TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025130016
公報種別
公開特許公報(A)
公開日
2025-09-05
出願番号
2024198276
出願日
2024-11-13
発明の名称
クロスモーダル損失に基づく目標音声分離方法及びシステム
出願人
山東大学
,
SHANDONG UNIVERSITY
代理人
弁理士法人コスモス国際特許商標事務所
主分類
G10L
21/0264 20130101AFI20250829BHJP(楽器;音響)
要約
【課題】クロスモーダル損失に基づく目標音声分離方法及びシステムを提供する。
【解決手段】目標音声分離方法は、プレトレーニングされた目標音声分離モデルを利用し、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得し、かつ、目標話者の視覚情報をモデルに導入することで視覚埋め込みを抽出し、事前登録音声の代わりにオーディオ埋め込み自己抽出の方法を採用し、クロスモーダル損失を導入して話者の視覚と聴覚特徴の抽出を制約することによって、目標混淆の問題を回避する。また、2つの分岐アーキテクチャを作成し、干渉話者音声信号を取得して補助情報に変換し、第1分岐の音声抽出を最適化することによって、取得が困難である補助情報の使用を回避し、目標音声分離の実用場面での適応度を向上させる。
【選択図】図1
特許請求の範囲
【請求項1】
目標話者のビデオを取得し、目標話者のリップシーケンスを抽出するステップと、
混合オーディオ信号を取得するステップと、
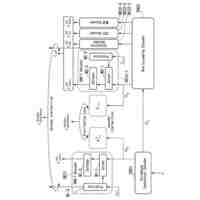
プレトレーニングされた目標音声分離モデルを利用し、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得するステップであって、目標音声分離モデルのトレーニングプロセスがクロスモーダル損失を考慮するステップと、を含み、
前記目標音声分離モデルは、トレーニングプロセスで、2つの分岐アーキテクチャがあり、
第1分岐は、視聴覚マルチモーダル目標音声抽出を実現するために用いられ、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得し、
前記第1分岐は、オーディオエンコーダと、視覚エンコーダと、話者抽出器と、オーディオデコーダとを含み、
オーディオエンコーダは、混合オーディオ信号からオーディオ埋め込みを抽出し、視覚エンコーダは、目標話者のリップシーケンスを視覚埋め込みとして符号化し、
話者抽出器は、抽出されたオーディオ埋め込みと視覚埋め込みの入力を受信し、多層反復抽出器ブロックを含み、各抽出器ブロックは、時間次元で2つのモーダルの埋め込みをつなぎ合わせ、区別的なアイデンティティ情報を含む目標話者埋め込みを取得する話者エンコーダと、視覚埋め込み、目標話者埋め込み及び前の層のマスク推定器の出力に基づき、目標話者マスクを取得するマスク推定器と、を含み、
前記オーディオデコーダは、目標話者マスクに基づき、目標音声信号を取得し、
第2分岐は、シングルモーダル干渉音声抽出を実現するために用いられ、第1分岐の推定目標音声信号と混合オーディオ信号に基づき、分離された干渉音声信号を取得し、取得された干渉音声信号を補助情報とし、クロスモーダル損失によって第1分岐の目標音声の抽出に影響を与え、
前記第2分岐は、順次接続されたオーディオエンコーダと、話者抽出器と、オーディオデコーダとを含み、
前記第2分岐は、トレーニングプロセスにのみ存在し、
第2分岐のオーディオエンコーダは、混合オーディオ信号と第1分岐で推定された目標音声信号との差を受信し、話者エンコーダは、オーディオ埋め込みのみを受信し、干渉話者埋め込みを出力し、
第1分岐と第2分岐は、いずれもオーディオエンコーダ、オーディオデコーダ及び話者抽出器を備え、
オーディオエンコーダは、一次元畳み込みによって、時間領域オーディオ信号
TIFF
2025130016000010.tif
9
170
