TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025069160
公報種別
公開特許公報(A)
公開日
2025-04-30
出願番号
2025002871,2023085646
出願日
2025-01-08,2019-02-07
発明の名称
選択されたサジェスチョンによる自動アシスタントへのボイス入力の補足
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G10L
15/22 20060101AFI20250422BHJP(楽器;音響)
要約
【課題】自動アシスタントに向けられた口頭発話を完成させるためのサジェスチョンを、表示モダリティを介して提供すること、および場合によっては、口頭発話が進行中である間に、様々なファクタに基づいて、更新されたサジェスチョンを継続的に提供する。
【解決手段】方法は、ユーザ要求を、進行中の口頭発話のコンテンツおよび任意の選択されたサジェスチョン要素のコンテンツから編集し、ユーザ要求の現在編集された部分が、自動アシスタントを介して実施されることが可能であるとき、ユーザ要求の現在編集された部分に対応する任意のアクションを、自動アシスタントを介して実施し、さらに、アクションの実施から生じる任意のさらなるコンテンツを、任意の認識可能なコンテキストとともに、さらなるサジェスチョンを提供するために使用する。
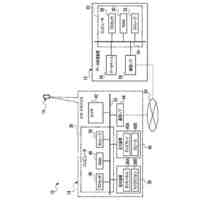
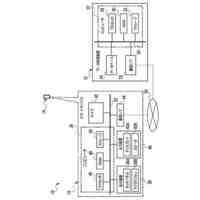
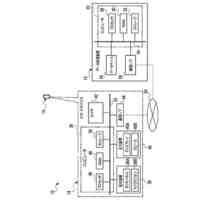
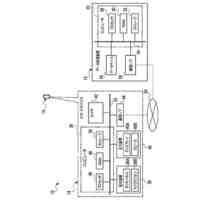
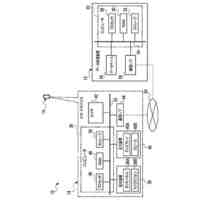
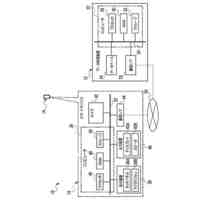
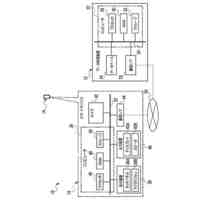
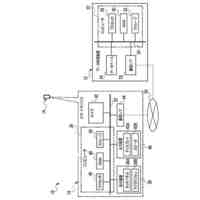
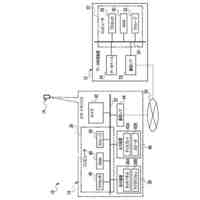
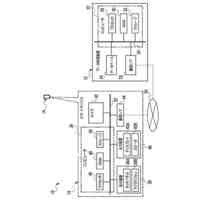
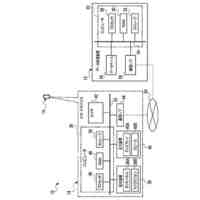
【選択図】図2B
特許請求の範囲
【請求項1】
1つまたは複数のプロセッサによって実施される方法であって、
ユーザによって提供された口頭発話を特徴づけるデータに対して、音声テキスト処理を実施するステップであって、
前記口頭発話が、自然言語コンテンツを含み、ディスプレイパネルに接続されるコンピューティングデバイスの自動アシスタントインターフェースを介して受信される、ステップと、
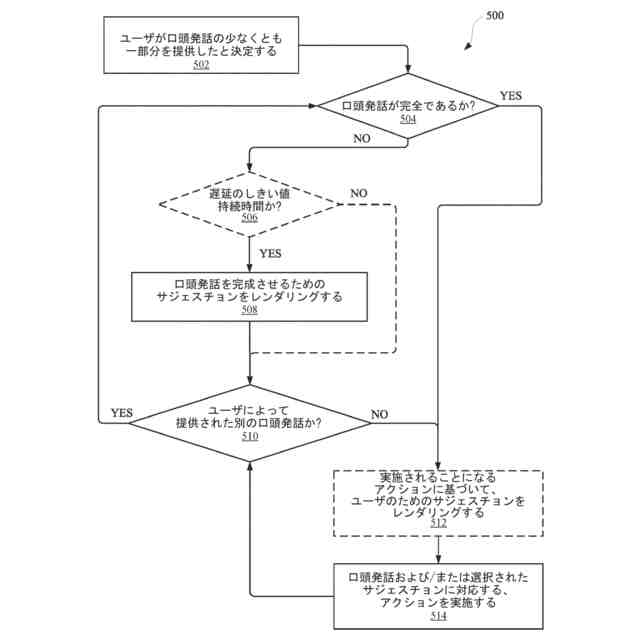
前記口頭発話を特徴づける前記データに対して、前記音声テキスト処理を実施するステップに基づいて、前記口頭発話が完全であるか否かを決定するステップであって、
少なくとも、自動アシスタントが、前記自然言語コンテンツに基づいて、1つまたは複数のアクションが達成されることを引き起こすことができるか否かを決定するステップを含む、ステップと、
前記口頭発話が不完全であると決定されるとき、
前記口頭発話が不完全であるとの決定に応答して、前記コンピューティングデバイスの前記ディスプレイパネルが、1つまたは複数のサジェスチョン要素を提供することを引き起こすステップであって、
前記1つまたは複数のサジェスチョン要素が、前記ユーザによって前記自動アシスタントインターフェースに対して話されるとき、前記自動アシスタントがアクションを完成させることを促進するために動作することを引き起こす、他の自然言語コンテンツを、前記ディスプレイパネルを介して提供する、特定のサジェスチョン要素を含む、ステップと、
前記コンピューティングデバイスの前記ディスプレイパネルが、前記1つまたは複数のサジェスチョン要素を提供することを引き起こすステップの後に、前記ユーザが、前記特定のサジェスチョン要素の前記他の自然言語コンテンツに関連付けられる、別の口頭発話を提供したと決定するステップと、
