TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024129003
公報種別
公開特許公報(A)
公開日
2024-09-26
出願番号
2024076527,2023522981
出願日
2024-05-09,2021-10-15
発明の名称
フィルタバンク領域でオーディオサンプルを処理するための生成ニューラルネットワークモデル
出願人
ドルビー・インターナショナル・アーベー
代理人
個人
,
個人
,
個人
主分類
G10L
25/30 20130101AFI20240918BHJP(楽器;音響)
要約
【課題】 本開示は、フィルタバンク領域でサンプルを処理するための生成ニューラルネットワークモデルに関する。
【解決手段】 オーディオ信号の複数の現在フィルタバンクサンプルの分布を自己回帰的に生成するための生成モデルを実装するニューラルネットワークシステムが提供され、現在サンプルは現在時間スロットに対応し、各現在サンプルはフィルタバンクのチャネルに対応する。システムには、最上位層から最下位層へと順序付けられた複数のニューラルネットワーク処理層の階層であって、各層は、以前のフィルタバンクサンプルに基づいて条件付け情報を生成するようにトレーニングされ、少なくとも最上位層を除く各層については、階層の上位層の条件付け情報に更に基づいてトレーニングされる、階層と、1つ以上の以前の時間スロットの以前のサンプルと最低処理層の条件付け情報に基づいて確率分布を生成するようにトレーニングされた出力段と、が含まれる。
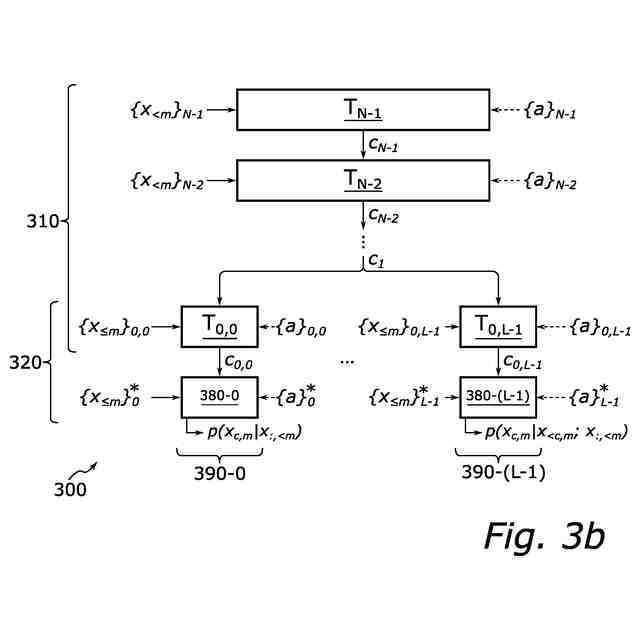
【選択図】 図3B
特許請求の範囲
【請求項1】
オーディオ信号のフィルタバンク表現のための複数の現在サンプル(x
m
)の確率分布を自己回帰的に生成するためのニューラルネットワークシステムであって、前記現在サンプルは現在時間スロット(m)に対応し、各現在サンプルはフィルタバンクの各々のチャネルに対応し、
最上位処理層(T
N-1
)から最下位処理層(T
0
)まで順序付けられた複数のニューラルネットワーク処理層(T
N-1
,T
N-2
,…,T
0
)の階層であって、各処理層(T
j
)は、前記フィルタバンク表現のための以前のサンプル(x
<m
)と、少なくとも最上位層を除く各処理層については、前記階層の上位の処理層(T
j+1
)によって生成された条件付け情報(c
j+1
)に更に基づいて、条件付け情報(c
j
)を生成するようにトレーニングされている、階層と、
前記フィルタバンク表現の1つ以上の以前の時間スロット(<m)に対応する以前のサンプル(x
<m
)と、最低処理層から生成された条件付け情報に基づいて確率分布を生成するようにトレーニングされた出力段であって、前記出力段は前記最下位処理層を含み、前記最下位処理層は複数の連続して実行されるサブレイヤに細分化され、各サブレイヤは前記フィルタバンクのチャネルの真部分集合に対応する1つ以上の現在サンプルの確率分布を生成するようにトレーニングされており、少なくとも最初に実行されたサブレイヤを除くすべてのサブレイヤについて、各サブレイヤは、1つ以上の以前に実行されたサブレイヤによって生成された現在サンプルに更に基づいて前記確率分布を生成するようにトレーニングされている、出力段と、