をオーディオ特徴シーケンスX(t)に変換することを実現し、変換プロセスは下記式で表すことができ、
TIFF
2025130016000011.tif
9
170
ここで、Nはオーディオ埋め込みの次元であり、Tはオーディオサンプリングの総数であり、K=(2(T-L))/L+1であり、Lは一次元畳み込みの畳み込みカーネルのサイズであり、
オーディオデコーダは、重複加算操作を実行してオーディオ特徴シーケンス
TIFF
2025130016000012.tif
10
170
として再作成し、デコードプロセスは以下のとおりであり、
TIFF
2025130016000013.tif
20
170
目標音声分離モデルのトレーニングプロセスで、3つの目標関数を含むマルチタスク学習フレームワークを作成し、第1分岐のスケール不変信号対雑音比損失は、抽出された目標音声と純粋な音声との間の品質を判断するために用いられ、第2分岐のスケール不変信号対雑音比損失は、抽出された干渉音声と純粋な目標音声との間の品質を判断するために用いられ、クロスモーダル損失は、目標視覚特徴と推定目標音声信号オーディオ特徴を近づけ、目標視覚特徴と推定干渉音声信号オーディオ特徴を遠ざけるために用いられ、損失は以下のように定義され、
TIFF
2025130016000014.tif
68
170
クロスモーダル損失は、2つの分岐のトレーニングプロセスに同時に影響を与え、目標話者の視覚特徴、目標音声特徴及び干渉音声特徴の間で計量学習を行い、ポジティブサンプルの距離を近づけ、ネガティブサンプルの距離を遠ざけ、視覚と聴覚特徴の抽出を制約し、
ここで、γはスケール因子であり、dpは視覚特徴と推定目標音声信号オーディオ特徴との間の余弦距離を表し、dnは視覚特徴と推定干渉音声信号オーディオ特徴との間の余弦距離を表し、dp,dn∈[0,2]であり、marginは2つの距離の間のマージンであり、0.5に設定され、
目標音声分離アルゴリズムにクロスモーダル損失を導入し、目標話者の視覚特徴、目標音声特徴及び干渉音声特徴の間で計量学習を行い、視聴覚一貫性によって視覚と聴覚特徴の抽出を制約し、干渉話者情報を補助情報に変換し、第1分岐の音声抽出を最適化することを特徴とする、クロスモーダル損失に基づく目標音声分離方法。
続きを表示(約 2,900 文字)
【請求項2】
前記視覚エンコーダは、順次接続された3D畳み込み層と、残差ネットワーク層と、ビデオ時間畳み込み層とを含み、ビデオ時間畳み込み層は、順次接続された正規化線形ユニットと、バッチ正規化層と、深さ単位分離可能畳み込み層とを含み、視覚エンコーダは、オーディオ同期のカットされた目標話者のリップシーケンスを受信し、ネットワーク層を通じて視覚埋め込みを抽出し、ビデオ時間畳み込み層の出力をアップサンプリングし、最終的に視覚埋め込みを取得することを特徴とする、請求項1に記載のクロスモーダル損失に基づく目標音声分離方法。
【請求項3】
前記話者エンコーダは、順次接続された3つの残差ブロックと適応平均プーリング層とを含み、前記マスク推定器は、積層された複数の時間畳み込みブロックを含み、各時間畳み込みブロックは、順次接続された複数の一次元畳み込み層と残差モジュールとを含むことを特徴とする、請求項1に記載のクロスモーダル損失に基づく目標音声分離方法。
【請求項4】
目標音声分離モデルのトレーニングプロセスで、テスト要求が満たされるまで、既存のオーディオデータ及び対応するビデオデータを用いて、Adamオプティマイザによって最適化トレーニングを行うことを特徴とする、請求項1に記載のクロスモーダル損失に基づく目標音声分離方法。
【請求項5】
目標話者のビデオを取得し、目標話者のリップシーケンスを抽出し、混合オーディオ信号を取得するように配置される、データ取得モジュールと、
プレトレーニングされた目標音声分離モデルを利用し、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得するように配置される目標音声分離モジュールであって、トレーニングプロセスがクロスモーダル損失を考慮する目標音声分離モジュールと、を含み、