前記ユーザが前記別の口頭発話を提供したとの決定に応答して、前記口頭発話および前記別の口頭発話の組合せが完全であるか否かを決定するステップと、
前記口頭発話および前記別の口頭発話の前記組合せが完全であると決定されるとき、
前記1つまたは複数のアクションが、前記自然言語コンテンツおよび前記別の口頭発話に基づいて、前記自動アシスタントを介して実施されることを引き起こすステップと
を含む方法。
続きを表示(約 2,200 文字)
【請求項2】
前記ユーザによって提供された前記口頭発話を特徴づける前記データに対して、音声テキスト処理を実施するステップが、前記データから、1つまたは複数の候補テキストセグメントを生成するステップを含み、前記方法が、
前記口頭発話が不完全であると決定されるとき、
前記コンピューティングデバイスの前記ディスプレイパネルが、前記1つまたは複数の候補テキストセグメントのうちの少なくとも1つの候補テキストセグメントのグラフィカル表現を提供することを引き起こすステップ
をさらに含む、請求項1に記載の方法。
【請求項3】
前記口頭発話が、完全であり、前記1つまたは複数のアクションのためのすべての必須パラメータを含むと決定されるとき、
前記コンピューティングデバイスの前記ディスプレイパネルが、前記1つまたは複数の候補テキストセグメントのうちの前記少なくとも1つの候補テキストセグメントの前記グラフィカル表現を提供することをバイパスすること、および、前記1つまたは複数のサジェスチョン要素を提供することをバイパスすることを引き起こすステップ
をさらに含む、請求項2に記載の方法。
【請求項4】
前記口頭発話が完全であると決定されるとき、
1人または複数のユーザによって前記自動アシスタントインターフェースに対して話されるとき、前記ユーザからの前記口頭発話に関連付けられた音声テキスト処理の量と比較して、低減された量の音声テキスト処理を生じ、前記自動アシスタントが前記アクションを完成させることを促進するために動作することを引き起こす、自然言語コマンドを識別するステップと、
前記自然言語コマンドを識別するステップに基づいて、前記自然言語コマンドを特徴づける、1つまたは複数の他のサジェスチョン要素を生成するステップと、
前記口頭発話が完全であるとの決定に少なくとも応答して、前記コンピューティングデバイスの前記ディスプレイパネルが、前記1つまたは複数の他のサジェスチョン要素を提供することを引き起こすステップと
をさらに含む、請求項2または3に記載の方法。
【請求項5】
前記口頭発話が不完全であると決定されるとき、
少なくとも1つのサジェスチョン要素が、前記ディスプレイパネルを介して提供されるとき、前記ユーザから期待される口頭発話のタイプに基づいて、複数の異なる音声テキスト処理モデルから、音声テキスト処理モデルを選択するステップ
をさらに含む、請求項1から4のいずれか一項に記載の方法。
【請求項6】
前記口頭発話が不完全であると決定されるとき、
前記1つまたは複数のサジェスチョン要素の1つまたは複数の用語の方に向けて、および/あるいは、前記1つまたは複数のサジェスチョン要素に対応するコンテンツの1つまたは複数の予想されるタイプの方に向けて、音声テキスト処理にバイアスをかけるステップ
をさらに含む、請求項1から5のいずれか一項に記載の方法。
【請求項7】
口頭入力無音のしきい値持続時間が、前記口頭発話に後続したか否かを決定するステップであって、
前記コンピューティングデバイスの前記ディスプレイパネルが、前記1つまたは複数のサジェスチョン要素を提供することを引き起こすステップが、少なくとも前記口頭入力無音のしきい値持続時間が前記口頭発話に後続したとの決定にさらに応答するものである、ステップ
をさらに含む、請求項1から6のいずれか一項に記載の方法。
【請求項8】
前記音声テキスト処理を実施するステップが、第1の候補テキストセグメントおよび第2の候補テキストセグメントを決定するステップを含み、前記第1の候補テキストセグメントおよび前記第2の候補テキストセグメントが、前記口頭発話の異なる解釈に対応し、
前記特定のサジェスチョン要素が、前記第1の候補テキストセグメントに基づいて決定され、少なくとも1つの他のサジェスチョン要素が、前記第2の候補テキストセグメントに基づいて決定される、請求項1から7のいずれか一項に記載の方法。
