TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025146806
公報種別
公開特許公報(A)
公開日
2025-10-03
出願番号
2025046507
出願日
2025-03-21
発明の名称
視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法及びシステム
出願人
山東大学
,
SHANDONG UNIVERSITY
代理人
弁理士法人コスモス国際特許商標事務所
主分類
G06T
7/00 20170101AFI20250926BHJP(計算;計数)
要約
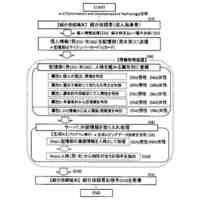
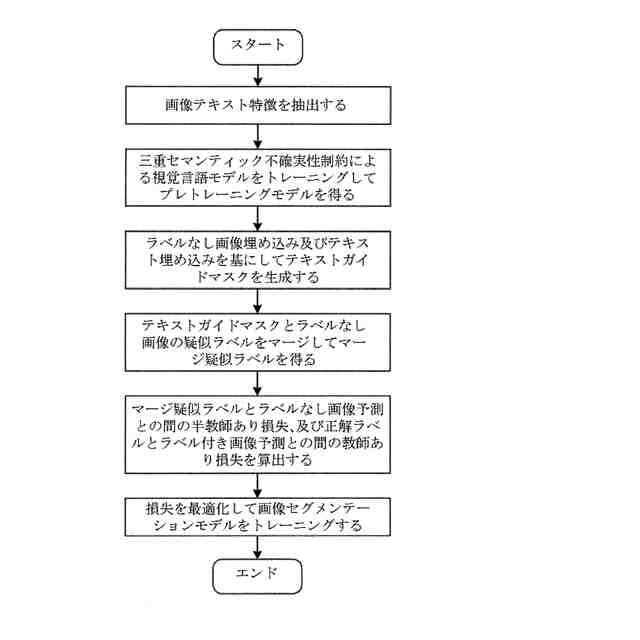
【解決手段】視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法は、医用画像を取得するステップと、ラベルなし画像及びテキスト記述を視覚言語モデルに入力し、得られた密な画像埋め込み及びテキスト埋め込みを基にしてテキストガイドマスクを得るステップと、ラベル付き画像を生徒モデルに入力して得られたラベル付き画像予測を使用して教師あり損失を算出するステップと、ラベルなし画像を生徒モデル及び教師モデルに夫々入力してラベルなし画像予測及び疑似ラベルを得、テキストガイドマスクと疑似ラベルとをマージし、マージ疑似ラベル及びラベルなし画像予測を使用して半教師あり損失を算出するステップと、教師あり損失及び半教師あり損失に基づきトレーニングした生徒モデルを用いて医用画像セグメンテーションを行うステップと、を含む。
【効果】テキスト記述の利点を利用して対象セグメンテーション領域を正確に特定することができる。
【選択図】図1
特許請求の範囲
【請求項1】
セグメント化する医用画像を取得するステップと、
ラベルなし画像及びテキスト記述を視覚言語モデルに入力して密な画像埋め込み及びテキスト埋め込みを得、密な画像埋め込み及びテキスト埋め込みを基にしてテキストガイドマスクを得るステップと、
教師-生徒モデルを半教師ありセグメンテーションバックボーンネットワークとし、ラベル付き画像を生徒モデルに入力してラベル付き画像予測を得、ラベル付き画像予測及び正解ラベルを使用して教師あり損失を算出するステップと、
ラベルなし画像を生徒モデル及び教師モデルにそれぞれ入力してラベルなし画像予測及び疑似ラベルを得、テキストガイドマスクと疑似ラベルをマージしてマージ疑似ラベルを得、マージ疑似ラベル及びラベルなし画像予測を使用して半教師あり損失を算出するステップと、
教師あり損失及び半教師あり損失を基にして生徒モデルをトレーニングし、トレーニングされた生徒モデルを使用して医用画像セグメンテーションを行うステップと、を含み、
