TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2024075457
公報種別
公開特許公報(A)
公開日
2024-06-03
出願番号
2023023681
出願日
2023-02-17
発明の名称
音声認識モデルに用いる学習データを作成する学習データ作成装置及びプログラム
出願人
日本放送協会
代理人
個人
主分類
G10L
15/06 20130101AFI20240527BHJP(楽器;音響)
要約
【課題】テレビ放送番組における発話被りのある音声を高精度に認識するための学習データを作成する。
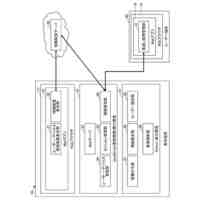
【解決手段】テレビ番組風発話被り作成手段12の音声ペア選択手段20は、音声ペアを選択し、音声データSD1,SD2及びこれらに対応するテキストデータを入力する。重ね合わせ音声作成手段22は、予め設定された発話被り時間の平均m及び分散vの正規分布に従って、被り時間Tをランダムに設定し、音声データSD1,SD2の末尾及び冒頭の部分が被り時間Tの発話被りにて重なるように、重ね合わせ音声データを作成する。トークン付きテキスト作成手段23は、重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含むトークン付きテキストデータを作成する。このようにして作成された重ね合わせ音声データ及びトークン付きテキストデータは、学習データとして用いられる。
【選択図】図4
特許請求の範囲
【請求項1】
テレビ放送番組の音声を認識するための音声認識モデルに用いる学習データを作成する学習データ作成装置において、
前記テレビ放送番組における発話被りが発生する時間の平均を平均mとし、前記発話被りが発生する時間の分散を分散vとし、前記平均m及び前記分散vが予め設定されている場合に、
音声データ及び当該音声データをテキストで表したテキストデータを組とした複数の組のデータセットから、2組の音声データ及びテキストデータを選択する第1の選択手段と、
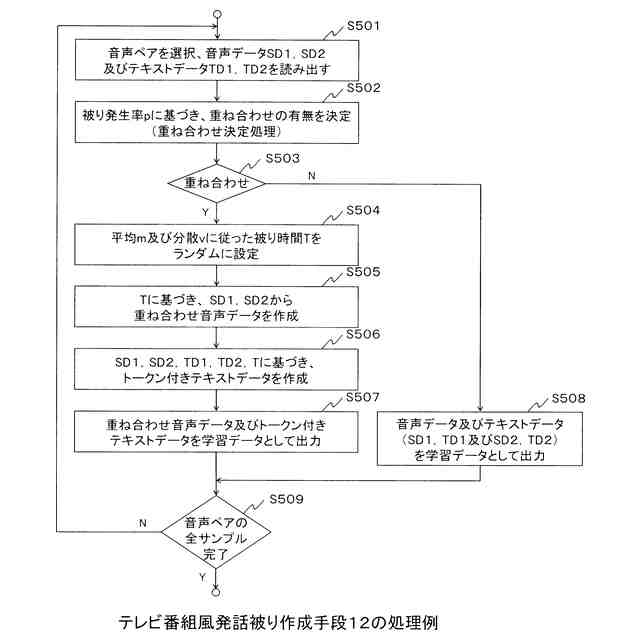
前記平均m及び前記分散vに従った被り時間Tをランダムに設定し、前記第1の選択手段により選択された前記2組の音声データ及びテキストデータにおける2つの音声データのうち一方の末尾の部分と他方の冒頭の部分とが前記被り時間Tの発話被りにて重なるように、前記2つの音声データを重ね合わせることで、第1の重ね合わせ音声データを作成する第1の重ね合わせ音声作成手段と、
前記第1の選択手段により選択された前記2組の音声データ及びテキストデータ、及び前記第1の重ね合わせ音声作成手段により設定された前記被り時間Tに基づいて、前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含む第1のトークン付きテキストデータを作成する第1のトークン付きテキスト作成手段と、を備え、
前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データ及び前記第1のトークン付きテキスト作成手段により作成された前記第1のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いる、ことを特徴とする学習データ作成装置。
続きを表示(約 5,600 文字)
【請求項2】
請求項1に記載の学習データ作成装置において、
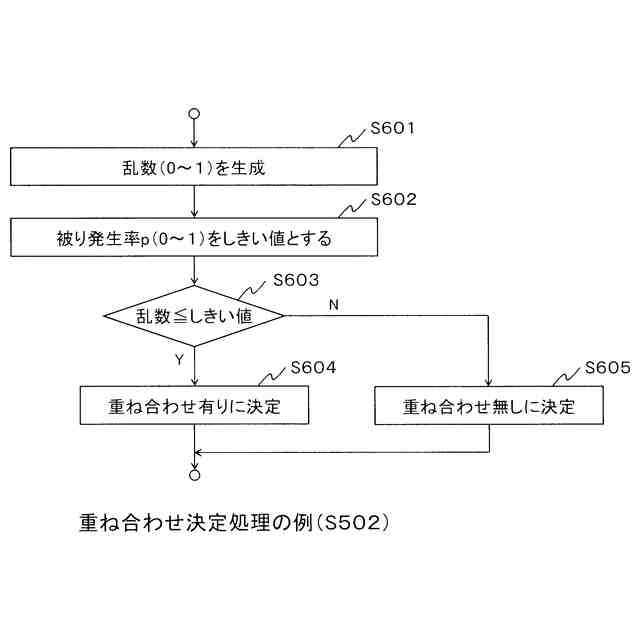
前記テレビ放送番組における発話被りが発生する1発話あたりの確率を被り発生率pとし、前記被り発生率pが予め設定されている場合に、
さらに、前記被り発生率pに基づいて、重ね合わせの有無を決定する重ね合わせ決定手段を備え、
前記第1の重ね合わせ音声作成手段は、
前記重ね合わせ決定手段により重ね合わせ有りが決定された場合、前記平均m及び前記分散vに従った前記被り時間Tをランダムに設定し、前記2つの音声データのうち一方の末尾の部分と他方の冒頭の部分とが、前記被り時間Tの発話被りにて重なるように、前記第1の重ね合わせ音声データを作成し、