【請求項9】
前記コンピューティングデバイスに接続された前記ディスプレイパネルが、前記1つまたは複数のサジェスチョン要素を提供することを引き起こすステップが、
前記コンピューティングデバイスに接続された前記ディスプレイパネルが、前記特定のサジェスチョン要素に隣接して、前記第1の候補テキストセグメントをグラフィカルに表現し、前記少なくとも1つの他のサジェスチョン要素に隣接して、前記第2の候補テキストセグメントをグラフィカルに表現することを引き起こすステップを含む、請求項8に記載の方法。
【請求項10】
前記ユーザが、前記特定のサジェスチョン要素の前記他の自然言語コンテンツに関連付けられる、前記別の口頭発話を提供したと決定するステップが、
前記別の口頭発話に基づいて、前記ユーザが前記第1の候補テキストセグメントを識別したか、前記第2の候補テキストセグメントを識別したかを決定するステップを含む、請求項9に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【背景技術】
【0001】
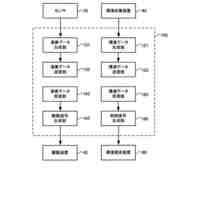
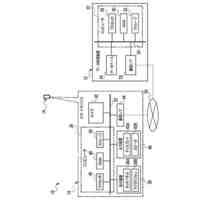
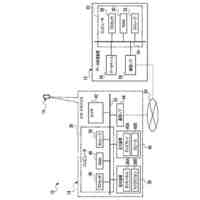
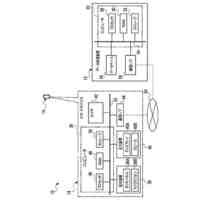
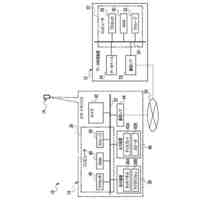
人間は、本明細書では「自動アシスタント」と呼ぶ(「デジタルエージェント」、「チャットボット」、「対話型パーソナルアシスタント」、「インテリジェントパーソナルアシスタント」、「アシスタントアプリケーション」、「会話エージェント」などとも呼ぶ)、対話型ソフトウェアアプリケーションとのヒューマンコンピュータダイアログに携わることがある。たとえば、人間(自動アシスタントと対話するとき、「ユーザ」と呼ぶことがある)は、場合によってはテキストに変換され、次いで処理され得る、口頭自然言語入力(すなわち、発話)を使用して、および/またはテキストの(たとえば、タイピングされた)自然言語入力を提供することによって、コマンドおよび/または要求を自動アシスタントに提供することがある。自動アシスタントは、可聴および/または視覚的ユーザインターフェース出力を含み得る、応答ユーザインターフェース出力を提供することによって、要求に応答する。したがって、自動アシスタントは、ボイスベースのユーザインターフェースを提供し得る。
続きを表示(約 8,900 文字)
【0002】
いくつかの事例では、ユーザは、自動アシスタントアクションの実施を引き起こすように、ユーザによって意図されるが、意図された自動アシスタントアクションの実施を生じない、口頭発話(spoken utterance)を提供することがある。たとえば、口頭発話は、自動アシスタントによって理解可能ではない構文において提供されることがあり、かつ/または、自動アシスタントアクションのための必須パラメータを欠くことがある。結果として、自動アシスタントは、口頭発話を完全に処理すること、および、それが自動アシスタントアクションのための要求であると決定することができないことがある。このことは、自動アシスタントが口頭発話に対する応答を提供しないこと、または、「すみません、その役には立てません」などの応答におけるエラー、および/もしくはエラー音を提供することにつながる。自動アシスタントが、口頭発話の意図されたアクションを実施することに失敗するにもかかわらず、様々なコンピュータおよび/またはネットワークリソースが、それにもかかわらず、口頭発話の処理、および適切なアクションを解決しようとする試みにおいて消費される。たとえば、口頭発話に対応するオーディオデータは、送信される、音声テキスト処理を受ける、かつ/または自然言語処理を受けることがあり得る。リソースのそのような消費は、意図された自動アシスタントアクションが実施されないので、無駄であり、ユーザは、意図された自動アシスタントアクションの実施を後で求めるとき、再構築された口頭発話を提供するように試みる可能性が高くなる。さらに、そのような再構築された口頭発話もまた、処理されなければならないことになる。さらに、これによって、ユーザが代わりに好適な口頭発話を自動アシスタントに最初に提供した場合と比較して、自動アシスタントアクションの実施においてレイテンシが生じる。