前記視覚言語モデルはプレトレーニングされた視覚言語モデルであり、視覚言語モデルは、具体的に、次のようにプレトレーニングされ、
取得された元画像を増強し、増強画像を得、
元画像及び増強画像をビジュアルエンコーダ及びモメンタムビジュアルエンコーダにそれぞれ入力し、元画像埋め込み及び増強画像埋め込みを得、
元画像及び増強画像のテキスト記述をテキストエンコーダ及びモメンタムテキストエンコーダにそれぞれ入力し、テキスト埋め込み及びモメンタムテキスト埋め込みを得、
不確実性セマンティック制約ポリシーを構築し、分布距離を不確実性レベルとして算出し、セマンティック差異を制約し、具体的に、
ペアデータ(x
1
,x
2
)の場合、それらのセマンティック差異は、
TIFF
2025146806000036.tif
11
170
は2ノルムであり、(s
1
,s
2
)は(x
1
,x
2
)のセマンティック埋め込みであり、セマンティック埋め込み(s
1
,s
2
)は、 N(μ
1
,σ
1
)及びN(μ
2
,σ
2
)を分布表現し、ここで、μは平均ベクトルであり、σは標準偏差ベクトルであり、Wasserstein-2距離を使用して分布間の差異を不確実性レベルとして測定し、Wasserstein-2距離は、次のように表され、
TIFF
2025146806000037.tif
11
170
グローバルセマンティック特徴[CLS]は分布表現をモデリングするために用いられ、データペア間の不確実性レベルは、次のように定義され、
TIFF
2025146806000038.tif
9
170
ここで、aは不確実性の度合いを制御するための正のパラメータであり、bは偏差値であり、
2つのデータを比較する時に、セマンティック差異D
s
(・)及び不確実性レベルD
u
(・)は同時に考慮され、D
u
(・)とD
s
(・)との比を相対的な不確実性
TIFF
2025146806000039.tif
11
170
とセマンティック不確実性の制約関数は、次のように定義され、
TIFF
2025146806000040.tif
26
170
ここで、D
SUC
(・)はセマンティック不確実性の制約関数であり、λは正のハイパーパラメータであり、式D
SUC
(・)中の2つのデータの間の相対的な不確実性
TIFF
2025146806000041.tif
10
170
が大きい場合、D
s
(x
1
,x
2
)が小さくなり、それによって2つのデータの間のセマンティック差異が制約され、
三重対照学習を共同で実行し、各対照学習プロセスに不確実性セマンティック制約ポリシーを埋め込み、各対照学習損失を算出し、
各対照学習損失を使用して視覚言語モデルのパラメータ重みを最適化し、プレトレーニングされた視覚言語モデルを得ることを特徴とする、視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