前記目標音声分離モデルは、トレーニングプロセスで、2つの分岐アーキテクチャがあり、
第1分岐は、視聴覚マルチモーダル目標音声抽出を実現するために用いられ、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得し、
前記第1分岐は、オーディオエンコーダと、視覚エンコーダと、話者抽出器と、オーディオデコーダとを含み、
オーディオエンコーダは、混合オーディオ信号からオーディオ埋め込みを抽出し、視覚エンコーダは、目標話者のリップシーケンスを視覚埋め込みとして符号化し、
話者抽出器は、抽出されたオーディオ埋め込みと視覚埋め込みの入力を受信し、多層反復抽出器ブロックを含み、各抽出器ブロックは、時間次元で2つのモーダルの埋め込みをつなぎ合わせ、区別的なアイデンティティ情報を含む目標話者埋め込みを取得する話者エンコーダと、視覚埋め込み、目標話者埋め込み及び前の層のマスク推定器の出力に基づき、目標話者マスクを取得するマスク推定器と、を含み、
前記オーディオデコーダは、目標話者マスクに基づき、目標音声信号を取得し、
第2分岐は、シングルモーダル干渉音声抽出を実現するために用いられ、第1分岐の推定目標音声信号と混合オーディオ信号に基づき、分離された干渉音声信号を取得し、取得された干渉音声信号を補助情報とし、クロスモーダル損失によって第1分岐の目標音声の抽出に影響を与え、
前記第2分岐は、順次接続されたオーディオエンコーダと、話者抽出器と、オーディオデコーダとを含み、
前記第2分岐は、トレーニングプロセスにのみ存在し、
第2分岐のオーディオエンコーダは、混合オーディオ信号と第1分岐で推定された目標音声信号との差を受信し、話者エンコーダは、オーディオ埋め込みのみを受信し、干渉話者埋め込みを出力し、
第1分岐と第2分岐は、いずれもオーディオエンコーダ、オーディオデコーダ及び話者抽出器を備え、
オーディオエンコーダは、一次元畳み込みによって、時間領域オーディオ信号
TIFF
2025130016000015.tif
9
170
をオーディオ特徴シーケンスX(t)に変換することを実現し、変換プロセスは下記式で表すことができ、
TIFF
2025130016000016.tif
9
170
ここで、Nはオーディオ埋め込みの次元であり、Tはオーディオサンプリングの総数であり、K=(2(T-L))/L+1であり、Lは一次元畳み込みの畳み込みカーネルのサイズであり、
オーディオデコーダは、重複加算操作を実行してオーディオ特徴シーケンス
TIFF
2025130016000017.tif
9
170
として再作成し、デコードプロセスは以下のとおりであり、
TIFF
2025130016000018.tif
20
170
目標音声分離モデルのトレーニングプロセスで、3つの目標関数を含むマルチタスク学習フレームワークを作成し、第1分岐のスケール不変信号対雑音比損失は、抽出された目標音声と純粋な音声との間の品質を判断するために用いられ、第2分岐のスケール不変信号対雑音比損失は、抽出された干渉音声と純粋な目標音声との間の品質を判断するために用いられ、クロスモーダル損失は、目標視覚特徴と推定目標音声信号オーディオ特徴を近づけ、目標視覚特徴と推定干渉音声信号オーディオ特徴を遠ざけるために用いられ、損失は以下のように定義され、
TIFF
2025130016000019.tif
58
170
クロスモーダル損失は、2つの分岐のトレーニングプロセスに同時に影響を与え、目標話者の視覚特徴、目標音声特徴及び干渉音声特徴の間で計量学習を行い、ポジティブサンプルの距離を近づけ、ネガティブサンプルの距離を遠ざけ、視覚と聴覚特徴の抽出を制約し、
ここで、γはスケール因子であり、dpは視覚特徴と推定目標音声信号オーディオ特徴との間の余弦距離を表し、dnは視覚特徴と推定干渉音声信号オーディオ特徴との間の余弦距離を表し、dp,dn∈[0,2]であり、marginは2つの距離の間のマージンであり、0.5に設定され、