【発明の概要】
【課題を解決するための手段】
【0003】
本明細書で説明する実装形態は、自動アシスタントに向けられた口頭発話を完成させるためのサジェスチョンを、表示モダリティを介して提供すること、および場合によっては、口頭発話が進行中である間に、様々なファクタに基づいて、更新されたサジェスチョンを継続的に提供することに関する。たとえば、サジェスチョンは、自動アシスタントが、ユーザによって最初に意図された自動アシスタントアクションを総合的に実施することを引き起こすようになる、実行可能なダイアログフレーズを開発すると同時に、ユーザと自動アシスタントとの間の対話の合理化も行うことを促進するために提供され得る。追加または代替として、サジェスチョンは、ユーザが自動アシスタントとの現在のダイアログセッション、および/または後続のダイアログセッションに参加することになる、頻度および/または時間の長さを低減することができる、アクションを実施するために、自動アシスタントを採用するようにユーザに勧めることを促進するために提供され得る。
【0004】
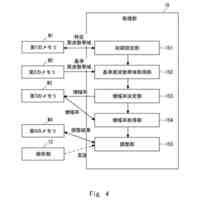
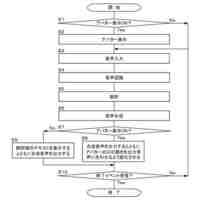
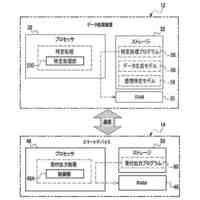
いくつかの実装形態では、ユーザと自動アシスタントとの間のダイアログセッションの間に、ユーザは、自動アシスタントが1つまたは複数のアクションを実施することを引き起こすことを促進するために、口頭発話を提供することができる。口頭発話は、オーディオデータと、各々が口頭発話の対応する解釈である1つまたは複数のテキストセグメントを生成するために、オーディオデータ上で実施された音声テキスト処理とによって取り込まれ得る。1つまたは複数のテキストセグメントは、口頭発話が完全な要求および/またはアクション可能な要求に対応するか否かを決定するために、処理され得る。本明細書で使用する「完全な要求」または「アクション可能な要求」は、自動アシスタントによって完全に処理されると、1つまたは複数の対応する自動アシスタントアクションの実施を引き起こすものであり、ここで、実施された自動アシスタントアクションは、デフォルトエラータイプアクションではない(たとえば、「すみません、その役には立てません」という可聴応答ではない)。たとえば、アクション可能な要求は、1つまたは複数のスマートデバイスが制御されることを引き起こすことができ、特定の可聴および/またはグラフィカルコンテンツがレンダリングされることを引き起こすことができる、などである。口頭発話が不完全な要求に対応すると決定されるとき、1つまたは複数のテキストセグメントは、要求を完成させるための1つまたは複数のサジェスチョンを決定および提供するために、さらに処理され得る。1つまたは複数のサジェスチョンのうちの各サジェスチョンは、1つまたは複数のテキストセグメントのうちの対応するものと組み合わせられると、完全な要求を提供する、追加のテキストを含み得る。言い換えれば、ユーザが、特定のサジェスチョンのテキスト(または、特定のサジェスチョンに基づくテキストに概して適合する代替テキスト)を復唱することによって、自分のダイアログセッションを継続した場合、自動アシスタントは、対応する自動アシスタントアクションを実施することになる。したがって、サジェスチョンの生成は、タスクを実施することにおいて、ユーザを支援する。ユーザが要求を入力中である間、ユーザには、アシスタントとの対話においてユーザをガイドする情報が提供される。ユーザに提示される情報は、ユーザの既存の入力に基づくものであり、したがって、ユーザに情報を提供するために、客観分析を使用する。したがって、ユーザには、タスクを行うことにおいてユーザを支援するために、客観的に関連のある情報が提供される。
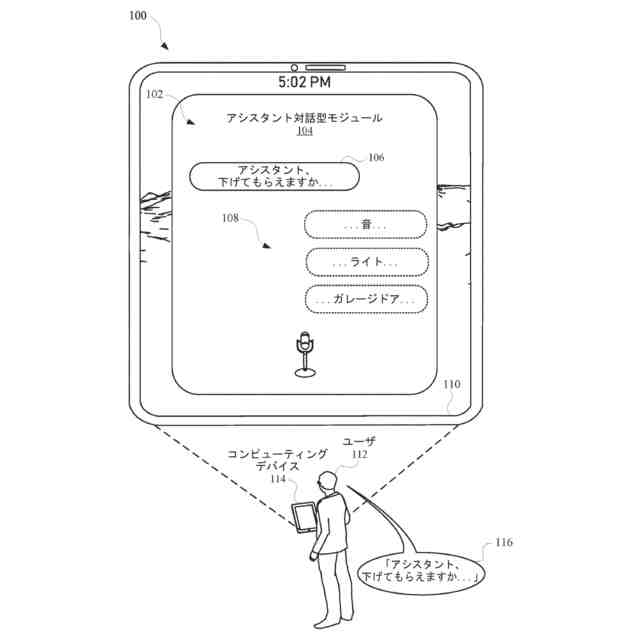