前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データ及び前記第1のトークン付きテキスト作成手段により作成された前記第1のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いると共に、前記重ね合わせ決定手段により重ね合わせ無しが決定された場合、前記第1の選択手段により選択された前記2組の音声データ及びテキストデータのそれぞれを、前記学習データとして前記音声認識モデルの学習のためにそのまま用いる、ことを特徴とする学習データ作成装置。
【請求項3】
請求項2に記載の学習データ作成装置において、
前記重ね合わせ決定手段は、
乱数を生成し、前記被り発生率pをしきい値として、前記乱数が前記しきい値以下である場合、重ね合わせ有りを決定し、前記乱数が前記しきい値以下でないと判定した場合、重ね合わせ無しを決定する、ことを特徴とする学習データ作成装置。
【請求項4】
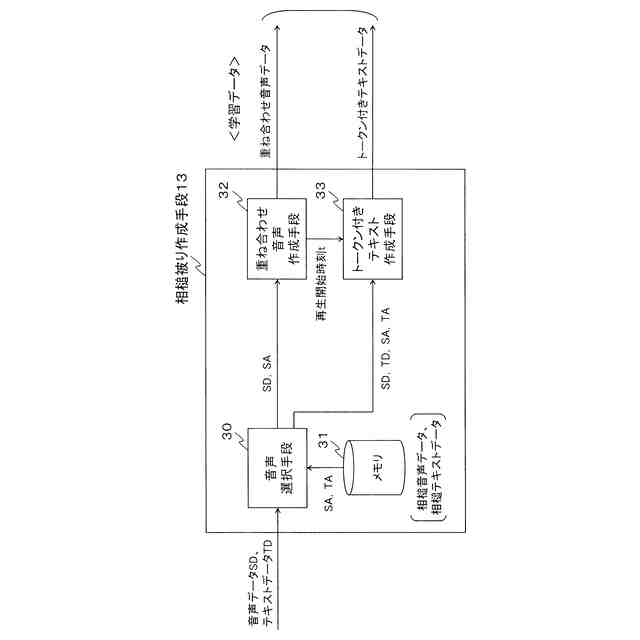
テレビ放送番組の音声を認識するための音声認識モデルに用いる学習データを作成する学習データ作成装置において、
音声データ及び当該音声データをテキストで表したテキストデータを組とした複数の組のデータセットから、1組の音声データ及びテキストデータを選択すると共に、相槌の音声を含む相槌音声データ及び当該相槌音声データをテキストで表した相槌テキストデータを組とした複数の組の相槌データセットから、1組の相槌音声データ及び相槌テキストデータを選択する第2の選択手段と、
前記音声データに対して前記相槌音声データを重ね合わせる時間位置を再生開始時刻tとして、前記再生開始時刻tをランダムに設定し、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータにおける前記音声データに対し、当該音声データの冒頭から前記再生開始時刻tだけ経過した時間位置を基準として、前記第2の選択手段により選択された前記1組の相槌音声データ及び相槌テキストデータにおける前記相槌音声データを重ね合わせることで、第2の重ね合わせ音声データを作成する第2の重ね合わせ音声作成手段と、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータ並びに前記1組の相槌音声データ及び相槌テキストデータ、及び、前記第2の重ね合わせ音声作成手段により設定された前記再生開始時刻tに基づいて、前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含む第2のトークン付きテキストデータを作成する第2のトークン付きテキスト作成手段と、を備え、
前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データ及び前記第2のトークン付きテキスト作成手段により作成された前記第2のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いる、ことを特徴とする学習データ作成装置。
【請求項5】
テレビ放送番組の音声を認識するための音声認識モデルに用いる学習データを作成する学習データ作成装置において、
発話被り作成手段及び相槌被り作成手段を備え、
前記テレビ放送番組における発話被りが発生する時間の平均を平均mとし、前記発話被りが発生する時間の分散を分散vとし、前記平均m及び前記分散vが予め設定されている場合に、
前記発話被り作成手段は、
音声データ及び当該音声データをテキストで表したテキストデータを組とした複数の組のデータセットから、2組の音声データ及びテキストデータを選択する第1の選択手段と、
前記平均m及び前記分散vに従った被り時間Tをランダムに設定し、前記第1の選択手段により選択された前記2組の音声データ及びテキストデータにおける2つの音声データのうち一方の末尾の部分と他方の冒頭の部分とが前記被り時間Tの発話被りにて重なるように、前記2つの音声データを重ね合わせることで、第1の重ね合わせ音声データを作成する第1の重ね合わせ音声作成手段と、
前記第1の選択手段により選択された前記2組の音声データ及びテキストデータ、及び前記第1の重ね合わせ音声作成手段により設定された前記被り時間Tに基づいて、前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含む第1のトークン付きテキストデータを作成する第1のトークン付きテキスト作成手段と、を備え、
