部と、
前記前景特徴量に基づいて、入力される前記画像データの文字画像領域の候補である候補領域の位置を特定する候補領域出力部と、
前記サイズ特徴量に基づいて、前記候補領域の重複を判定する重複判定部と、を有し、
前記制御部は、前記重複判定部により重複して検出されたと判定された前記候補領域の少なくとも一つを削除した文字認識結果に応じた、センサ出力をする、画像センサ。
【請求項5】
請求項4に記載の画像センサにおいて、
前記重複判定部は、前記文字種出力部により出力される前記文字種に基づいて、同一の文字画像領域に対応する候補領域の重複を判定する、画像センサ。
【請求項6】
請求項1に記載の画像センサにおいて、
前記事前学習済みモデルは、前記特徴量抽出部により抽出される前記特徴量に基づいて、入力される前記画像データの文字領域の候補である候補領域の位置を特定する候補領域出力部、を有し、
前記文字種出力部は、前記候補領域出力部により特定される前記画像領域の文字種を出力する、画像センサ。
【請求項7】
請求項1に記載の画像センサにおいて、
前記指定文字種情報により指定される文字種が、前記第一文字種クラスに対応する第一文字種である場合に、前記文字種出力部は前記第二文字種クラスに分類された前記画像領域データを前記指定された第一文字種として出力する、画像センサ。
【請求項8】
請求項1に記載の画像センサにおいて、
前記学習データ生成部は、前記指定文字種情報により指定される文字種の画像領域のサイズを示す指定サイズ情報、を有する学習データを生成し、
前記文字種出力部は、当該学習データに基づいて前記文字種クラス代表特徴量が決定された前記第二文字種クラスに分類された前記画像領域データのサイズを、指定サイズの画像領域として出力する、画像センサ。
【請求項9】
請求項1に記載の画像センサにおいて、
前記第二文字種クラスの前記文字種クラス代表特徴量は、前記第一文字種クラスの前記文字種クラス代表特徴量を記憶する領域とは別領域で不揮発な前記記憶部に記憶される、画像センサ。
【請求項10】
請求項1に記載の画像センサにおいて、
前記制御部は、前記第一の画像データに対して文字認識結果を出力し、前記文字認識結果がユーザによる視認結果と異なる画像データについて指定を受け付けることにより学習データを生成する、画像センサ。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
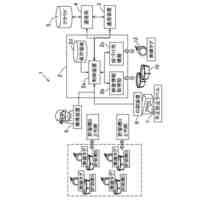
本開示は、文字認識のための分類タスクを実行する学習済みモデルの実行が可能な画像センサに関する。
続きを表示(約 2,600 文字)
【背景技術】
【0002】
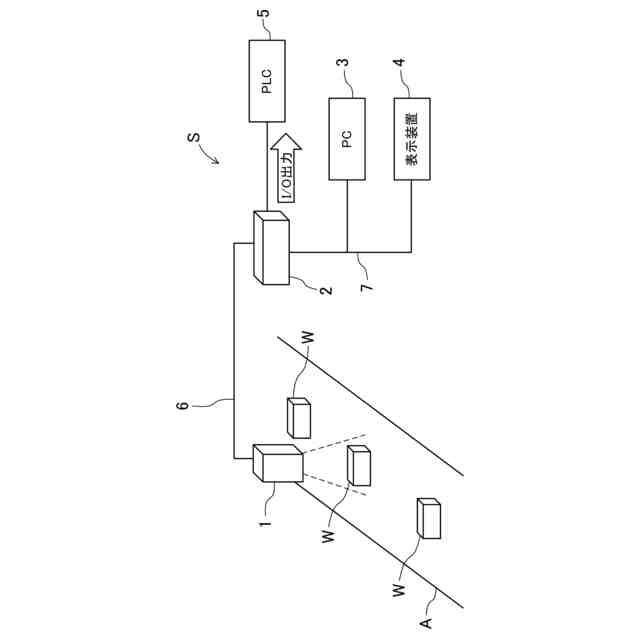
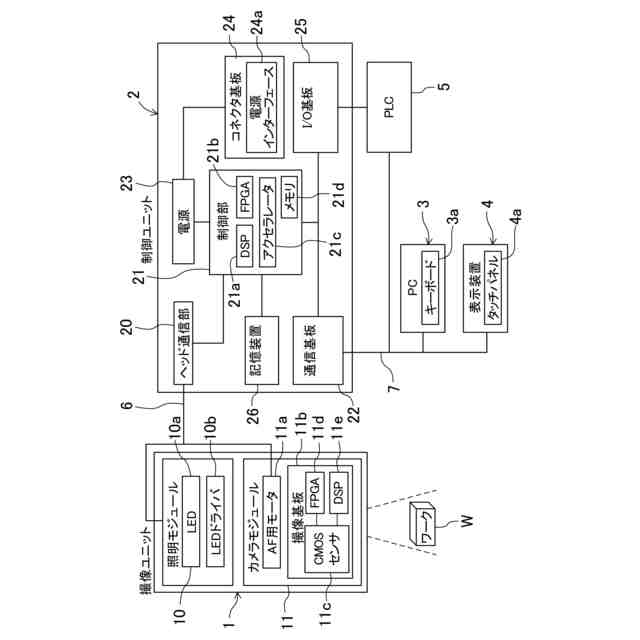
例えばFA業界では、人がワークを目視検査する工程を代替する画像検査装置が広く知られている。画像検査装置はワーク画像を撮像し、撮像した画像を一定の基準で判定する。画像検査装置が画像センサである場合は判定結果がI/O出力で例えばプログラマブルロジックコントローラ(PLC)等の外部機器に出力される。
【0003】