続きを表示(約 3,300 文字)
【請求項2】
前記三重対照学習は、クロスモーダル対照学習、イントラモーダル対照学習及びグローバル・ローカル対照学習を含むことを特徴とする、請求項1に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
【請求項3】
前記クロスモーダル対照学習は、画像とテキストとの効果的なアライメントを実現するものであり、前記イントラモーダル対照学習は、各モーダル内の異なるサンプルの間の潜在的な関連性をキャプチャすることで、より豊富なコンテキスト関係及び内部表現を提供するものであり、前記グローバル・ローカル対照学習は、異なるスケールの特徴を理解することで、モデルが重要なローカル情報にフォーカスするように促し、それによって無関係なローカル領域の学習を制限するものであることを特徴とする、請求項2に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
【請求項4】
前記不確実性セマンティック制約ポリシーは、具体的に、テキスト埋め込み及びモメンタムテキスト埋め込みを対応する2つの分布表現としてモデリングし、これらの2つの分布間の分布距離を不確実性レベルとして算出し、該不確実性レベルに基づいてテキスト埋め込みとモメンタムテキスト埋め込みとの間の差異を制約することを特徴とする、請求項1に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
【請求項5】
モメンタムビジュアルエンコーダ及びモメンタムテキストエンコーダはそれぞれ、ビジュアルエンコーダ及びテキストエンコーダによってモメンタム更新されることを特徴とする、請求項1に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
【請求項6】
テキストガイドマスクと密な画像埋め込みとを要素ごとに乗算して、テキストガイド埋め込みを得、テキストガイド埋め込み及びテキスト埋め込みを使用してテキストガイド損失を算出し、テキストガイド損失を使用してテキストガイドマスクを最適化するステップをさらに含むことを特徴とする、請求項1に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法。
【請求項7】
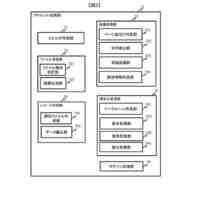
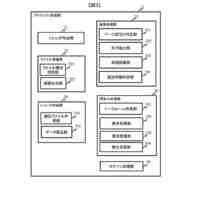
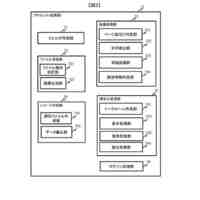
セグメント化する医用画像を取得するように構成されるデータ取得モジュールと、
ラベルなし画像及びテキスト記述を視覚言語モデルに入力して密な画像埋め込み及びテキスト埋め込みを得、密な画像埋め込み及びテキスト埋め込みを基にしてテキストガイドマスクを得るように構成されるテキストガイドマスク生成モジュールと、