前記相槌被り作成手段は、
前記データセットから1組の音声データ及びテキストデータを選択すると共に、相槌の音声を含む相槌音声データ及び当該相槌音声データをテキストで表した相槌テキストデータを組とした複数の組の相槌データセットから、1組の相槌音声データ及び相槌テキストデータを選択する第2の選択手段と、
前記音声データに対して前記相槌音声データを重ね合わせる時間位置を再生開始時刻tとして、前記再生開始時刻tをランダムに設定し、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータにおける前記音声データに対し、当該音声データの冒頭から前記再生開始時刻tだけ経過した時間位置を基準として、前記第2の選択手段により選択された前記1組の相槌音声データ及び相槌テキストデータにおける前記相槌音声データを重ね合わせることで、第2の重ね合わせ音声データを作成する第2の重ね合わせ音声作成手段と、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータ並びに1組の相槌音声データ及び相槌テキストデータ、及び、前記第2の重ね合わせ音声作成手段により設定された前記再生開始時刻tに基づいて、前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データに対応する、前記トークンを含む第2のトークン付きテキストデータを作成する第2のトークン付きテキスト作成手段と、を備え、
前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データ及び前記第1のトークン付きテキスト作成手段により作成された前記第1のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いると共に、
前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データ及び前記第2のトークン付きテキスト作成手段により作成された前記第2のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いる、ことを特徴とする学習データ作成装置。
【請求項6】
請求項1から3までのいずれか一項に記載の学習データ作成装置において、
複数の話者による実際の会話の音声データを会話音声データとし、当該会話音声データをテキストで表したデータを文字起こしテキストデータとして、
前記会話音声データ及び前記文字起こしテキストデータを有音区間毎に区切り、複数の有音区間から発話被りを有する有音区間を削除し、
当該発話被りを有する有音区間が削除された複数の有音区間の音声データ及びテキストデータから、異なる2人の話者による音声データ及びテキストデータをペアデータとして選択し、当該ペアデータによる前記データセットを構成する音声作成手段を備え、
前記第1の選択手段は、
前記データセットから、前記ペアデータにおける2組の音声データ及びテキストデータを選択する、ことを特徴とする学習データ作成装置。
【請求項7】
請求項4に記載の学習データ作成装置において、
複数の話者による実際の会話の音声データを会話音声データとし、当該会話音声データをテキストで表したデータを文字起こしテキストデータとして、
前記会話音声データ及び前記文字起こしテキストデータを有音区間毎に区切り、複数の有音区間から発話被りを有する有音区間を削除し、
当該発話被りを有する有音区間が削除された複数の有音区間の音声データ及びテキストデータから、異なる2人の話者の音声データ及びテキストデータをペアデータとして選択し、当該ペアデータによる前記データセットを構成する音声作成手段を備え、
前記第2の選択手段は、
前記データセットから、前記ペアデータに含まれる1組の音声データ及びテキストデータを選択すると共に、前記相槌データセットから、前記1組の相槌音声データ及び相槌テキストデータを選択する、ことを特徴とする学習データ作成装置。
【請求項8】
テレビ放送番組の音声を認識するための音声認識モデルに用いる学習データを作成する学習データ作成装置を構成するコンピュータを、
前記テレビ放送番組における発話被りが発生する時間の平均を平均mとし、前記発話被りが発生する時間の分散を分散vとし、前記平均m及び前記分散vが予め設定されている場合に、