を含むシステム。
発明の詳細な説明
【技術分野】
【0001】
[関連出願]
本願は、以下の優先権出願:2020年10月16日に出願された米国仮出願63/092,754(参照番号:D20037USP1)及び2020年11月12日に出願された欧州出願20207272.4(参照番号:D20037EP)の優先権を主張する。
続きを表示(約 1,300 文字)
【0002】
[技術分野]
本開示は、機械学習とオーディオ信号処理の共通部分に関するものである。特に、本開示は、フィルタバンク領域でサンプルを処理するための生成ニューラルネットワークモデルに関するものである。
【背景技術】
【0003】
生成ニューラルネットワークモデルは、トレーニングデータセットの真の分布を少なくとも近似的に学習するようにトレーニングされる場合があり、そのような学習された分布からのサンプリングによってモデルが新しいデータを生成する可能性がある。このように、生成ニューラルネットワークモデルは、音声とオーディオの合成、オーディオコーディング及びオーディオ拡張の両方を含む様々な信号合成スキームで有用であることが証明されている。このような生成モデルは、時間領域又は信号の周波数表現の振幅スペクトル(すなわちスペクトログラム上で)のいずれかで動作することが知られている。
【0004】
しかし、時間領域で動作する生成モデル(WaveNetやsampleRNNなど)は、等化に使用されるツールなど、周波数領域インターフェースを持つ他の信号処理ツールとの統合を常に容易にするとは限らず、多くの場合、並列化の可能性が制限される場合のある回帰ネットワークを使用する。さらに、スペクトログラム(例えば、MelNet)で動作する最新の生成モデルは、合成中にオーディオ信号の位相を再構成せず、代わりに、オーディオを適切に再構成するために、後処理として位相再構成アルゴリズム(例えば、Griffin-Lim)に頼っている。
【0005】
上記を考慮して、オーディオ信号処理のための改善された生成モデルが必要である。
【発明の概要】
【0006】
本開示は、上記の特定されたニーズを少なくとも部分的に満足させようとするものである。
【0007】
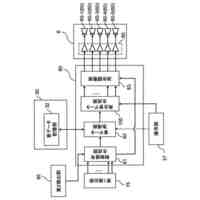
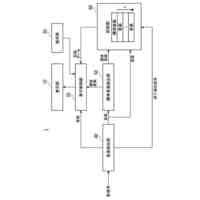
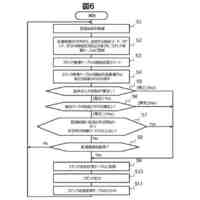
本開示の第1態様によれば、オーディオ信号のフィルタバンク表現について、複数の現在サンプルの確率分布を自己回帰的に生成するためのニューラルネットワークシステム(以下「システム」)が提供される。システムは、例えば、コンピュータ実装システムであってもよい。
【0008】
本開示に関する限り、現在サンプルは、現在時間スロットに対応し、各現在サンプルは、フィルタバンクの各々のチャネルに対応する。
【0009】
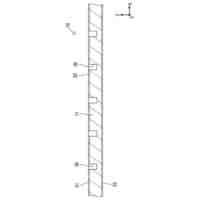
システムは、最上位層から最下位層に順序付けられた複数のニューラルネットワーク処理層(以下、「層」又は「tier」)の階層を含み、各層は、フィルタバンク表現のための以前のサンプルと、最上位層以外の少なくとも各処理層については、階層の上位の(例えば、層の階層の直上にある)処理層によって生成された条件付け情報に基づいて、条件付け情報を生成するようにトレーニングされている。