教師-生徒モデルを半教師ありセグメンテーションバックボーンネットワークとし、ラベル付き画像を生徒モデルに入力してラベル付き画像予測を得、ラベル付き画像予測及び正解ラベルを使用して教師あり損失を算出するように構成される教師あり損失算出モジュールと、
ラベルなし画像を生徒モデル及び教師モデルにそれぞれ入力してラベルなし画像予測及び疑似ラベルを得、テキストガイドマスクと疑似ラベルをマージしてマージ疑似ラベルを得、マージ疑似ラベル及びラベルなし画像予測を使用して半教師あり損失を算出するように構成される教師なし損失算出モジュールと、
教師あり損失及び半教師あり損失を基にして生徒モデルをトレーニングし、トレーニングされた生徒モデルを使用して医用画像セグメンテーションを行うように構成されるモデルトレーニングモジュールと、を含み、
前記視覚言語モデルはプレトレーニングされた視覚言語モデルであり、視覚言語モデルは、具体的に、次のようにプレトレーニングされ、
取得された元画像を増強し、増強画像を得、
元画像及び増強画像をビジュアルエンコーダ及びモメンタムビジュアルエンコーダにそれぞれ入力し、元画像埋め込み及び増強画像埋め込みを得、
元画像及び増強画像のテキスト記述をテキストエンコーダ及びモメンタムテキストエンコーダにそれぞれ入力し、テキスト埋め込み及びモメンタムテキスト埋め込みを得、
不確実性セマンティック制約ポリシーを構築し、分布距離を不確実性レベルとして算出し、セマンティック差異を制約し、具体的に、
ペアデータ(x
1
,x
2
)の場合、それらのセマンティック差異は、
TIFF
2025146806000042.tif
11
170
は2ノルムであり、(s
1
,s
2
)は(x
1
,x
2
)のセマンティック埋め込みであり、セマンティック埋め込み(s
1
,s
2
)は、N(μ
1
,σ
1
)及びN(μ
2
,σ
2
)を分布表現し、ここで、μは平均ベクトルであり、σは標準偏差ベクトルであり、Wasserstein-2距離を使用して分布間の差異を不確実性レベルとして測定し、Wasserstein-2距離は、次のように示され、
TIFF
2025146806000043.tif
11
170
グローバルセマンティック特徴[CLS]は分布表現をモデリングするために用いられ、データペア間の不確実性レベルは、次のように定義され、
TIFF
2025146806000044.tif
11
170
ここで、aは不確実性の度合いを制御するための正のパラメータであり、bは偏差値であり、
2つのデータを比較する時に、セマンティック差異D
s
(・)及び不確実性レベルD
u
(・)は同時に考慮され、D
u
(・)とD
s
(・)との比を相対的な不確実性
TIFF
2025146806000045.tif
11
170