【0005】
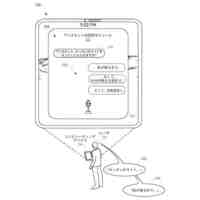
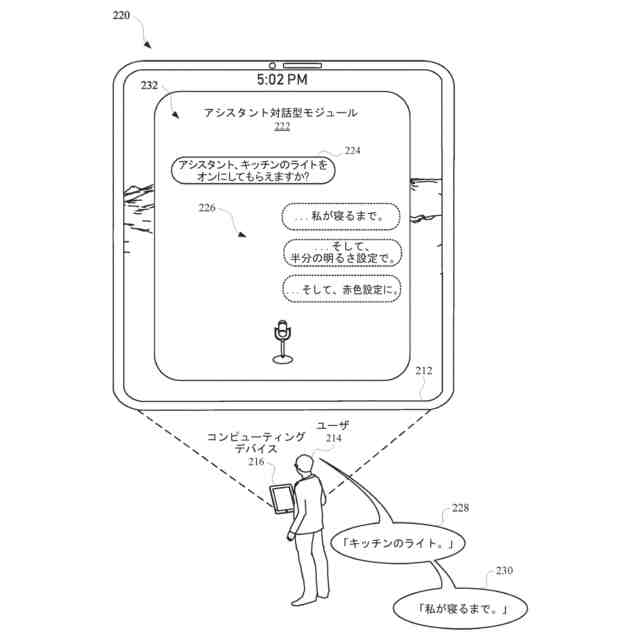
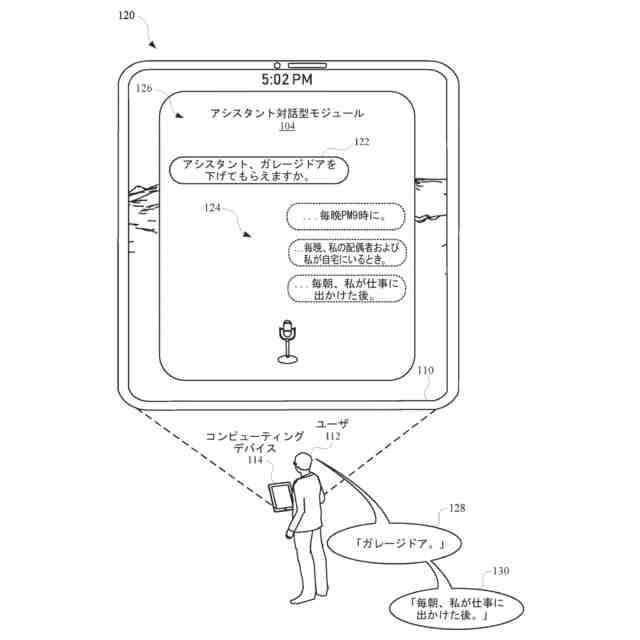
いくつかの実装形態では、コンピューティングデバイスは、口頭発話の異なる解釈を生成することができ、それらの解釈における変形形態は、口頭発話に応答して提供されるサジェスチョンへの対応する変形形態を生じることができる。たとえば、「アシスタント、変更してもらえますか...」などの口頭発話は、コンピューティングデバイスによる複数の解釈に対応し得る。上述の口頭発話は、自動アシスタントを介してIoTデバイス設定を変更するための要求として、または、自動アシスタントを介してアプリケーション設定を変更するための要求として解釈され得る。各解釈は、コンピューティングデバイスと通信しているディスプレイパネルを介して、ユーザに提示され得る、対応するサジェスチョンを生成するために処理され得る。たとえば、コンピューティングデバイスは、ディスプレイパネルが、口頭発話の両方の解釈に基づくサジェスチョンのリストとともに、口頭発話の最初のテキスト(たとえば、「アシスタント、変更してもらえますか...」)を示すことを引き起こすことができる。サジェスチョンは、ある解釈に基づく少なくとも1つのサジェスチョンと、別の解釈に基づく少なくとも1つの他のサジェスチョンとを含み得る。
【0006】
たとえば、「IoTデバイス設定を変更する」解釈に基づく少なくとも1つのサジェスチョンは、ユーザによって話されると、元の口頭発話を補足するテキストであり得る、「サーモスタットを72に」であり得る。一例として、ディスプレイパネルは、少なくとも1つのサジェスチョンのテキストを話すユーザに応答して、元の口頭発話、および少なくとも1つのサジェスチョンを一緒に提示することができる。言い換えれば、ディスプレイパネルは、以下のテキスト、すなわち、「アシスタント、サーモスタットを72に変更してもらえますか」を提示することができる。ユーザは、提示されたテキストを見て、その部分(すなわち、「サーモスタットを72に」)がサジェストされたものであり、自分の元の口頭発話(すなわち、「アシスタント、変更してもらえますか...」)内に含まれていなかったことを識別することができる。サジェストされた部分を識別すると、ユーザは、サジェストされた部分のテキストを復唱し、自動アシスタントが、ユーザのサーモスタットの設定を72に変更することなどのアクションを完成させることを促進するために作用することを引き起こすことができる。いくつかの実装形態では、ディスプレイパネルは、サジェスチョンとして、サジェストされた、まだ話されていない部分(たとえば、「アシスタント、してもらえますか」を提示することなく、「サーモスタットを72に」)のみを含む、テキストを提示することができる。これによって、サジェスチョンを容易に一瞥することができるようになり、ユーザがサジェスチョンを迅速に見ること、および、「サーモスタットを72に」または(サジェスチョンとは異なるが、サジェスチョンに基づいて確認可能である)「サーモスタットを70に」というさらなる口頭入力など、ユーザがアクション可能な要求を構築するために提供することができる、さらなる口頭入力を確認することが可能になり得る。
【0007】
様々な実装形態では、サジェスチョンのテキスト部分は、場合によっては、サジェスチョンのテキスト部分に適合しているさらなる口頭入力を提供する結果として実施されることになるアクションを示す、アイコンまたは他のグラフィカル要素と組み合わせて提示され得る。一例として、サジェスチョンは、サジェスチョンに適合しているさらなる口頭入力が、サーモスタットの設定点における変更を生じるようになることを示すために、サーモスタットのグラフィカル指示、および上下の矢印とともに、「サーモスタットを72に変更してください」というテキスト部分を含み得る。別の例として、サジェスチョンは、サジェスチョンに適合しているさらなる口頭入力が、テレビにおけるストリーミングコンテンツの再生を生じるようになることを示すために、再生アイコンを内部に有するテレビの輪郭とともに、「リビングルームのTVでTV局を再生して」というテキスト部分を含み得る。