TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025059613
公報種別
公開特許公報(A)
公開日
2025-04-10
出願番号
2023169815
出願日
2023-09-29
発明の名称
音声認識モデル追加学習装置、音声認識モデル追加学習方法、及びプログラム
出願人
NTTテクノクロス株式会社
,
日本電信電話株式会社
代理人
個人
,
個人
主分類
G10L
15/06 20130101AFI20250403BHJP(楽器;音響)
要約
【課題】音声認識モデルに未知語を認識させるための追加学習コストを削減できる技術を提供すること。
【解決手段】本開示の一態様による音声認識モデル追加学習装置は、未知語が含まれるテキストを用いて、前記テキストを読み上げた合成音声を生成する音声合成部と、前記テキストを教師データとして、前記合成音声を学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習するモデル学習部と、を有する。
【選択図】図1
特許請求の範囲
【請求項1】
未知語が含まれるテキストを用いて、前記テキストを読み上げた合成音声を生成する音声合成部と、
前記テキストを教師データとして、前記合成音声を学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習するモデル学習部と、
を有する音声認識モデル追加学習装置。
続きを表示(約 930 文字)
【請求項2】
前記合成音声に対して雑音を重畳させた雑音重畳合成音声を生成する雑音重畳部を更に有し、
前記音声合成部は、
前記テキストを読み上げる話者、前記テキストを読み上げるときの話速、及び前記テキストを読み上げるときの抑揚の少なくとも1つを表すパラメータの値を変化させることにより、前記テキストから複数の合成音声を生成し、
前記モデル学習部と、