音声データ及び当該音声データをテキストで表したテキストデータを組とした複数の組のデータセットから、2組の音声データ及びテキストデータを選択する第1の選択手段、
前記平均m及び前記分散vに従った被り時間Tをランダムに設定し、前記第1の選択手段により選択された前記2組の音声データ及びテキストデータにおける2つの音声データのうち一方の末尾の部分と他方の冒頭の部分とが前記被り時間Tの発話被りにて重なるように、前記2つの音声データを重ね合わせることで、第1の重ね合わせ音声データを作成する第1の重ね合わせ音声作成手段、及び、
前記第1の選択手段により選択された前記2組の音声データ及びテキストデータ、及び前記第1の重ね合わせ音声作成手段により設定された前記被り時間Tに基づいて、前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含む第1のトークン付きテキストデータを作成する第1のトークン付きテキスト作成手段として機能させ、
前記第1の重ね合わせ音声作成手段により作成された前記第1の重ね合わせ音声データ及び前記第1のトークン付きテキスト作成手段により作成された前記第1のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いる、ことを特徴とするプログラム。
【請求項9】
テレビ放送番組の音声を認識するための音声認識モデルに用いる学習データを作成する学習データ作成装置を構成するコンピュータを、
音声データ及び当該音声データをテキストで表したテキストデータを組とした複数の組のデータセットから、1組の音声データ及びテキストデータを選択すると共に、相槌の音声を含む相槌音声データ及び当該相槌音声データをテキストで表した相槌テキストデータを組とした複数の組の相槌データセットから、1組の相槌音声データ及び相槌テキストデータを選択する第2の選択手段、
前記音声データに対して前記相槌音声データを重ね合わせる時間位置を再生開始時刻tとして、前記再生開始時刻tをランダムに設定し、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータにおける前記音声データに対し、当該音声データの冒頭から前記再生開始時刻tだけ経過した時間位置を基準として、前記第2の選択手段により選択された前記1組の相槌音声データ及び相槌テキストデータにおける前記相槌音声データを重ね合わせることで、第2の重ね合わせ音声データを作成する第2の重ね合わせ音声作成手段、及び、
前記第2の選択手段により選択された前記1組の音声データ及びテキストデータ並びに前記1組の相槌音声データ及び相槌テキストデータ、及び、前記第2の重ね合わせ音声作成手段により設定された前記再生開始時刻tに基づいて、前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含む第2のトークン付きテキストデータを作成する第2のトークン付きテキスト作成手段として機能させ、
前記第2の重ね合わせ音声作成手段により作成された前記第2の重ね合わせ音声データ及び前記第2のトークン付きテキスト作成手段により作成された前記第2のトークン付きテキストデータを、前記学習データとして前記音声認識モデルの学習のために用いる、ことを特徴とするプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、日本語の音声認識技術において、複数の話者による発話被りを含む音声を高精度に認識するための学習データを作成する学習データ作成装置及びプログラムに関する。
続きを表示(約 1,300 文字)
【背景技術】
【0002】
従来、複数の話者の会話に対する音声認識技術において、発話被りが音声認識率を低下させることが知られている。これは、音声認識モデルを用いた音声認識装置が、発話が被っている区間の音声を精度高く認識することができないからである。
【0003】
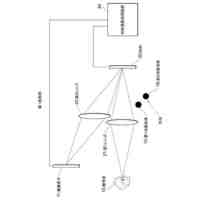
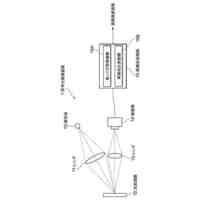
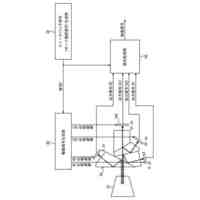
図13は、発話被りの例を説明する図である。図13に示すように、話者W1が「次の駅は新宿ですか」を、話者W2が「渋谷です」を、話者W3が「ありがとうございます」をそれぞれ発話したとする。また、話者W1の発話「ですか」と、話者W2の発話「渋谷」とが時間軸上で重なり、話者W2の発話「です」と、話者W3の発話「あり」とが時間軸上で重なるものとする。
