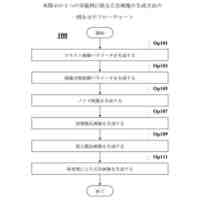
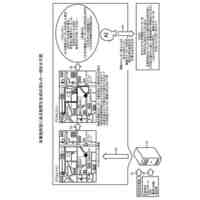
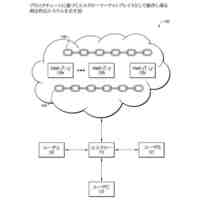
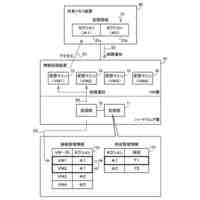
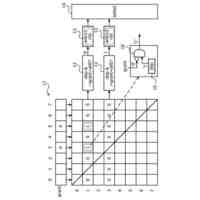
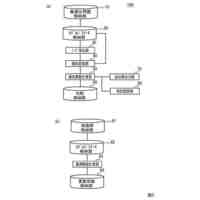
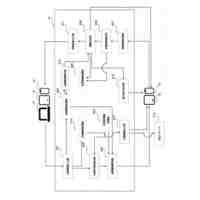
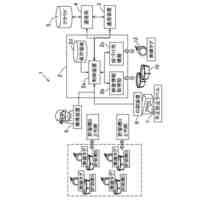
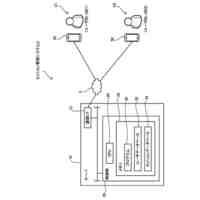
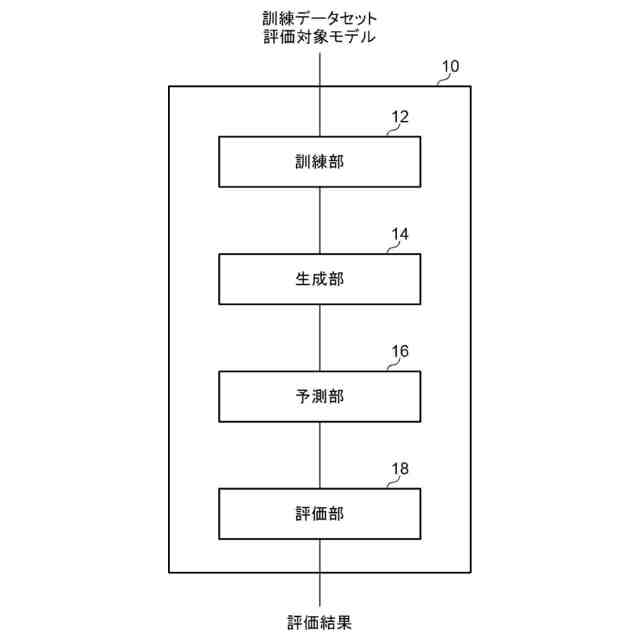
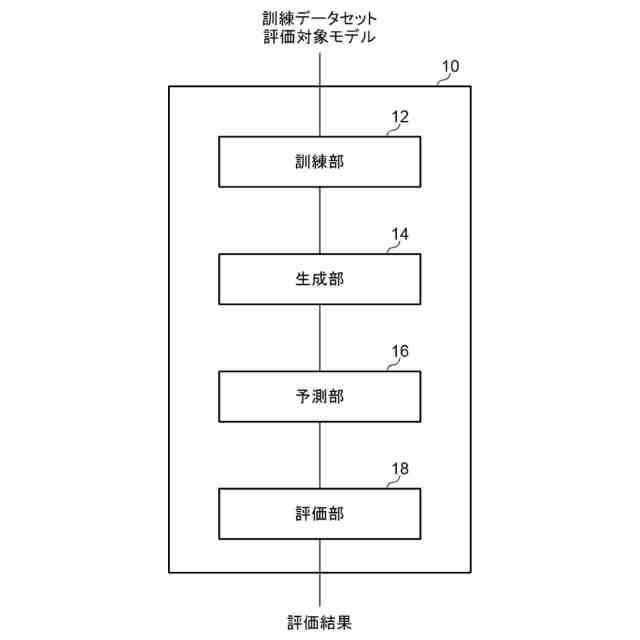
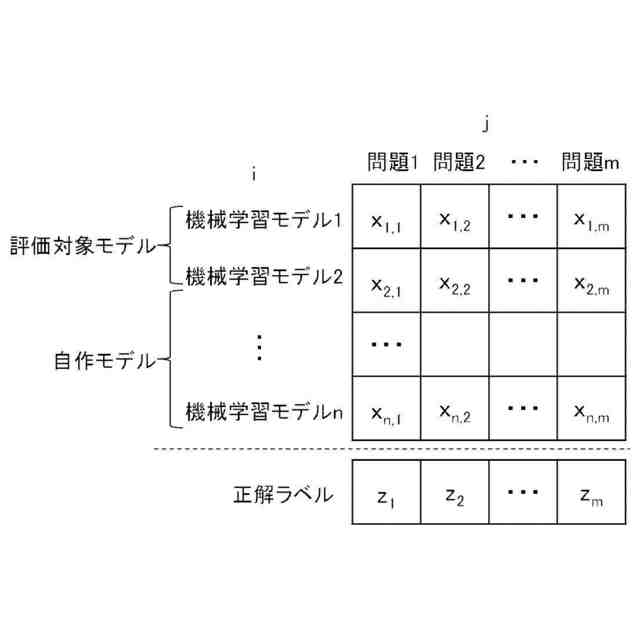
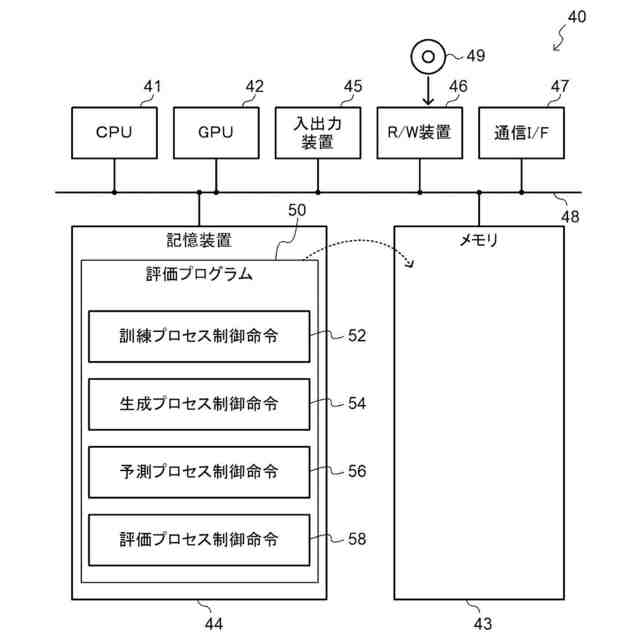
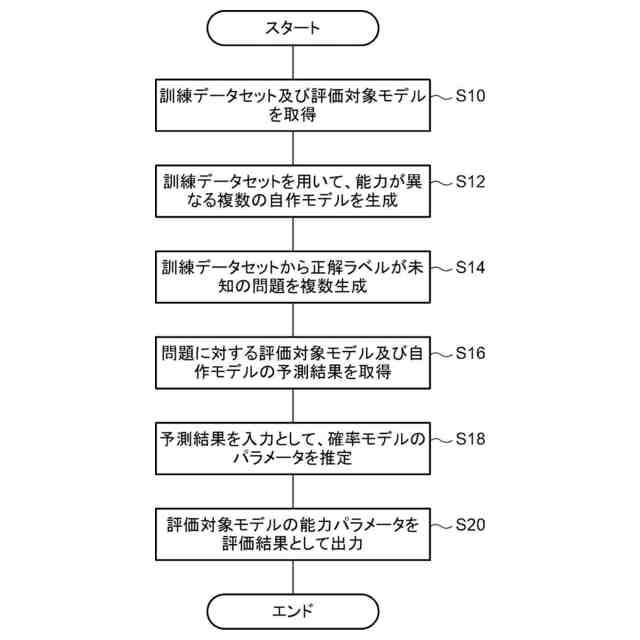
発明の詳細な説明【技術分野】 【0001】 開示の技術は、評価プログラム、評価方法、及び評価装置に関する。 続きを表示(約 2,400 文字)【背景技術】 【0002】 機械学習による入力値に対する推定値の信頼性を評価する方法が提案されている。この方法は、未学習の機械学習プログラムPに対し、複数の入力値と当該複数の入力値から経験的に得られた既知の出力値とを訓練データTDとして機械学習法による学習処理を実行する。また、この方法は、入力値から出力値を得る学習済みの推定モデルM1~Mnを複数生成し、生成した複数の学習済みの推定モデルM1~Mnのそれぞれに同じ入力値aを入力し、それぞれの推定モデルから出力値X1~Xnを得る。そして、この方法は、得られた複数の出力値の平均値Xmと標準偏差δXmとを求め、標準偏差δXmが小さい出力値ほど、入力値に対する出力値の信頼性が高いと評価する。 【0003】 また、自然言語処理等に関する機械学習モデルの評価に項目応答理論(IRT:Item Response Theory)が導入されている。