前記合成音声を前記学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化し、かつ、前記雑音重畳合成音声を前記学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習する、請求項1に記載の音声認識モデル追加学習装置。
【請求項3】
未知語が含まれる文書が与えられると、前記文書が構造化されている場合には構造毎に前記文書からテキストを抽出し、前記文書が構造化されていない場合には文単位に前記文書からテキストを抽出するテキスト抽出部を更に有し、
前記音声合成部は、
前記テキスト抽出部によって抽出されたテキストを用いて、前記合成音声を生成する、請求項1又は2に記載の音声認識モデル追加学習装置。
【請求項4】
未知語が含まれるテキストを用いて、前記テキストを読み上げた合成音声を生成する音声合成手順と、
前記テキストを教師データとして、前記合成音声を学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習するモデル学習手順と、
をコンピュータが実行する音声認識モデル追加学習方法。
【請求項5】
未知語が含まれるテキストを用いて、前記テキストを読み上げた合成音声を生成する音声合成手順と、
前記テキストを教師データとして、前記合成音声を学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習するモデル学習手順と、
をコンピュータに実行させるプログラム。
発明の詳細な説明
【技術分野】
【0001】
本開示は、音声認識モデル追加学習装置、音声認識モデル追加学習方法、及びプログラムに関する。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
ニューラルネットワークで実現されるend-to-endの音声認識モデルが従来から知られており、そのモデル精度を向上させるために様々な技術が提案されている。例えば、特許文献1には、少ない教師データで精度の高いend-to-endの音声認識モデルを学習できる技術が記載されている。