画像検査装置の判定に用いられる基準がある画像特徴によるものである場合、人による目視検査の検査結果には影響が及ばない程度の画像特徴の変化であっても、画像検査装置の判定結果に影響が及ぶ可能性がある。そこで、目視検査により近い判定結果を得るために、機械学習で得られる画像認識モデルを利用した画像検査装置として、例えば特許文献1に開示された画像検査装置が知られている。特許文献1の画像検査装置では、良品としての属性が付与された良品画像と、不良品としての属性が付与された不良品画像とを学習することによって良品画像と不良品画像を識別する識別器を生成し、運用時に新たに取得された画像を識別器に入力して良否判定を行うように構成されている。
【先行技術文献】
【特許文献】
【0004】
特開2020-187072号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
ところで、一般的に、機械学習で得られる画像認識モデルを作成するためには大量の画像データが必要であり、必要となる画像データを各ユーザが収集するのは困難であるか、もしくはユーザの負担が増大する。機械学習に必要な画像データの収集による負荷を低減する様々な方法が検討されているが、特許文献1の画像検査装置のように入力された画像の良否判定を行うモデルを作成する場合、検査したい対象物がユーザによって異なり、かつ、良品・不良品の基準も異なるため、ユーザが良品としての属性及び不良品としての属性を画像データのそれぞれに対して付与する作業が必要になり、運用前におけるユーザの負担がより一層増大することが考えられる。また、機械学習の手法でモデルを作成する場合に計算が高負荷であることも課題である。
【0006】
ところで、画像検査装置には、文字が付与されたワークの撮像画像の文字部分である文字画像を認識し、ワーク上の文字を特定して当該文字が判定基準に適合しているかどうかを、画像認識モデルで判定する文字認識(OCR)を備えた装置がある。文字は一般的にはユーザによらず認識結果が共通である。つまり、良否判定の判定基準はユーザによって異なるのに対して、OCRにおいて文字画像が何の文字の画像かを判定する基準はユーザによって異ならない。したがって、予め分類対象としての文字種を設定し、設定された文字種を認識できる識別器を提供することが可能である。この識別器は、文字画像が何の文字の画像かを判定する基準に代わるものと見なすことができる。このような事前学習済みモデルをユーザに提供することで、識別器運用前におけるユーザの負担を軽減できる。
【0007】
なお、本明細書においては、画像検査に係る商品を提供する事業者が当該商品をユーザに提供する前に、機械学習の手法でモデルを作成することを事前学習と呼び、事前学習により作成されたモデルを事前学習済みモデルと呼ぶ。また、画像検査に係る商品の提供を受けたユーザが学習データを提示して、機械学習を含む手法でモデルを作成・改変することを現場学習と呼ぶ。
【0008】
OCRは、ドキュメントスキャナの分野でも用いられているが、ドキュメントスキャナの分野では読み取り対象であるドキュメント上の文字列を認識することを目的にOCRが用いられる。このような目的においては、文字に対応する画像特徴だけでなく、文字に対応する文字列(文脈)特徴を学習した機械学習モデルを用いることで文字の認識精度を向上させるのが一般的である。
【0009】