IRTは、教育テストにおいて、受験者の能力とテスト問題の品質とを同時に評価する手法として広く使われている。機械学習モデルの評価にIRTを適用する場合、機械学習モデルの能力と、評価用データの特徴との両方を評価することができる。 【先行技術文献】 【特許文献】 【0004】 特開2023-56139号公報 【非特許文献】 【0005】 Pedro Rodriguez, Phu Mon Htut, John Lalor, Joao Sedoc, "Clustering Examples in Multi-Dataset Benchmarks with Item Response Theory," In Proceedings of the Third Workshop on Insights from Negative Results in NLP, pages 100-112, Dublin, Ireland, Association for Computational Linguistics, May 2022. Joao Sedoc and Lyle Ungar, "Item Response Theory for Efficient Human Evaluation of Chatbots," In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, pages 21-33, Online, Association for Computational Linguistics, November 2020. 【発明の概要】 【発明が解決しようとする課題】 【0006】 機械学習モデルの評価には、正解ラベル付きのデータが必要であるが、この正解ラベル付きのデータは入手困難な場合も多い。例えば、バイオ分野等では、正解ラベル付きのデータを得るためには実験が必要であるが、これには限界があり、正解ラベル付きのデータを多数用意することは困難である。機械学習モデルの評価の際に入手可能な正解ラベル付きのデータの数が少ない場合、統計的に不十分で評価の信頼性が低くなる場合がある。 【0007】 また、機械学習モデルの評価を適切に行うためには、評価対象の機械学習モデルの訓練に用いられた訓練データセットとは異なるデータで評価することが望ましい。