【先行技術文献】
【特許文献】
【0003】
特開2021-39218号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来技術では、例えば、専門用語等の未知語を正しく認識させるためには、未知語を含む音声とその書き起こしテキストを準備した上で音声認識モデルを追加学習(チューニング)する必要があり、追加学習に要するコストが高かった。
【0005】
本開示は、上記の点に鑑みてなされたもので、音声認識モデルに未知語を認識させるための追加学習コストを削減できる技術を提供する。
【課題を解決するための手段】
【0006】
本開示の一態様による音声認識モデル追加学習装置は、未知語が含まれるテキストを用いて、前記テキストを読み上げた合成音声を生成する音声合成部と、前記テキストを教師データとして、前記合成音声を学習済み音声認識モデルにより認識した結果と、前記教師データとの誤差を最小化するように、前記学習済み音声認識モデルを追加学習するモデル学習部と、を有する。
【発明の効果】
【0007】
音声認識モデルに未知語を認識させるための追加学習コストを削減できる技術が提供される。
【図面の簡単な説明】
【0008】
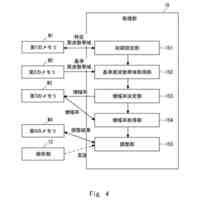
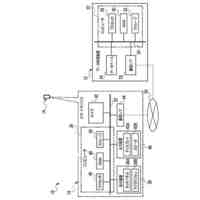
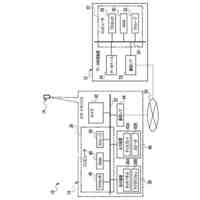
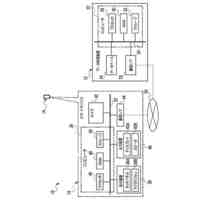
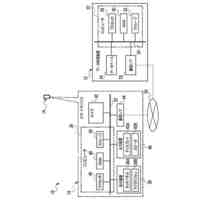
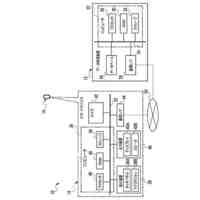
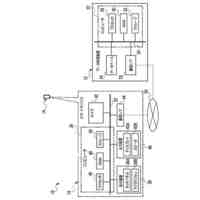
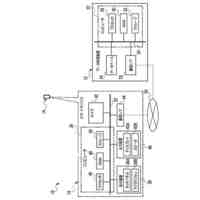