また別の例として、サジェスチョンは、サジェスチョンに適合しているさらなる口頭入力が、ライトをオフにすることを生じるようになることを示すために、その上に重ねられたXを有する電球アイコンとともに、「リビングルームのライトをオフにして」を含み得る。そのようなアイコンによっても、サジェスチョンをより容易に一瞥することができるようになり、ユーザが最初にアイコンを迅速に見ること、および、アイコンがユーザの所望のアクションに適合している場合、サジェスチョンのテキスト部分を見ることが可能になり得る。これによって、ユーザが、複数の同時に提示されたサジェスチョンのグラフィカル要素を(対応するテキスト部分を最初に読むことなく)迅速に一瞥して、ユーザの意図に適合するものを確認し、次いで、そのものの対応するテキスト部分のみを読み取ることが可能になり得る。これによって、ユーザが複数のサジェスチョンを提示されるとき、さらなる口頭入力を提供する際のレイテンシを低減することができ、結果的に、生じたアクションの実施のレイテンシが低減される。
【0008】
いくつかの実装形態では、口頭発話は、ユーザが特定の語を明確に述べた、かつ/または発音した方法の結果として、異なるように解釈され得る。たとえば、「アシスタント、変更してもらえますか...」という上述の口頭発話を受信するコンピューティングデバイスは、X%の確実性とともに、口頭発話が「変更する」という語を含むこと、およびY%の確実性(ただし、Yは、X未満である)とともに、口頭発話が「整理する」という語を含み、したがって、「整理する」機能を実施するための要求を指すことを決定することができる。たとえば、口頭発話の音声テキスト処理は、異なる確実性をもつ、2つの別個の解釈(「変更する」および「整理する」)を生じることができる。結果として、口頭発話に応答するタスクを課せられる自動アシスタントは、各解釈(「変更する」および「整理する」)に基づくサジェスチョンを提示することができる。たとえば、自動アシスタントは、「変更する」解釈に対応する「...サーモスタットを72に」などの第1のサジェスチョンと、「整理する」解釈に対応する「...マイデスクトップファイルフォルダ」などの第2のサジェスチョンとをグラフィカルに提示することができる。さらに、ユーザが「サーモスタットを72に」(または、「サーモスタットを80に」などの同様のコンテンツ)を復唱することによって、第1のサジェスチョンのコンテンツを後で復唱する場合、ユーザは、「変更する」機能が自動アシスタントを介して(および、ユーザのさらなる復唱に基づいて)実施されることを引き起こすことができる。しかしながら、ユーザが「マイデスクトップファイルフォルダ」(または、「マイドキュメントフォルダ」などの同様のコンテンツ)を復唱することによって、第2のサジェスチョンのコンテンツを後で復唱する場合、ユーザは、「整理する」機能が自動アシスタントを介して(および、ユーザのさらなる復唱に基づいて)実施されることを引き起こすことができる。言い換えれば、自動アシスタントは、復唱されたサジェスチョンに適合する解釈(「変更する」または「整理する」)を利用することになる。たとえば、「整理する」が20%の確率のみで予測され、「変更する」が80%の確率で予測された場合でも、それにもかかわらず、ユーザが「マイデスクトップファイルフォルダ」とさらに話す場合、「整理する」が利用され得る。別の例として、ならびに「変更する」および「整理する」例の変形態として、「サーモスタットを75に変更してください」という第1のサジェスチョン、および「マイデスクトップファイルフォルダを整理してください」という第2のサジェスチョンが提示され得る。ユーザが、タッチ入力を通して「マイデスクトップファイルフォルダを整理してください」を選択するか、または「マイデスクトップファイルフォルダを整理してください」もしくは「第2のもの」など、さらなる口頭入力を提供する場合、「整理する」解釈が、「変更する」解釈の代わりに利用されることになる。言い換えれば、「変更する」が、より高い確率に基づいて、正確な解釈として最初に選択されるにもかかわらず、「整理する」は、それにもかかわらず、「整理する」サジェスチョンに向けられたユーザ選択またはさらなる口頭入力に基づいて、その選択に取って代わることがある。