しかし、外部で開発され公開された機械学習モデルの場合、公開されている入手可能な正解ラベル付きデータが、その機械学習モデルの訓練に使われた可能性もある。また、外部で開発された機械学習モデルと、自分で開発した機械学習モデルとの比較等、複数の機械学習モデルの能力を比較評価する場合、複数の機械学習モデルに対して同じベンチマークデータセットを用いて評価することが望ましい。しかし、複数の機械学習モデルそれぞれが異なる訓練データセットで訓練されている場合や、訓練データセットが未公表で不明な場合もある。このような状況では、適切なベンチマークデータセットを用意して、複数の機械学習モデル間の公正な比較評価を行うことは困難である。 【0008】 一つの側面として、開示の技術は、統計的信頼性及び公平性を確保して、複数の機械学習モデルの比較評価を行うことを目的とする。 【課題を解決するための手段】 【0009】 一つの態様として、開示の技術は、複数の正解ラベル付きの訓練データを用いて、能力の異なる複数の第1機械学習モデルを訓練し、前記複数の正解ラベル付きの訓練データとの類似度が所定値以下で、正解ラベルが未知の複数の評価用データを生成する。また、開示の技術は、前記複数の評価用データに対する、前記複数の第1機械学習モデル、及び評価対象の1以上の第2機械学習モデルの各々による予測結果を取得する。そして、開示の技術は、前記複数の第1機械学習モデル及び前記1以上の第2機械学習モデルの各々が前記予測結果を得る確率を表す確率モデルに前記予測結果を入力して最適化する。確率モデルは、前記複数の第1機械学習モデル及び前記1以上の第2機械学習モデルの各々の能力を示すパラメータと、前記複数の評価用データの正解ラベルを示すパラメータとを含む。開示の技術は、確率モデルを最適化した際の前記能力を示すパラメータを、前記1以上の第2機械学習モデルの各々の能力を示す評価指標として出力する。 【発明の効果】 【0010】 一つの側面として、統計的信頼性及び公平性を確保して、複数の機械学習モデルの比較評価を行うことができる、という効果を有する。 【図面の簡単な説明】 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
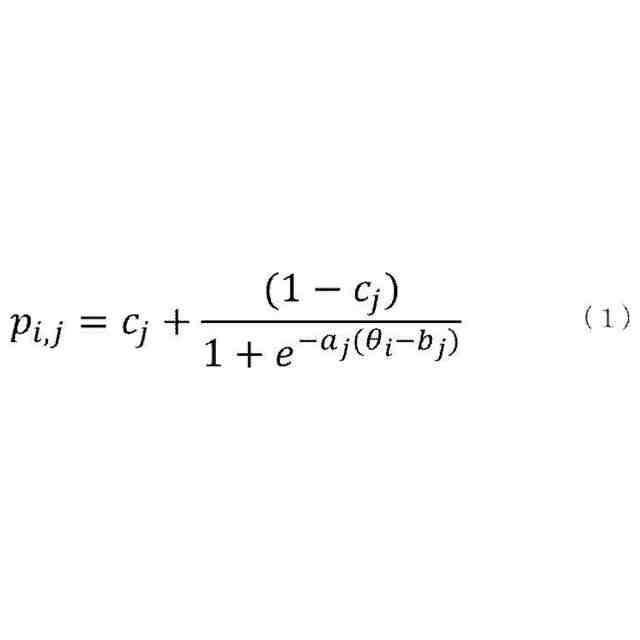


 特許ウォッチ
特許ウォッチ