TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025117505
公報種別
公開特許公報(A)
公開日
2025-08-12
出願番号
2024093809
出願日
2024-06-10
発明の名称
電子装置及びその制御方法
出願人
現代自動車株式会社
,
HYUNDAI MOTOR COMPANY
,
起亞株式会社
,
KIA CORPORATION
代理人
弁理士法人共生国際特許事務所
主分類
G10L
25/51 20130101AFI20250804BHJP(楽器;音響)
要約
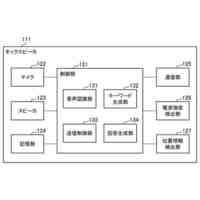
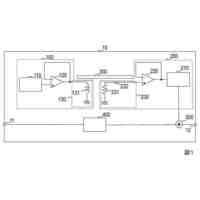
【課題】音声トーン変化に基づいてロボット発話に好適なジェスチャーを生成する電子装置及びその制御方法を提供する。
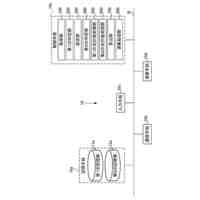
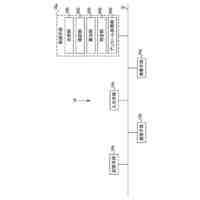
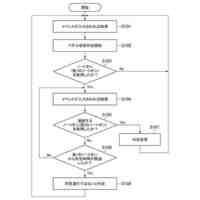
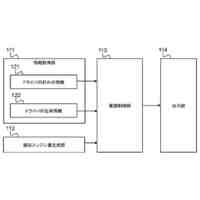
【解決手段】メモリー及びメモリーにアクセスして命令語を実行する少なくとも一つ以上のプロセッサーを有する電子装置において、その制御方法は、コーパスに含まれた対象文章から、文法に関する単位の第1ワードセグメント及び第2ワードセグメントを識別し、第1ワードセグメント及び第2ワードセグメントの間の休止時間及び予め決定された臨界時間の比較に基づいて、第1ワードセグメント及び第2ワードセグメントを含む対象フレーズを決定し、対象文章を予め決定された音声合成モデルに適用して獲得された音声データのピッチ輪郭に関する情報及び対象フレーズに含まれたワードセグメントのそれぞれの発話時間に基づいて、対象フレーズの音声トーン変化を決定する。
【選択図】図2
特許請求の範囲
【請求項1】
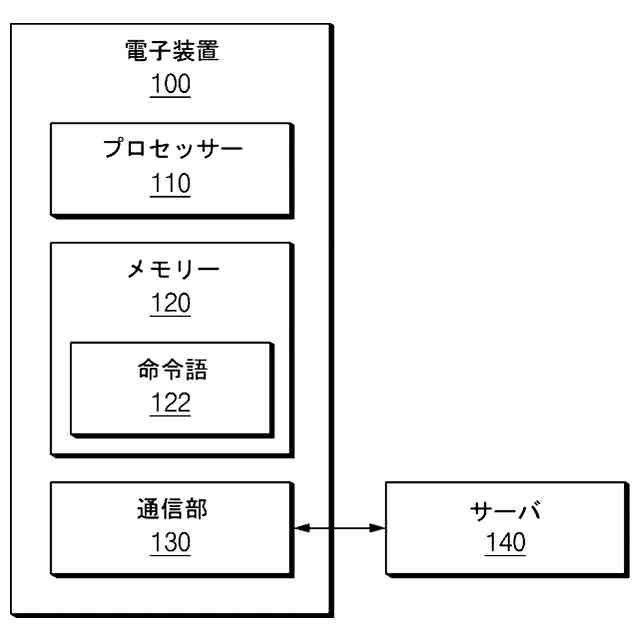
コンピュータで実行可能な命令語(computer-executable instructions)を保存したメモリーと、
前記メモリーにアクセス(access)して前記命令語を実行する少なくとも一つ以上のプロセッサーと、を含み、
前記少なくとも一つ以上のプロセッサーは、
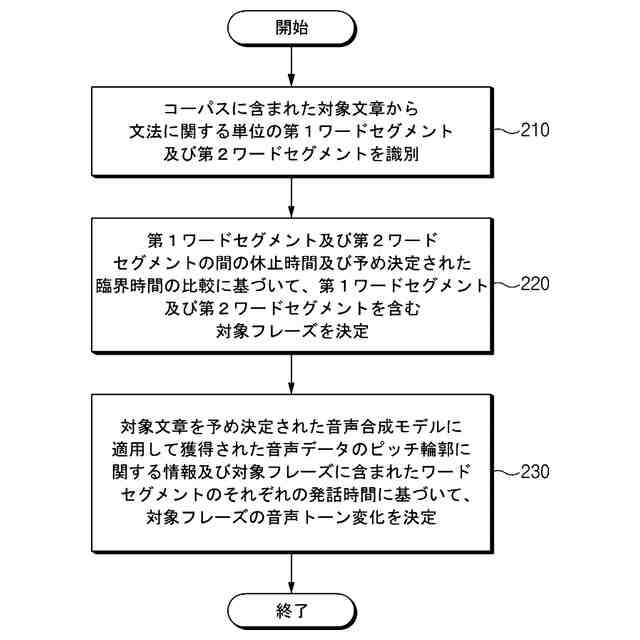
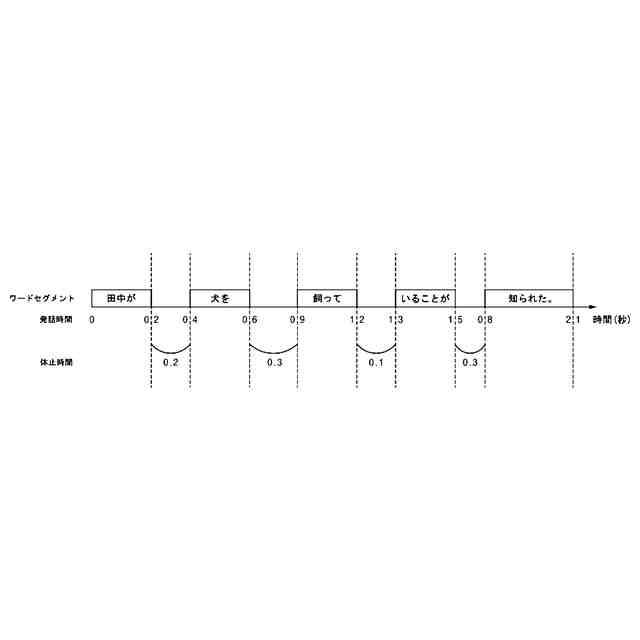
コーパス(corpus)に含まれた対象文章(target sentence)から、文法に関する単位の第1ワードセグメント(word segment)及び第2ワードセグメントを識別し、
前記第1ワードセグメント及び前記第2ワードセグメントの間の休止時間及び予め決定された(predetermined)臨界時間の比較に基づいて、前記第1ワードセグメント及び前記第2ワードセグメントを含む対象フレーズ(target phrase)を決定し、
前記対象文章を予め決定された音声合成(text to speech)モデルに適用して獲得された音声データのピッチ輪郭(pitch contour)に関する情報及び前記対象フレーズに含まれたワードセグメントのそれぞれの発話時間(utterance time)に基づいて、前記対象フレーズの音声トーン(voice tone)変化を決定する、ことを特徴とする電子装置。
続きを表示(約 2,400 文字)
【請求項2】
前記少なくとも一つ以上のプロセッサーは、