これらおよび他の方法において、音声テキスト精度を向上させることができ、より小さい確実性の解釈が、いくつかの状況において利用され得る。これによって、そうでない場合、最初の口頭発話の不正確な解釈が選択され、ユーザが、正確な解釈が選択されるように試みて、自分の最初の口頭発話を繰り返さなければならなかった場合に費やされ得る、計算リソースを保護することができる。さらに、これによって、ユーザが同じことを繰り返して言うことが減り、自動アシスタントが可聴応答をレンダリングするまで待機するようになるとすれば、ユーザが自動アシスタントに関与するのに費やす時間の量を低減することができる。
【0009】
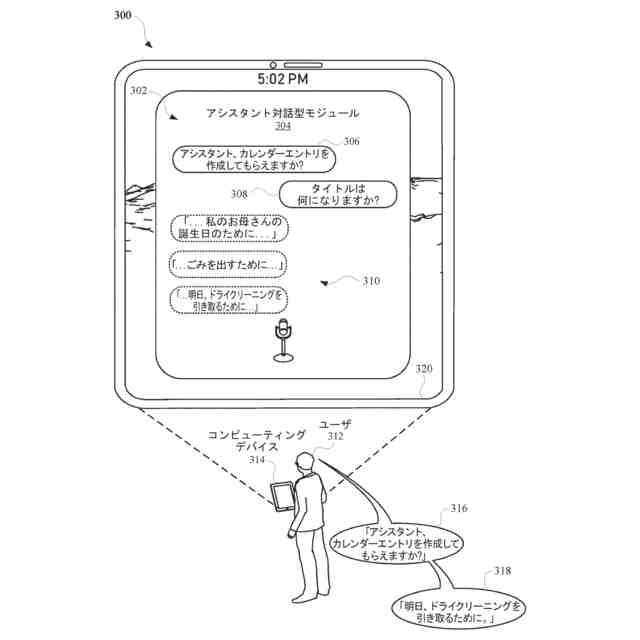
いくつかの実装形態では、提供されたサジェスチョン要素は、サジェスチョンの提供に応答して受信されたさらなる口頭発話の音声テキスト処理にバイアスをかけるための基礎として使用され得る。たとえば、音声テキスト処理には、提供されたサジェスチョン要素の用語の方に、および/または、サジェスチョンに対応するコンテンツの予想されるカテゴリーもしくは他のタイプに適合する用語の方にバイアスをかけることができる。たとえば、「[ミュージシャンの名前]」という、提供されたサジェスチョンの場合、音声テキスト処理には、ミュージシャンの名前の方に(一般に、またはユーザのライブラリにおけるミュージシャンに)バイアスをかけることができ、「2:00に」という、提供されたサジェスチョンの場合、音声テキスト処理には、「2:00」の方に、またはより一般的に時間の方にバイアスをかけることができ、「[スマートデバイス]」という、提供されたサジェスチョンの場合、音声テキスト処理には、(たとえば、ユーザの記憶されたデバイストポロジーから確認されるような)ユーザのスマートデバイスの名前の方にバイアスをかけることができる。音声テキスト処理には、たとえば、音声テキスト処理を実施する際に使用するための(複数の候補音声テキストモデルからの)特定の音声テキストモデルを選択すること、ある用語に対応する候補変換に基づいて、(音声テキスト処理の間に生成された)候補変換のスコアを高めること、ある用語に対応する(音声テキスト処理において使用された)状態復号グラフ(state decoding graph)のパスを高めることによって、および/または追加のもしくは代替音声テキストバイアス技法によって、ある用語の方にバイアスをかけることができる。一例として、ユーザは、「アシスタント、~のためのカレンダーイベントを設定して」などの最初の口頭発話を提供することができ、最初の口頭発話の受信に応答して、自動アシスタントは、複数のサジェスチョン要素がコンピューティングデバイスのディスプレイパネルにおいて現れることを引き起こすことができる。サジェスチョン要素は、たとえば、「8月...9月...[現在の月]...」などであることがあり、ユーザは、「8月」などの後続の口頭発話を提供することによって、特定のサジェスチョン要素を選択することができる。サジェスチョン要素が1月~12月を含むとの決定に応答して、自動アシスタントは、後続の口頭発話の音声テキスト処理に、1月~12月の方にバイアスをかけることができる。別の例として、数値入力を含む(または、示す)サジェスチョン要素の提供に応答して、音声テキスト処理には、数値の方にバイアスをかけることができる。これらおよび他の方法において、後続の発話の音声テキスト処理には、提供されたサジェスチョン要素の方を優先してバイアスをかけることができ、それによって、音声テキスト処理から予測されたテキストが正確である確率を高めることができる。これによって、そうでない場合、予測されたテキストが不正確であった場合に必要となる(たとえば、不正確な解釈を訂正するための、ユーザからのさらなる入力に基づく)、さらなるダイアログの機会の発生を軽減することができる。
【0010】
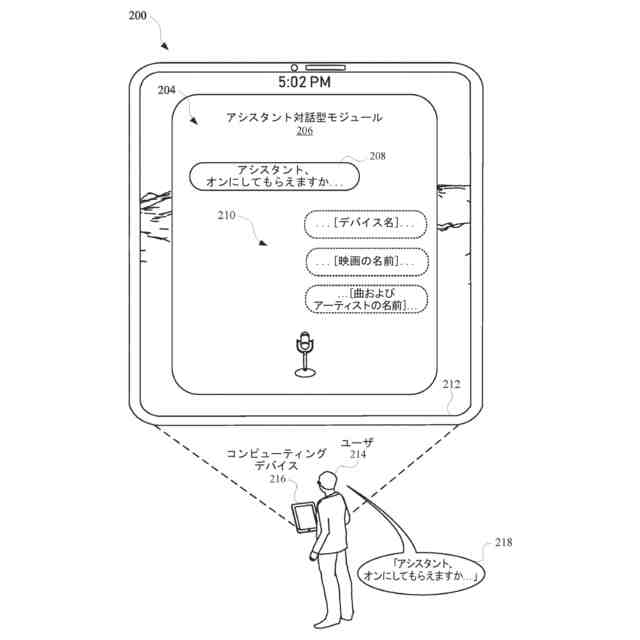