とセマンティック不確実性の制約関数は、次のように定義され、
TIFF
2025146806000046.tif
26
170
ここで、D
SUC
(・)はセマンティック不確実性の制約関数であり、λは正のハイパーパラメータであり、式D
SUC
(・)中の2つのデータの間の相対的な不確実性
TIFF
2025146806000047.tif
10
170
が大きい場合、D
s
(x
1
,x
2
)が小さくなり、それによって2つのデータの間のセマンティック差異が制約され、
三重対照学習を共同で実行し、各対照学習プロセスに不確実性セマンティック制約ポリシーを埋め込み、各対照学習損失を算出し、
各対照学習損失を使用して視覚言語モデルのパラメータ重みを最適化し、プレトレーニングされた視覚言語モデルを得ることを特徴とする、視覚言語モデルに基づく半教師あり医用画像セグメンテーションシステム。
【請求項8】
プログラムが記憶されている媒体であって、該プログラムがプロセッサによって実行されると、請求項1から6のいずれか1項に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法のステップが実現されることを特徴とする、媒体。
【請求項9】
メモリと、プロセッサと、メモリに記憶されてプロセッサで実行可能なプログラムとを含む電子機器であって、前記プログラムが前記プロセッサによって実行されると、請求項1から6のいずれか1項に記載の視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法のステップが実現される、電子機器。
発明の詳細な説明
【技術分野】
【0001】
(関連出願の相互参照)
本発明は、2024年03月20日に中国国家知識産権局に提出された、出願番号が202410321989.Xで、発明の名称が「視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法及びシステム」である中国特許出願の優先権を主張し、その全ての内容は、あらゆる目的のために、引用によって本発明に組み込まれ、本発明の一部を構成する。
続きを表示(約 2,800 文字)
【0002】
本開示は、画像処理の技術分野に関し、具体的には、視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法及びシステムに関する。
【背景技術】
【0003】
本部分の記載は、本開示に関連する背景技術の情報を提供するだけであり、必ずしも先行技術を構成するものではない。
【0004】
