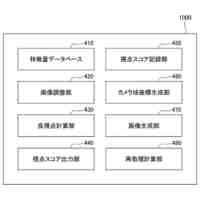
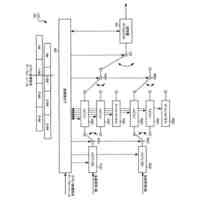
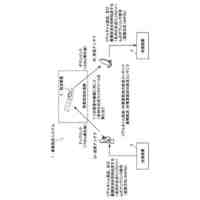
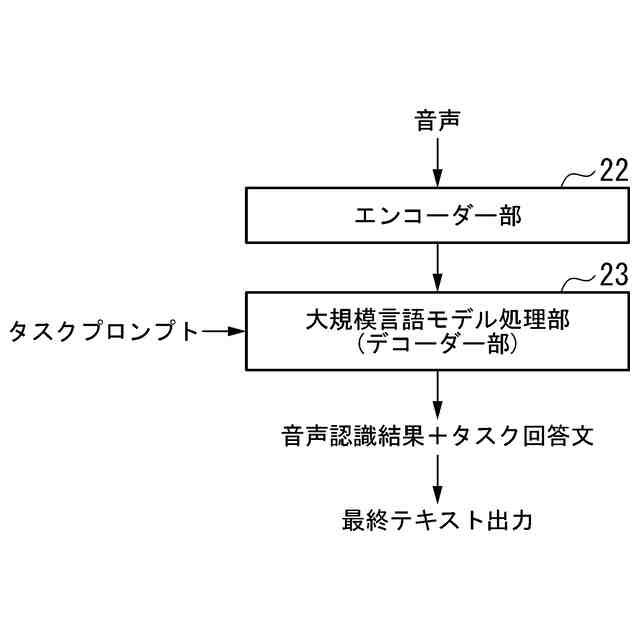
発明の詳細な説明【技術分野】 【0001】 本発明は、音声言語処理装置およびプログラムに関する。 続きを表示(約 3,600 文字)【背景技術】 【0002】 機械学習を行うことのできる大規模言語モデルを用いて、入力される言語(テキスト等)に基づく様々なタスクの処理を行う研究がなされている。 【0003】 非特許文献1では、次単語予測タスクのための事前学習を行い、様々なタスクを解くことのできる大規模言語モデルGPT3について記載されている。 【0004】 非特許文献2に記載されている技術では、大規模言語モデルを音声認識デコーダーに導入している。そして、音声認識デコーダーに、音声の前情報をプロンプトとして入力することによって精度を向上させている。 【0005】 非特許文献3に記載されている技術では、デコーダーモデル(デコーダー部分のみを使用した大規模言語モデル)Palm-2を利用して、マルチモーダル生成モデルAudioPaLMを提案している。具体的には、Palm-2の入力埋め込み層を音声入力用に拡張し、音声入力をトークン化して大規模言語モデルへの入力としている。 【0006】 非特許文献4には、大規模言語モデルに人間がフィードバックを行い人間の意図に沿ったテキストを生成する技術が記載されている。 【0007】 非特許文献5に記載されている技術は、言語モデルにゲーティング機構(gating mechanism)を利用して画像エンコーダー(visual encoder)を導入した視覚言語モデル(vision language model)Flamingoを提案している。この技術では、画像エンコーダーから渡される画像モーダル情報を利用したテキスト生成を可能にしている。 【先行技術文献】 【非特許文献】 【0008】 Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei,“Language Models are Few-Shot Learners”,arXiv:2005.14165v4 [cs.CL],22 Jul 2020,https://arxiv.org/abs/2005.14165. Yuang Li, Yu Wu, Jinyu Li, Shujie Liu,“PROMPTING LARGE LANGUAGE MODELS FOR ZERO-SHOT DOMAIN ADAPTATION IN SPEECH RECOGNITION”,arXiv:2306.16007v1 [cs.CL],28 Jun 2023,https://arxiv.org/abs/2306.16007. Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalan Borsos, Felix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Mihajlo Velimirovic, Damien Vincent, Jiahui Yu, Yongqiang Wang, Vicky Zayats, Neil Zeghidour, Yu Zhang, Zhishuai Zhang, Lukas Zilka, Christian Frank,“AudioPaLM: A Large Language Model That Can Speak and Listen”,arXiv:2306.12925v1 [cs.CL],22 Jun 2023,https://arxiv.org/abs/2306.12925. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe,“Training language models to follow instructions with human feedback”,arXiv:2203.02155v1 [cs.CL],4 Mar 2022,https://arxiv.org/abs/2203.02155. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan,“Flamingo: a Visual Language Model for Few-Shot Learning”,arXiv:2204.14198v2 [cs.CV],15 Nov 2022,https://arxiv.org/abs/2204.14198. 【発明の概要】 【発明が解決しようとする課題】 【0009】 しかしながら、従来技術では、音声言語を入力することによって様々なタスクを実行させるためには、問題がある。 【0010】 従来技術を用いる場合に、例えば音声認識処理システムと、それに後続するタスクの処理(例えば、機械対話や機械翻訳等)のシステムとを組み合わせることにより、音声対話や音声翻訳等のアプリケーションが実現可能である。しかしながら、従来技術をそのまま用いた場合には、複数のモデルを組み合わせることによって誤りが伝播してしまい、処理の精度が悪化するという問題がある。また、音声として発話された言語を一度音声認識処理によってテキスト化してしまうと、元の音声に含まれていた重要な情報(韻律や、男声/女声の区別や、大人の声/子供の声の区別等)が失われてしまい、後続のタスクに利用することができない。 (【0011】以降は省略されています) この特許をJ-PlatPat(特許庁公式サイト)で参照する






 特許ウォッチ
特許ウォッチ