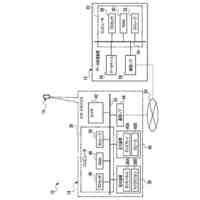
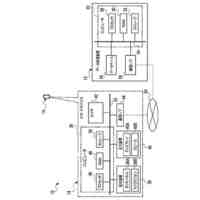
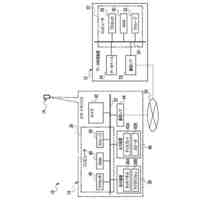
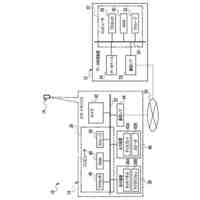
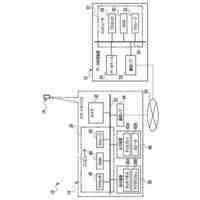
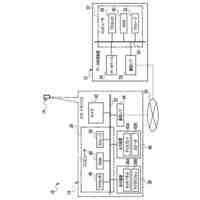
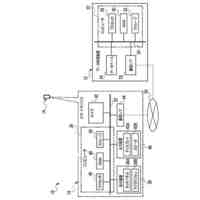
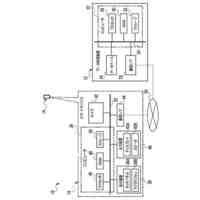
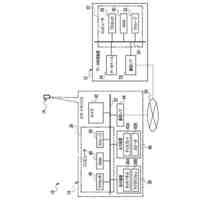
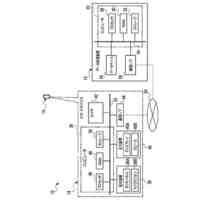
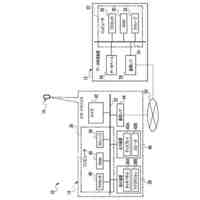
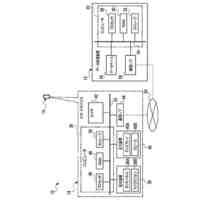
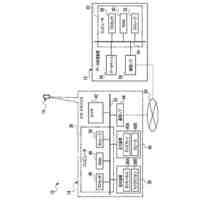
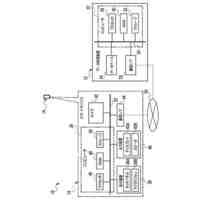
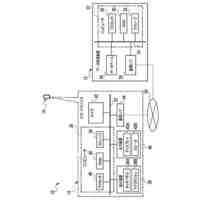
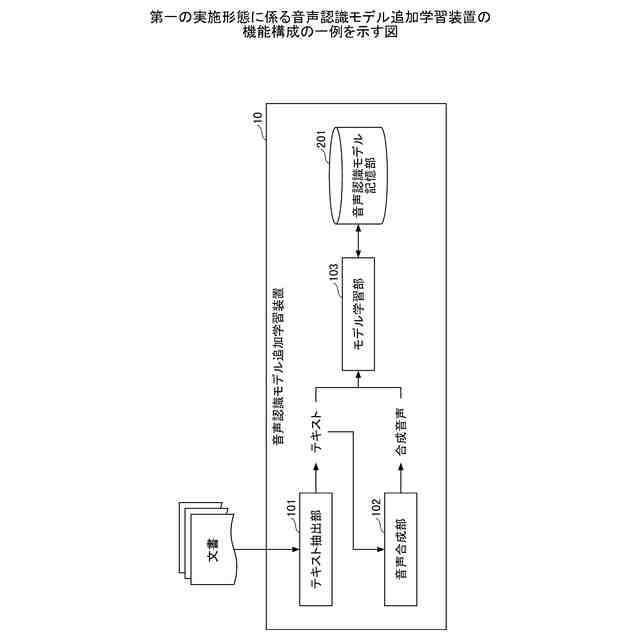
第一の実施形態に係る音声認識モデル追加学習装置の機能構成の一例を示す図である。
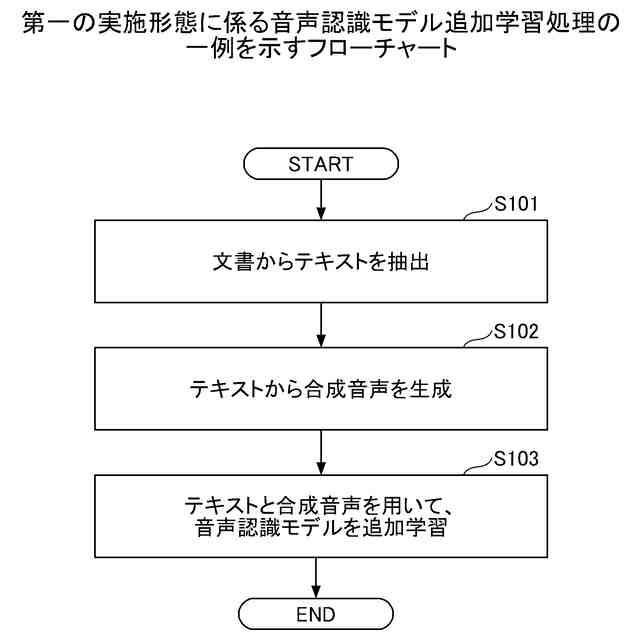
第一の実施形態に係る音声認識モデル追加学習処理の一例を示すフローチャートである。
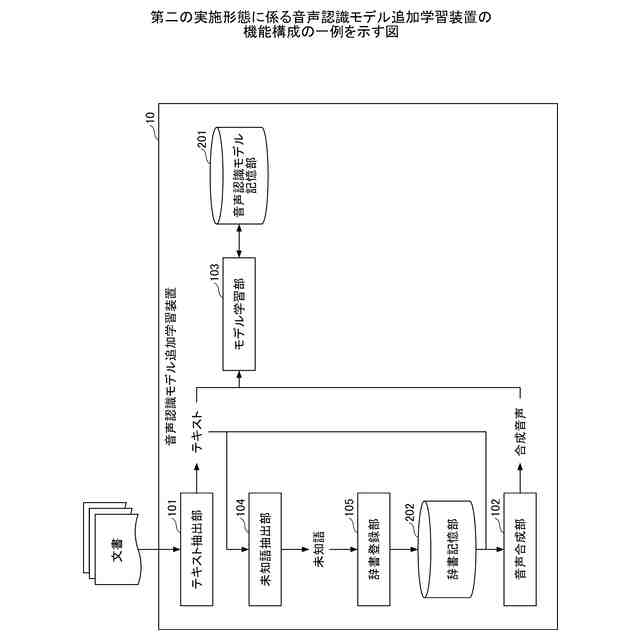
第二の実施形態に係る音声認識モデル追加学習装置の機能構成の一例を示す図である。