医用画像セグメンテーションは、異常画像中の重要な器官や病変を抽出するために使用でき、コンピュータ補助診断と治療研究において重要な役割を果たしている。近年、U-Net、U-Net++、H-DenseUNetなど、多くの教師あり学習に基づく医用画像セグメンテーションコーデックネットワークは顕著な成果を上げている。しかしながら、これらの教師あり学習方法は、大量のピクセルレベルのラベル付きデータに大きく依存しており、実際に医用画像の注釈付けが通常、非常に高価である。また、自然画像に比べて、医用画像の注釈付けには高度な専門知識が必要である。半教師あり学習は、教師あり学習に比べて、不完全なデータ監視の問題を解決する新しい学習パラダイムである。少量のラベル付きデータ及び大量のラベルなしデータを使用して共同トレーニングを実現する。医用画像セグメンテーションにおいて、半教師あり学習は、教師あり学習よりも重要であり、実際の臨床場面での需要により合致していることが明らかである。半教師あり医用画像セグメンテーションにおいて、セグメンテーションの性能は、疑似ラベルの品質に密接に関係している。現在の半教師あり医用画像セグメンテーション方法は、共同トレーニングを行う際に、モデル間の相補性が不十分になり、同一のサンプルの予測が一致しなくなり、疑似ラベルの品質に影響を与える可能性がある。
【0005】
視覚言語モデルは、効果的なパラダイムとして半教師あり医用画像セグメンテーションでの疑似ラベルの品質を高めることができる。具体的には、視覚言語モデルは、入力された画像及びテキスト情報に基づいて、テキストガイドによる画像セグメンテーションマスクを生成し、該マスクを従来の半教師あり方法で生成された疑似ラベルとマージすることで、疑似ラベルの品質を補う。しかしながら、従来の視覚言語モデルは、プレトレーニング時にクロスモーダル不確実性とイントラモーダル不確実性の問題がある。クロスモーダル不確実性は、複数の画像/テキストが1つのテキスト/画像に対応し得ることとして表われる。イントラモーダル不確実性は、画像において、1つのプロンプト視覚領域に複数の異なるオブジェクトが含まれているため、視覚領域を記述する際に、どのオブジェクトを指すかが不明であり、言語の面では、同義語や単語間の上下位関係などの単語の複雑な関係により、単語の曖昧さが生じることとして表われる。従来の不確実性認識による視覚言語モデル方法は、主に分布を利用してセマンティック埋め込みを表すことで、不確実性の問題を解決する。しかしながら、分布に基づく方法は2つの課題に直面している。第一に、分布の分散が分布差異を反映しているが、分布だけでは抽象的又は複雑なセマンティック情報を完全に認識してセマンティック不確実性を理解することができない。第二に、従来の分布に基づく視覚言語モデルは、主にクロスモーダル対照学習に焦点を当て、各モーダル内のセマンティック関連性を無視しているため、クロスモーダルアライメントの不確実性が生じる。
【発明の概要】
【0006】