目標音声分離アルゴリズムにクロスモーダル損失を導入し、目標話者の視覚特徴、目標音声特徴及び干渉音声特徴の間で計量学習を行い、視聴覚一貫性によって視覚と聴覚特徴の抽出を制約し、干渉話者情報を補助情報に変換し、第1分岐の音声抽出を最適化することを特徴とする、クロスモーダル損失に基づく目標音声分離システム。
【請求項6】
メモリと、プロセッサと、メモリに記憶され且つプロセッサで実行されるコンピュータコマンドとを含み、前記コンピュータコマンドがプロセッサによって実行されると、請求項1から請求項4のいずれか1項に記載の方法のステップが完了されることを特徴とする、電子機器。
発明の詳細な説明
【技術分野】
【0001】
本発明は音声処理の技術分野に属し、具体的に、クロスモーダル損失に基づく目標音声分離方法及びシステムに関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
この部分の記述は、本発明に関連する背景技術の情報を提供するに過ぎず、必ずしも従来技術を構成するものではない。
【0003】
目標音声分離課題は、混合オーディオから特定の目標話者の音声を抽出することを指し、音声分離課題の1つの分岐である。複数の話者がいる複雑な場面において、音声分離は、音声認識、話者認識等のアプリケーションの性能を効果的に向上させることができ、リモート会議記録、スマートホーム等のシステムに適用可能である。会話場面における全ての話者の音声を抽出する複数話者分離と異なり、目標音声分離では、1つの出力、即ち、目標話者の推定音声のみがある。目標音声分離は、配列が曖昧であるという複数話者分離の問題を回避することができ、且つ話者数を事前に知る必要がなく、しかしながら、目標信号を指定するための先験知識又は補助情報を提供しなければならない。補助情報の形態によって、目標音声分離は、目標話者の視覚依存や目標話者の登録音声断片依存による抽出補助等の方法に分けることができる。
【0004】
目標音声分離ネットワークは、通常、メインネットワークと補助ネットワークとからなり、そのうち、メインネットワークは、目標話者マスクを学習するために用いられ、補助ネットワークは、区別的な話者埋め込みを学習するために用いられる。目標音声分離ネットワークにおいて、補助ネットワークの出力はメインネットワークに対して重要な指導的意味を有し、補助ネットワークによって作成された話者埋め込みが目標話者と干渉話者を区別できない場合、目標混淆の問題が発生し、即ち、干渉話者が誤って抽出されるか、又は得られた目標話者の音声品質が高くない。また、補助ネットワークで使用される話者タグ、話者事前登録断片等の情報の取得が困難である場合があるため、実用場面に適しない。したがって、補助情報をより適切に利用して、区別的な埋め込みを抽出できれば、目標音声の分離性能がさらに向上する。
【0005】
しかしながら、現在の目標音声分離では、以下の問題があると発明者が把握している。
【0006】
(1)目標混淆が発生しやすい。目標音声と背景雑音又は干渉音声とがスペクトルで重なる場合に、混合信号における異なる音源が周波数領域で互いに干渉するため、干渉話者の音声が抽出されるか、又は抽出された目標話者の音声品質が低い。
【0007】
(2)一部の補助情報の取得が困難である。目標話者の視覚依存による抽出補助の方法では、トレーニング中に、話者の抽出を制約するために、通常、話者アイデンティティタグを取得し、話者分類損失を算出する必要があるが、現実の暮らしではアイデンティティタグの取得が困難であり、目標話者の登録音声断片依存による抽出補助の方法では、予め録音された目標話者の純粋な音声を事前に取得する必要があるため、実用場面に適しない。
【発明の概要】
【0008】
本発明は、上記問題を解決するために、クロスモーダル損失に基づく目標音声分離方法及びシステムを提供する。本発明では、目標話者の視覚情報をモデルに導入することで視覚埋め込みを抽出し、事前登録音声の代わりにオーディオ埋め込み自己抽出の方法を使用し、クロスモーダル損失で話者交差エントロピー損失を置き換えることによって、目標混淆の問題を回避し、目標音声分離の実用場面での適応度を向上させることができる。
【0009】
いくつかの実施例によれば、本発明は、以下の技術的解決手段を採用する。