【0004】
この場合、音声認識装置は、これらの発話が重なっている発話被りの部分について、話者W1,W2,W3のそれぞれの音声を精度高く認識することができない。
【0005】
この問題を解決するために、発話被りのある音声データ、及び、発話被りが生じた部分に話者が変更されたことを示すトークンを挿入したテキストデータを用いて、音声認識モデルを学習する手法が提案されている(例えば、非特許文献1を参照)。このようにして学習された音声認識モデルを用いることで、発話被りのある音声の認識率を向上させることができる。
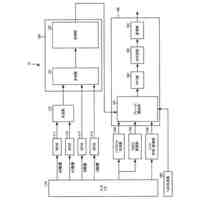
【0006】
図14は、従来の学習データ作成処理の例を示すフローチャートであり、前述の非特許文献1に記載された処理を示している。前述の非特許文献1に記載された学習データ作成処理を行う学習データ作成装置は、音声データ及びこれに対応するテキストデータ(音声データをテキストで表したテキストデータ)を入力する(ステップS1401)。
【0007】
学習データ作成装置は、入力した複数の音声データから、2つの音声データをランダムに選択し(ステップS1402)、0.5秒以上の発話被りが生じるように、2つの音声データをランダムな時間差で重ね合わせる(ステップS1403)。これにより、重ね合わせ音声データが作成される。
【0008】
学習データ作成装置は、2つの音声データ及びステップS1403にて用いた時間差に基づいて、重ね合わせ音声データ内の発話被りが生じた部分を判定する。そして、学習データ作成装置は、重ね合わせ音声データに対応する、発話被りの部分の話者変更を表したトークンを含むテキストデータ(トークン付きテキストデータ)を作成する(ステップS1404)。
【0009】
学習データ作成装置は、重ね合わせ音声データ及びトークン付きテキストデータを学習データとして出力する(ステップS1405)。
【0010】
このようにして作成され出力された重ね合わせ音声データ及びトークン付きテキストデータは、重ね合わせのない元の音声データ及びこれに対応するテキストデータと共に、音声認識モデルの学習のために用いられる。
【先行技術文献】
【非特許文献】
(【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
この特許をJ-PlatPatで参照する
関連特許
日本放送協会
ルータ
5か月前
日本放送協会
撮像素子
6か月前
日本放送協会
撮像装置
10か月前
日本放送協会
撮像装置
4か月前
日本放送協会
撮像装置
17日前
日本放送協会
撮像装置
1か月前
日本放送協会
撮像装置
5か月前
日本放送協会
受信装置
7か月前
日本放送協会
透光性基板
9か月前
日本放送協会
全天周カメラ
8か月前
日本放送協会
視聴予測装置
4か月前
日本放送協会
信号測定装置
9か月前
日本放送協会
衛星追尾装置
4か月前
日本放送協会
符号化撮像装置
4か月前
日本放送協会
カメラ正対治具
1か月前
日本放送協会
磁性細線メモリ
6か月前
日本放送協会
バックプレーン
4か月前
日本放送協会
積層型撮像素子
7か月前
日本放送協会
機械学習システム
4か月前
日本放送協会
360度撮影装置
13日前
日本放送協会
情報提示システム
13日前
日本放送協会
撮像素子の製造方法
6か月前
日本放送協会
三次元映像表示装置
9か月前
日本放送協会
三次元撮像システム
3か月前
日本放送協会
LDM送信システム
4日前
日本放送協会
光バイパススイッチ
6か月前
日本放送協会
データ管理システム
2か月前
日本放送協会
3次元映像表示装置
2か月前
日本放送協会
送信装置及び受信装置
1か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
1か月前
日本放送協会
撮像素子及び撮像装置
5か月前
日本放送協会
表示端末、プログラム
2か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
5か月前
日本放送協会
送信装置及び受信装置
24日前
続きを見る
他の特許を見る






 特許ウォッチ
特許ウォッチ