上記の欠陥に対して、本開示は、プレトレーニングされた視覚言語モデルにより画像とテキスト埋め込みを抽出し、プレトレーニングされた視覚言語モデル内の豊富なアプリオリを半教師あり学習に遷移させる、視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法及びシステムを提案する。テキストガイドマスクを半教師あり医用画像セグメンテーションに集約することで、疑似ラベルの品質欠陥を補い、テキスト記述の利点を利用して対象セグメンテーション領域を正確に特定する。類似するがセマンティックが曖昧であるデータペアに対するモデルの理解を促進する、セマンティック不確実性制約ポリシーを提案する。制約ポリシーを三重不確実性対照学習に埋め込み、クロスモーダルアライメントの不確実性を低減する。
【0007】
上記の目的を実現するために、本開示は以下の技術的解決手段を採用する。
【0008】
本開示の第1態様では、
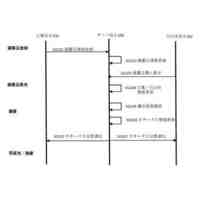
セグメント化する医用画像を取得するステップと、
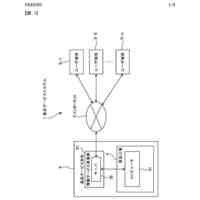
ラベルなし画像及びテキスト記述を視覚言語モデルに入力して密な画像埋め込み及びテキスト埋め込みを得、密な画像埋め込み及びテキスト埋め込みを基にしてテキストガイドマスクを得るステップと、
教師-生徒モデルを半教師ありセグメンテーションバックボーンネットワークとし、ラベル付き画像を生徒モデルに入力してラベル付き画像予測を得、ラベル付き画像予測及び正解ラベルを使用して教師あり損失を算出するステップと、
ラベルなし画像を生徒モデル及び教師モデルにそれぞれ入力してラベルなし画像予測及び疑似ラベルを得、テキストガイドマスクと疑似ラベルをマージしてマージ疑似ラベルを得、マージ疑似ラベル及びラベルなし画像予測を使用して半教師あり損失を算出するステップと、
教師あり損失及び半教師あり損失を基にして生徒モデルをトレーニングし、トレーニングされた生徒モデルを使用して医用画像セグメンテーションを行うステップと、を含む、視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法を提供する。
【0009】
さらなる実現形態として、前記視覚言語モデルはプレトレーニングされた視覚言語モデルであり、視覚言語モデルは、具体的に、次のようにプレトレーニングされ、
取得された元画像を増強し、増強画像を得、
元画像及び増強画像をビジュアルエンコーダ及びモメンタムビジュアルエンコーダにそれぞれ入力し、元画像埋め込み及び増強画像埋め込みを得、
元画像及び増強画像のテキスト記述をテキストエンコーダ及びモメンタムテキストエンコーダにそれぞれ入力し、テキスト埋め込み及びモメンタムテキスト埋め込みを得、
三重対照学習を共同で実行し、各対照学習プロセスに不確実性セマンティック制約ポリシーを埋め込み、各対照学習損失を算出し、
各対照学習損失を使用して視覚言語モデルのパラメータ重みを最適化し、プレトレーニングされた視覚言語モデルを得る。