前記音声データから前記第1ワードセグメントの第1発話時間、及び前記第2ワードセグメントの第2発話時間を識別し、
前記第1発話時間及び前記第1ワードセグメントのピッチ輪郭に関する情報を介して前記第1ワードセグメントの第1音声トーン変化を決定し、
前記第2発話時間及び前記第2ワードセグメントのピッチ輪郭に関する情報を介して前記第2ワードセグメントの第2音声トーン変化を決定する、ことを特徴とする請求項1に記載の電子装置。
【請求項3】
前記少なくとも一つ以上のプロセッサーは、
前記第1発話時間に対応する前記第1ワードセグメントのピッチ輪郭に関する情報から、予め決定された単位時間間隔ごとに音声トーン変化率を獲得することで、前記第1音声トーン変化を決定し、
前記第2発話時間に対応する前記第2ワードセグメントのピッチ輪郭に関する情報から、予め決定された単位時間間隔ごとに音声トーン変化率を獲得することで、前記第2音声トーン変化を決定する、ことを特徴とする請求項2に記載の電子装置。
【請求項4】
前記少なくとも一つ以上のプロセッサーは、
前記第1ワードセグメント及び前記第2ワードセグメントが前記対象フレーズに含まれたことに基づいて、前記第1音声トーン変化及び前記第2音声トーン変化の平均を決定し、
前記平均を正規化(normalization)関数に適用して獲得された値を前記対象フレーズの音声トーン変化として決定する、ことを特徴とする請求項2に記載の電子装置。
【請求項5】
前記少なくとも一つ以上のプロセッサーは、
前記休止時間が前記臨界時間未満であることに基づいて、前記対象フレーズに前記第1ワードセグメント及び前記第2ワードセグメントを含ませ、
前記休止時間が前記臨界時間以上であることに基づいて、前記第1ワードセグメント及び前記第2ワードセグメントのうちの一つを前記対象フレーズに含ませる、ことを特徴とする請求項1に記載の電子装置。
【請求項6】
前記少なくとも一つ以上のプロセッサーは、
前記休止時間が前記臨界時間未満であることに基づいて、前記音声データで前記第1ワードセグメント及び前記第2ワードセグメントの位置を決定し、
前記第2ワードセグメントが前記第1ワードセグメントに後続することに基づいて、前記音声データから前記第2ワードセグメントに後続する第3ワードセグメントを識別し、
前記第2ワードセグメント及び前記第3ワードセグメントの間の休止時間及び前記臨界時間の比較に基づいて、前記第3ワードセグメントを前記対象フレーズに含ませるか否かを決定する、ことを特徴とする請求項5に記載の電子装置。
【請求項7】
前記少なくとも一つ以上のプロセッサーは、
前記第1ワードセグメント及び前記第2ワードセグメントを含む対象ウィンドー(target window)のワードエンベディング(word embedding)を介して、予め決定された次元(dimension)の数を有する第1対象ベクトルを獲得し、
前記第1対象ベクトルをフレーズ単位認識モデルに適用して、前記対象ウィンドーに含まれたワードセグメントのセグメンテーション(segmentation)可否を示す出力を獲得し、
前記出力及び前記対象文章の比較により獲得された第1ロス(loss)に基づいて、前記フレーズ単位認識モデルを学習させる、ことを特徴とする請求項1に記載の電子装置。
【請求項8】
前記少なくとも一つ以上のプロセッサーは、
前記対象フレーズのワードエンベディングを介して、前記対象フレーズに含まれたワードセグメントごとに予め決定された次元の数を有するベクトルを含む第2対象ベクトルを獲得し、
前記第2対象ベクトルを、入力される対象の次元を縮小させるエンコーダーに適用して、前記第2対象ベクトルの次元を縮小させ、
前記エンコーダーに適用された前記第2対象ベクトルを音声トーン変化予測モデルに適用して、前記対象フレーズの臨時音声トーン変化を獲得し、