いくつかの実装形態では、自動アシスタントに特定の要求を完成させるためのサジェスチョン要素を提供するためのタイミングは、それにおいてユーザが特定の要求を開始したコンテキストに基づき得る。たとえば、ユーザが自分の車両を運転中に、口頭発話を介して、要求の少なくとも一部分を提供したとき、自動アシスタントは、ユーザが車両を運転中であると決定し、要求を完成させるためのサジェスチョンを表示することを遅延させることができる。このようにして、ユーザは、グラフィックスが車両内のディスプレイパネルにおいて提示されることによって、気を散らされる頻度がより低くなる。追加または代替として、サジェスチョン要素のコンテンツ(たとえば、候補テキストセグメント)もまた、それにおいてユーザが口頭発話を開始したコンテキストに基づき得る。たとえば、自動アシスタントは、ユーザからの事前許可とともに、ユーザが自分のリビングルームから「アシスタント、オンにして...」などの口頭発話を提供したと決定することができる。それに応答して、自動アシスタントは、コンピューティングデバイスが、ユーザのリビングルーム内の特定のデバイスを識別するサジェスチョン要素を生成することを引き起こすことができる。サジェスチョン要素は、「リビングルームのTV...リビングルームのライト...リビングルームのステレオ」などの自然言語コンテンツを含み得る。ユーザは、「リビングルームのライト」などの後続の口頭発話を提供することによって、サジェスチョン要素のうちの1つの選択を行うことができ、それに応答して、自動アシスタントは、リビングルームのライトをオンにさせることができる。いくつかの実装形態では、サジェスチョン要素が識別するデバイスは、ユーザに関連付けられた様々なデバイス間の関係、および/または自宅もしくはオフィスなど、ユーザのロケーション内のコンピューティングデバイスの配置を特徴づける、デバイストポロジーデータに基づき得る。デバイストポロジーデータは、ロケーション内の様々なエリアのための識別子、ならびに、デバイスが各エリア内にあるか否かを特徴づけるデバイス識別子を含み得る。たとえば、デバイストポロジーデータは、「リビングルーム」などのエリアを識別し、また、「TV」、「ライト」、および「ステレオ」など、リビングルーム内のデバイスを識別することができる。したがって、ユーザによる「アシスタント、オンにして」という上述の発話の提供に応答して、そのエリア内の特定のデバイスに対応するサジェスチョンを提供するために、デバイストポロジーがアクセスされ、ユーザがいるエリアと比較され得る(たとえば、デバイストポロジーデータによって「リビングルーム」内にあるとして定義されたデバイスを介して、発話が提供されることに基づいて、「リビングルーム」を識別する)。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
グーグル エルエルシー
選択されたサジェスチョンによる自動アシスタントへのボイス入力の補足
6日前
個人
リアルタイム翻訳システム
19日前
個人
10デジタルサラウンドラジオ
4日前
株式会社SOU
保護具
1か月前
三井化学株式会社
防音構造
26日前
三井化学株式会社
防音構造体
27日前
三井化学株式会社
遮音構造体
13日前
東レ・セラニーズ株式会社
混繊不織布
1か月前
スマートライフサプライ合同会社
楽器スタンド
1か月前
トヨタ自動車株式会社
音声制御装置
12日前
中強光電股ふん有限公司
電子システム及びその制御方法
1か月前
株式会社第一興商
カラオケ装置
28日前
トヨタ自動車株式会社
情報処理装置
19日前
ドリックス株式会社
消音パネル
29日前
ヤマハ株式会社
鍵盤楽器
12日前
カシオ計算機株式会社
電子機器
1か月前
株式会社JVCケンウッド
聴音装置、聴音方法及びプログラム
1か月前
株式会社しくみ
音声翻訳プログラム
14日前
カシオ計算機株式会社
電子鍵盤楽器
1か月前
株式会社Gottsu
サキソフォーン向けねじ込み式スクリュー
6日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
28日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
27日前
ソフトバンクグループ株式会社
システム
28日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