【0010】
目標話者のビデオを取得し、目標話者のリップシーケンスを抽出するステップと、
混合オーディオ信号を取得するステップと、
プレトレーニングされた目標音声分離モデルを利用し、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得するステップであって、目標音声分離モデルのトレーニングプロセスがクロスモーダル損失を考慮するステップと、を含み、
前記目標音声分離モデルは、トレーニングプロセスで、2つの分岐アーキテクチャがあり、
第1分岐は、視聴覚マルチモーダル目標音声抽出を実現するために用いられ、目標話者のリップシーケンスと混合オーディオ信号に基づき、分離された目標音声信号を取得し、
第2分岐は、シングルモーダル干渉音声抽出を実現するために用いられ、第1分岐の推定目標音声信号と混合オーディオ信号に基づき、分離された干渉音声信号を取得し、取得された干渉音声信号を補助情報とし、クロスモーダル損失によって第1分岐の目標音声の抽出に影響を与え、
クロスモーダル損失は、2つの分岐のトレーニングプロセスに同時に影響を与え、目標話者の視覚特徴、目標音声特徴及び干渉音声特徴の間で計量学習を行い、ポジティブサンプルの距離を近づけ、ネガティブサンプルの距離を遠ざけ、視覚と聴覚特徴の抽出を制約する、クロスモーダル損失に基づく目標音声分離方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
山東大学
クロスモーダル損失に基づく目標音声分離方法及びシステム
25日前
山東大学
絶縁油紙の電気・熱・機械複合劣化の機械的特性の試験方法
8か月前
山東大学
4D呼吸運動合成用の画像レジストレーション方法及びシステム
11日前
山東大学
パルスレーザ衝撃によるフラットホール接続方法並びにその装置及び応用
6か月前
個人
破裂爆発波動体感バルーン
1か月前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社豊田中央研究所
吸音構造体
1日前
株式会社イシダ
商品処理装置
1か月前
日本音響エンジニアリング株式会社
騒音低減装置
1か月前
川崎重工業株式会社
表面材
29日前
株式会社イノアックコーポレーション
吸音材
20日前
株式会社フジタ
環境音快音化システム
1か月前
NOK株式会社
吸音構造体
1か月前
個人
歌唱技術表示装置および歌唱技術表示方法
1か月前
KDDI株式会社
認証装置、認証方法及び認証プログラム
20日前
株式会社第一興商
カラオケ装置
1日前
株式会社第一興商
カラオケ装置
21日前
株式会社第一興商
カラオケ装置
29日前
中原大學
能動騒音除去機能を持つレンジフード
1日前
個人
楽曲検索装置、楽曲検索方法、及び楽曲検索プログラム
1か月前
マツダ株式会社
内燃機関の吸気音増幅装置
1か月前
株式会社JVCケンウッド
クリッピング装置及びクリッピング方法
1日前
トヨタ自動車株式会社
電気自動車
21日前
ローランド株式会社
打楽器および打面の形成方法
28日前
宮澤フル-ト製造株式会社
タンポ及び木管楽器
1か月前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
カシオ計算機株式会社
演奏装置、方法およびプログラム
1か月前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
株式会社SOKEN
吸音構造体
1か月前
ローランド株式会社
打楽器および取付部材の取付方法
28日前
本田技研工業株式会社
能動型効果音発生装置及び能動型効果音生成方法
1か月前
本田技研工業株式会社
音声認識装置、音声認識方法、及びプログラム
1日前
株式会社日立製作所
音声分析システム及び音声分析方法
5日前
公立大学法人広島市立大学
音質改善装置、音質改善方法及びプログラム
1か月前
株式会社東芝
異常要因推定システム、方法及びプログラム
1か月前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