【0010】
システムはさらに、フィルタバンク表現のための1つ以上の以前の時間スロットに対応する以前のサンプルと、最低処理層から生成された条件付け情報に基づいて確率分布を生成するようにトレーニングされた出力段を含む。
(【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
この特許をJ-PlatPatで参照する
関連特許
株式会社トランストロン
軸構造
3日前
株式会社第一興商
カラオケ装置
21日前
学校法人幾徳学園
鍵盤楽器
7日前
株式会社今仙電機製作所
自動車用警報音発生装置
18日前
株式会社河合楽器製作所
鍵盤装置
21日前
株式会社河合楽器製作所
鍵盤装置
15日前
株式会社河合楽器製作所
鍵盤装置
15日前
日本製紙パピリア株式会社
表面材および吸音材
7日前
個人
アコースティック・ギター用単弦牽引装置のための台座
21日前
株式会社イノアックコーポレーション
防音構造
14日前
ヤマハ株式会社
情報処理方法
25日前
ヤマハ株式会社
動画処理方法
3日前
株式会社第一興商
カラオケ装置
22日前
株式会社第一興商
カラオケ装置
18日前
パナソニックIPマネジメント株式会社
個室ブース
1か月前
株式会社第一興商
カラオケ装置
1か月前
ヤマハ株式会社
管楽器及び管楽器用のキー
15日前
株式会社フューチャー・ブレイン
音声合成システム及び音声合成方法
1か月前
ヤマハ株式会社
鍵盤ユニット
15日前
日産自動車株式会社
音声認識方法及び音声認識装置
3日前
ローム株式会社
音声認証装置、および機器
今日
ヤマハ株式会社
音データ生成方法
8日前
株式会社イノアックコーポレーション
吸音材
24日前
ヤマハ株式会社
音源およびその制御方法、プログラム、電子鍵盤楽器
21日前
本田技研工業株式会社
対話理解装置、および対話理解方法
24日前
TOA株式会社
音源形成システム、音源形成プログラム、および音源形成方法
21日前
ピクシーダストテクノロジーズ株式会社
吸音部材及び吸音壁
1か月前
ヤマハ株式会社
音高表示装置、音高表示方法、およびプログラム
24日前
日本放送協会
解説音声制作装置、携帯端末及びプログラム
1か月前
花王株式会社
対話システム、対話プログラム、対話方法
29日前
株式会社NTTドコモ
音声書き起こしシステム及び音声翻訳システム
1か月前
国立研究開発法人情報通信研究機構
声質変換処理システム、および、声質変換処理方法
25日前
株式会社日立情報通信エンジニアリング
音声入力支援システム、音声入力支援方法
7日前
TOA株式会社
会話漏洩評価装置
1か月前
カシオ計算機株式会社
プログラム、情報処理装置及び画像生成方法
21日前
カシオ計算機株式会社
ペダル装置及び電子鍵盤楽器
9日前
続きを見る
他の特許を見る

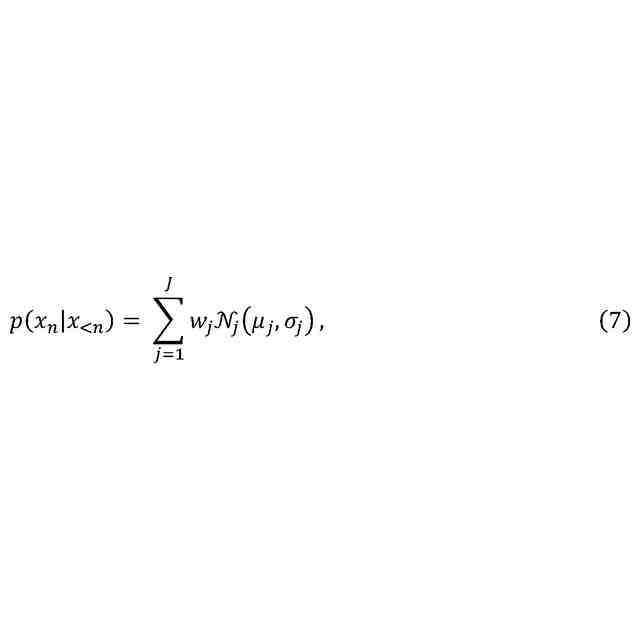
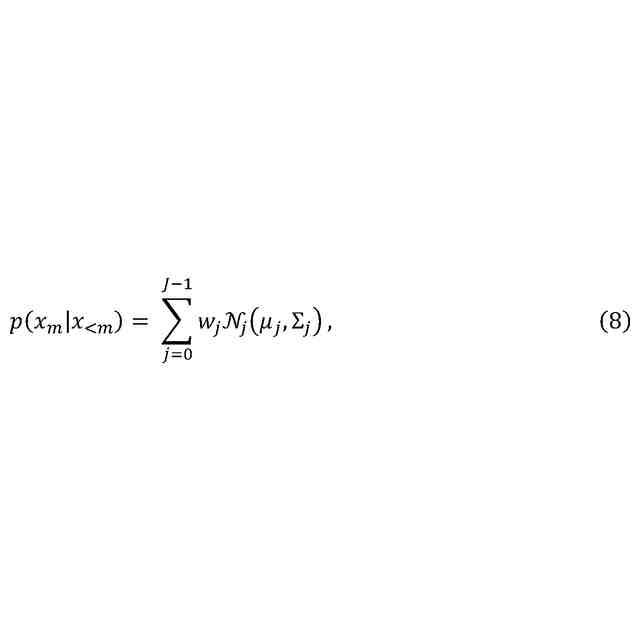
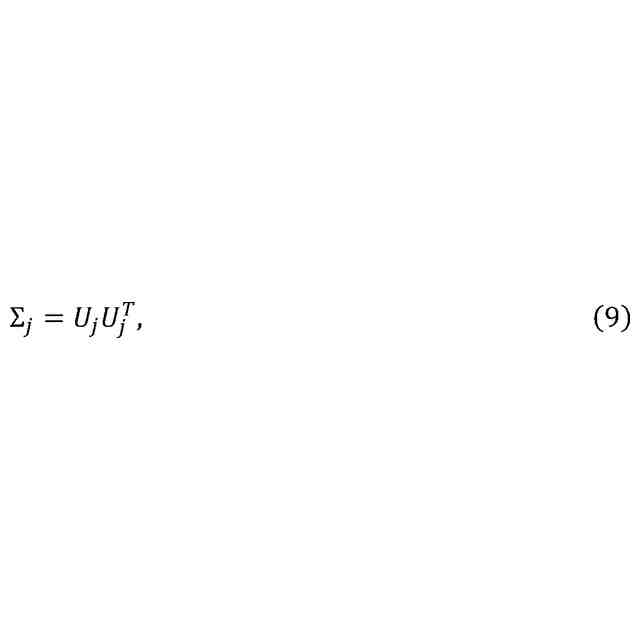
 特許ウォッチ
特許ウォッチ