一方、FA業界の画像検査におけるOCRで認識される文字は、例えば賞味期限の日付のように、前後の文脈によって変化しない文字列に含まれる文字である。また、ドキュメントスキャナに対してFA業界の画像検査ではOCRの認識精度に影響する外部環境の変化が大きい。ドキュメントスキャナの分野では、スキャナ台やオートフィーダー経路のような殆ど変動しない環境で画像読み取りをしているためOCRの認識精度に影響する外部環境の変化がかなり小さい。これに対して、FA業界の画像検査におけるOCRでは、時間経過やワーク種類の多様性によって周辺環境が変わる。したがって、ある文字種として認識するべき文字画像の種類は、文字画像中の文字の形状だけでなく、文字画像に影響を与える環境にも依存する。つまり、ドキュメントスキャナにおけるOCRと比較して、FA業界の画像検査におけるOCRでは、ある任意の文字種として認識されるべき、と考えられる文字画像の種類が、OCRが実行される外部環境に比例して多い一方、文字に対応する画像特徴以外の文字列特徴を用いた学習が適さない。このため、読み取り精度を向上するために大量の学習データや比較的計算量が大きい事前学習が必要で、かつ、事前学習だけで要求される文字認識精度に対応するのが困難で、ユーザによる追加の学習、すなわち現場学習を受け付ける必要がある。つまり、FA業界の画像検査におけるOCRは、識別の基準がユーザによらない物として存在しているが故に、現場学習を必要とせずにある程度の文字を認識することが求められる一方、文字認識精度の向上のために現場学習できることが求められる。
【0010】
現場学習できることへの要求の背景には、外部環境以外にFA現場における文字画像の扱いの特殊性がある。OCRの対象がドキュメントであるとき、ドキュメントは、ドキュメント自体が人から人に情報を伝達する手段であるため一般的な文字が用いられることが多い。しかしながら、FA業界では、一部のユーザが、一般的に使用されないような特殊文字を単なる記号として使用することがある。このように、事前学習済みモデルで分類可能な文字種として設定されていない文字種を認識させる場合には、当該文字種を新たな文字種として追加する必要がある。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
株式会社キーエンス
近接センサ
4日前
株式会社キーエンス
近接センサ
4日前
株式会社キーエンス
近接センサ
4日前
株式会社キーエンス
近接センサ
4日前
株式会社キーエンス
近接センサ
4日前
有限会社センテック
部品組付治具および部品組付支援装置
10日前
個人
裁判のAI化
1か月前
個人
情報処理システム
1か月前
個人
フラワーコートA
25日前
個人
工程設計支援装置
17日前
個人
検査システム
1か月前
個人
記入設定プラグイン
2か月前
個人
介護情報提供システム
1か月前
個人
携帯情報端末装置
18日前
個人
設計支援システム
1か月前
個人
設計支援システム
1か月前
個人
不動産売買システム
2か月前
個人
結婚相手紹介支援システム
14日前
株式会社サタケ
籾摺・調製設備
1か月前
キヤノン電子株式会社
携帯装置
1か月前
株式会社カクシン
支援装置
1か月前
株式会社アジラ
進入判定装置
3日前
個人
備蓄品の管理方法
1か月前
個人
パスポートレス入出国システム
3日前
個人
アンケート支援システム
27日前
サクサ株式会社
中継装置
28日前
サクサ株式会社
中継装置
1か月前
キヤノン株式会社
情報処理装置
1か月前
個人
食事受注会計処理システム
4日前
個人
ジェスチャーパッドのガイド部材
1か月前
大阪瓦斯株式会社
住宅設備機器
11日前
株式会社BONNOU
管理装置
2か月前
キヤノン株式会社
情報処理装置
1か月前
ホシデン株式会社
タッチ入力装置
2か月前
東洋電装株式会社
操作装置
1か月前
株式会社寺岡精工
システム
1か月前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