【0010】
さらなる実現形態として、前記三重対照学習は、クロスモーダル対照学習、イントラモーダル対照学習及びグローバル・ローカル対照学習を含む。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
山東大学
クロスモーダル損失に基づく目標音声分離方法及びシステム
28日前
山東大学
絶縁油紙の電気・熱・機械複合劣化の機械的特性の試験方法
8か月前
山東大学
4D呼吸運動合成用の画像レジストレーション方法及びシステム
14日前
山東大学
パルスレーザ衝撃によるフラットホール接続方法並びにその装置及び応用
7か月前
山東大学
視覚言語モデルに基づく半教師あり医用画像セグメンテーション方法及びシステム
今日
個人
裁判のAI化
2か月前
個人
情報処理システム
2か月前
個人
地球保全システム
2日前
個人
フラワーコートA
1か月前
個人
工程設計支援装置
1か月前
個人
介護情報提供システム
2か月前
個人
冷凍食品輸出支援構造
29日前
個人
為替ポイント伊達夢貯
29日前
個人
設計支援システム
2か月前
個人
表変換編集支援システム
22日前
個人
設計支援システム
2か月前
個人
携帯情報端末装置
1か月前
個人
結婚相手紹介支援システム
1か月前
個人
知財出願支援AIシステム
29日前
キヤノン電子株式会社
携帯装置
2か月前
株式会社サタケ
籾摺・調製設備
2か月前
個人
行動時間管理システム
24日前
株式会社カクシン
支援装置
2か月前
個人
AIによる情報の売買の仲介
1か月前
個人
パスワード管理支援システム
22日前
個人
AIキャラクター制御システム
22日前
株式会社アジラ
進入判定装置
1か月前
株式会社キーエンス
受発注システム
1日前
日本精機株式会社
施工管理システム
1か月前
個人
食品レシピ生成システム
1日前
個人
海外支援型農作物活用システム
14日前
株式会社キーエンス
受発注システム
1日前
株式会社キーエンス
受発注システム
1日前
個人
備蓄品の管理方法
2か月前
個人
パスポートレス入出国システム
1か月前
個人
システム及びプログラム
15日前
続きを見る
他の特許を見る
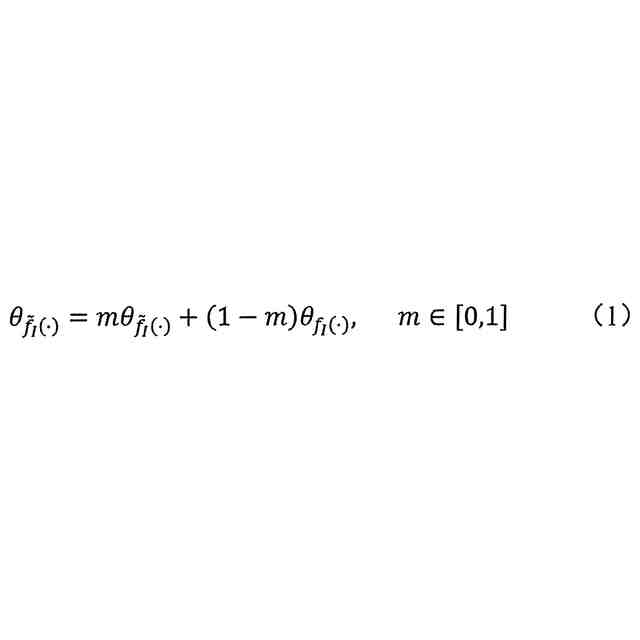
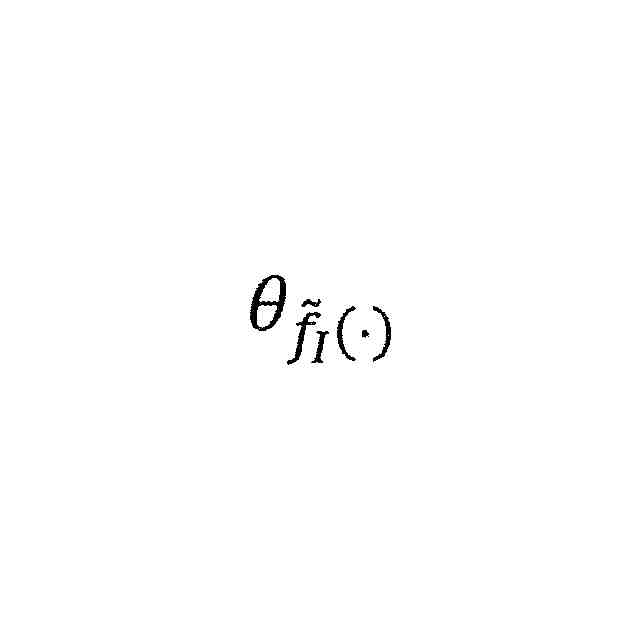
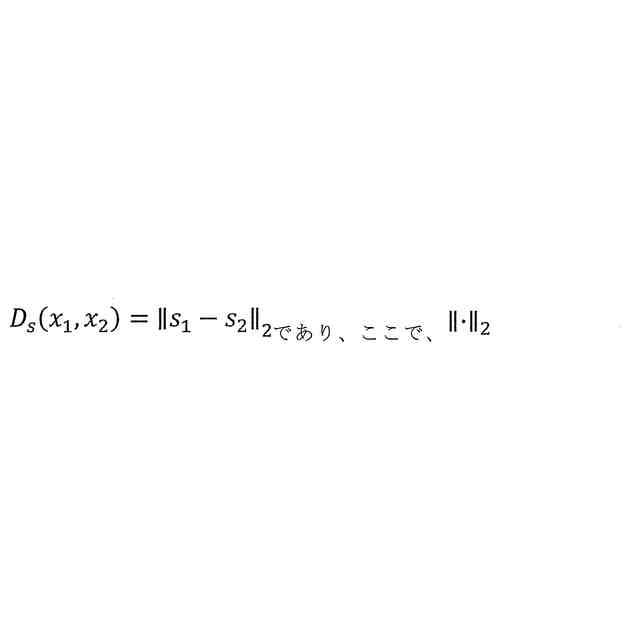
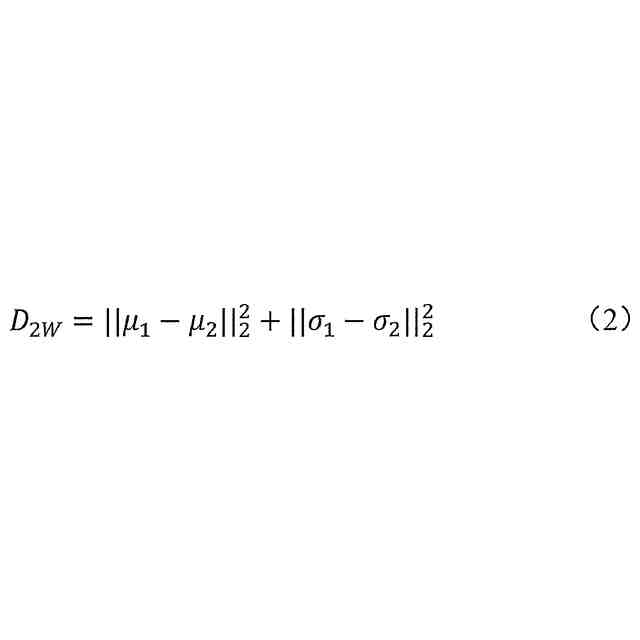
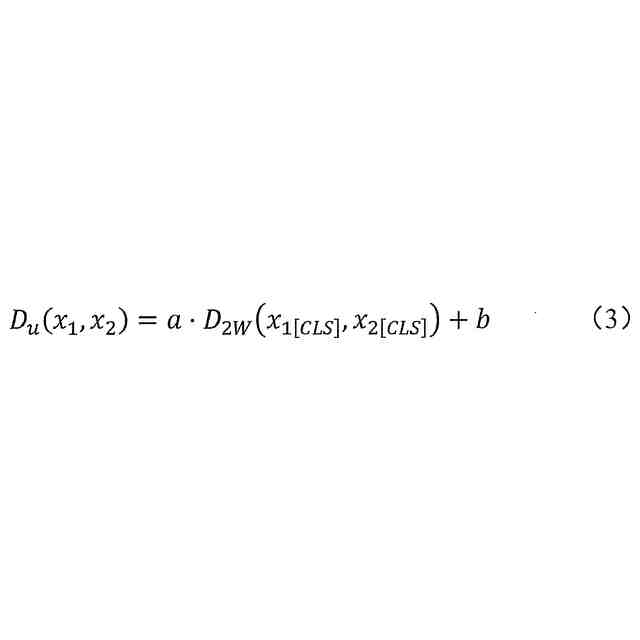

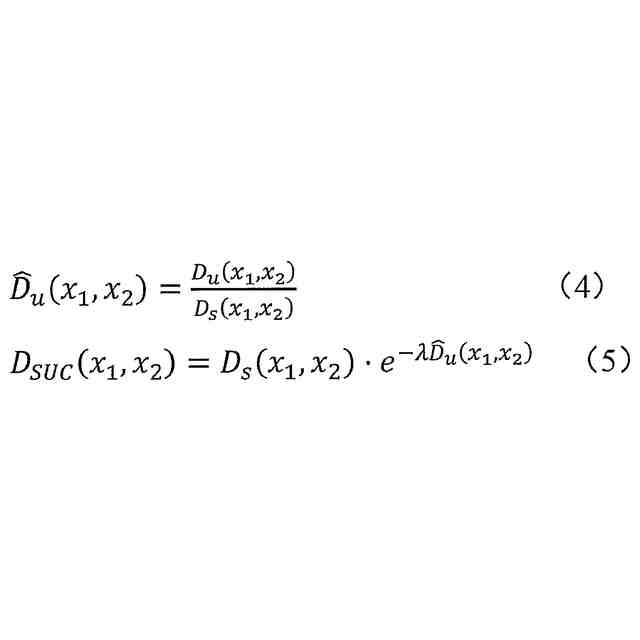
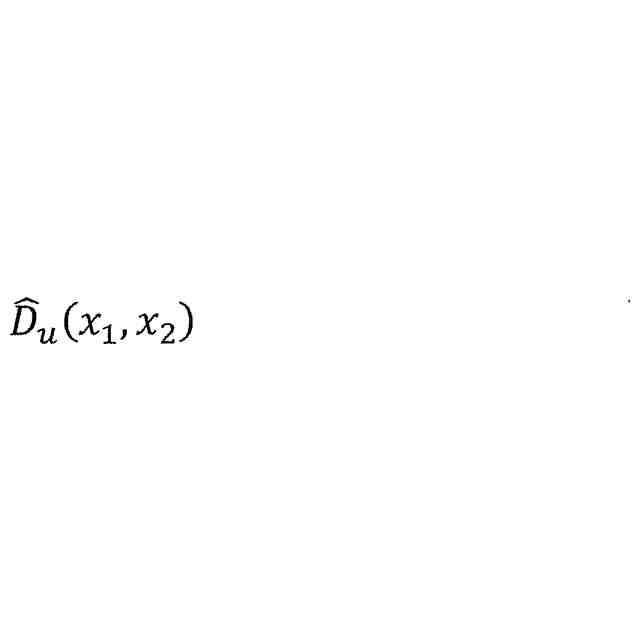
 特許ウォッチ
特許ウォッチ