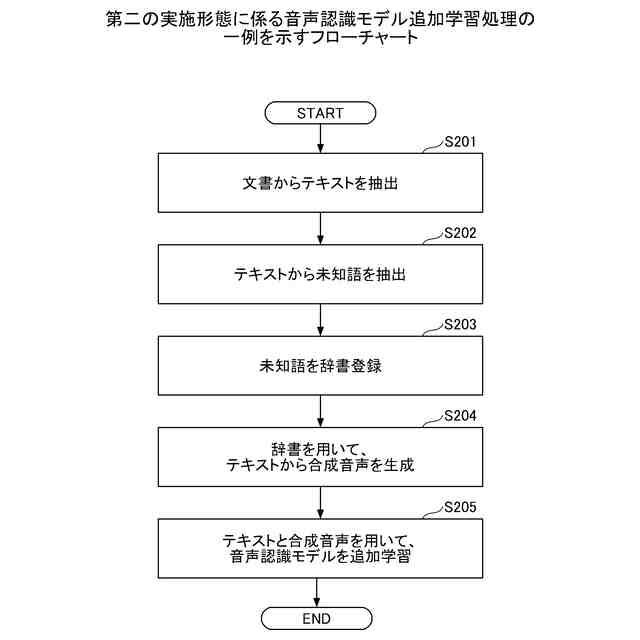
第二の実施形態に係る音声認識モデル追加学習処理の一例を示すフローチャートである。
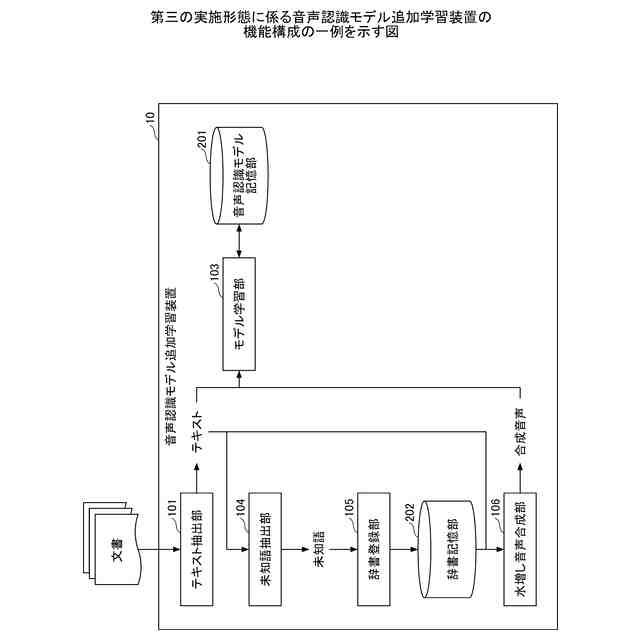
第三の実施形態に係る音声認識モデル追加学習装置の機能構成の一例を示す図である。
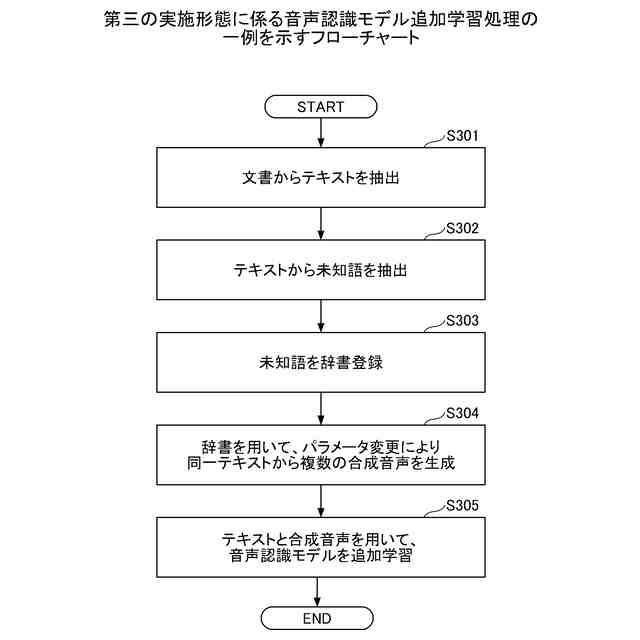
第三の実施形態に係る音声認識モデル追加学習処理の一例を示すフローチャートである。
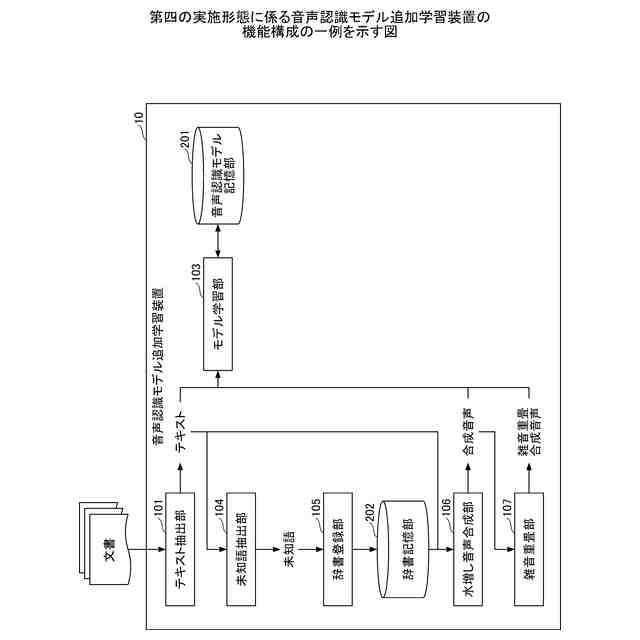
第四の実施形態に係る音声認識モデル追加学習装置の機能構成の一例を示す図である。
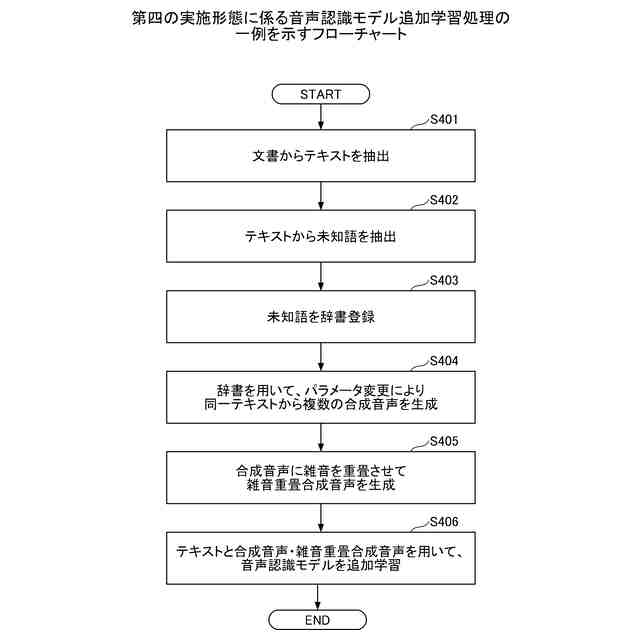
第四の実施形態に係る音声認識モデル追加学習処理の一例を示すフローチャートである。
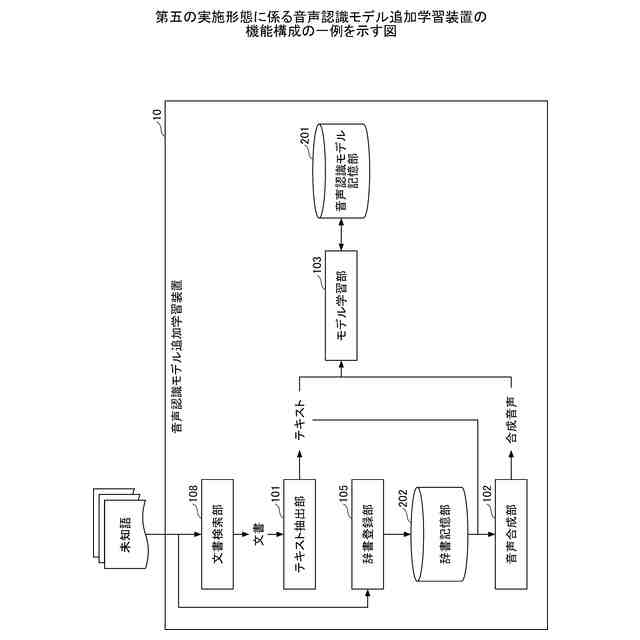
第五の実施形態に係る音声認識モデル追加学習装置の機能構成の一例を示す図である。
第五の実施形態に係る音声認識モデル追加学習処理の一例を示すフローチャートである。
【発明を実施するための形態】
【0009】
以下、本発明の一実施形態として、第一乃至第五の実施形態について説明する。以下の各実施形態では、ニューラルネットワークで実現されるend-to-endの音声認識モデルに未知語を正しく認識させるための追加学習(チューニング)を行う際に、その追加学習コストを従来よりも削減できる音声認識モデル追加学習装置10について説明する。ここで、未知語とは音声認識モデルが正しく認識できない語(単語、句、フレーズ等)やend-to-endの音声認識モデルの学習時に用いられた学習データに含まれていなかった語(単語、句、フレーズ等)のことであるが、以下では、未知語として、主に、特定の分野・領域・業界・文脈等の間でのみ使用され、一般的でない語のことを指すものとする。未知語の典型例としては、特定の分野・領域・業界・文脈等の間でのみ使用される専門用語、業界用語、固有名詞(商品名、サービス名、人名、組織名等)、隠語、略語等が挙げられる。なお、追加学習は再学習と呼ばれてもよい。
【0010】
[第一の実施形態]
以下、第一の実施形態について説明する。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社SOU
保護具
10日前
三井化学株式会社
防音構造
4日前
三井化学株式会社
防音構造体
5日前
三井化学株式会社
遮音構造体
11日前
東レ・セラニーズ株式会社
混繊不織布
10日前
スマートライフサプライ合同会社
楽器スタンド
10日前
横浜ゴム株式会社
多層空洞音響材
18日前
中強光電股ふん有限公司
電子システム及びその制御方法
10日前
ドリックス株式会社
消音パネル
7日前
株式会社第一興商
カラオケ装置
6日前
カシオ計算機株式会社
電子機器
10日前
株式会社JVCケンウッド
聴音装置、聴音方法及びプログラム
10日前
カシオ計算機株式会社
電子鍵盤楽器
10日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
11日前
ソフトバンクグループ株式会社
システム
6日前
ソフトバンクグループ株式会社
システム
6日前
ソフトバンクグループ株式会社
システム
6日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
11日前
ソフトバンクグループ株式会社
システム
11日前
ソフトバンクグループ株式会社
システム
7日前
ソフトバンクグループ株式会社
システム
6日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
10日前
ソフトバンクグループ株式会社
システム
11日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