前記対象フレーズの臨時音声トーン変化及び前記対象フレーズの音声トーン変化の比較により獲得された第2ロスに基づいて、前記音声トーン変化予測モデルを学習させる、ことを特徴とする請求項1に記載の電子装置。
【請求項9】
前記少なくとも一つ以上のプロセッサーは、
前記対象文章に含まれたフレーズのそれぞれの音声トーン変化が決定されたことに基づいて、前記対象文章に含まれたフレーズのうち、音声トーン変化が最も大きなフレーズを前記対象文章のジェスチャー実行区間に該当するジェスチャー割り当て候補として決定し、
前記ジェスチャー割り当て候補に対応するジェスチャータイプに基づいて、前記ジェスチャー割り当て候補のジェスチャーを決定し、
前記ジェスチャーを前記ジェスチャー割り当て候補の発話時間に対応させて、前記対象文章の出力が予定されたロボットのジェスチャーを生成する、ことを特徴とする請求項1に記載の電子装置。
【請求項10】
前記少なくとも一つ以上のプロセッサーは、
前記音声データから前記ピッチ輪郭に関する情報を識別できなかったことに基づいて、前記音声データにキュービックスプライン(cubic spline)補間(interpolation)を適用して前記ピッチ輪郭に関する情報を識別する、ことを特徴とする請求項1に記載の電子装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
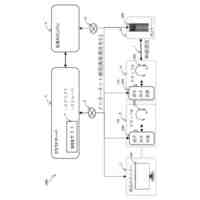
本発明は、電子装置及びその制御方法に係り、より詳しくは、ロボットジェスチャーを生成するモデルの学習データを生成するための技術に関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
対話モデル(例えば、chatbot)から入力されたロボットの発話文章(Text)に対応するロボットのスピーチ(Speech)-ジェスチャーを生成するために、与えられたロボット発話文章において、ジェスチャーが割り当て可能な区間(例えば、ジェスチャーの開始と終了時点を含む)及びジェスチャー割り当て区間に好適なジェスチャーをDBで選択して生成する過程が必要である。具体的には、発話文章全体にジェスチャーを割り当てする場合、発話開始から終了時点までジェスチャーを表現するので、これは使用者の没入度を阻害することができる。また、ロボット発話とジェスチャーとの間の時間同期(Sync)が合わない場合、ヒトとロボットとの間の否定的な相互作用効果(例えば、好感度低下)を引き起こすことができる。
【0003】
これに関連し、ジェスチャーが割り当て可能な区間は、ワードセグメント(例えば、語節)又はフレーズ(例えば、句)単位で多様なことがある。ただし、ワードセグメントは、発話時間が短いので、ジェスチャー生成に十分な時間を確保することに困難がある。したがって、フレーズ単位にジェスチャーを割り当てする技術が主に開発されてきたが、発話文章内の文法情報(例えば、品詞)又は意味情報(例えば、形態素)に基づいてジェスチャーを生成したので、ロボットの音声トーン変化と連繋性が考慮されなかった。また、機械学習方法で学習されたモデルを活用することは、使用者が膨大な量のデータを構築する過程が求められるので、時間と努力が伴わなければならないという困難があった。
【0004】
このような問題を解決するために、ロボットジェスチャーを生成するモデルの学習データを自動で生成する技術、及び音声トーン変化に基づいてジェスチャーを割り当てする技術の開発が必要である。
【先行技術文献】
【特許文献】
【0005】
特開2022-158193号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
本発明の実施形態は、対象文章を音声合成モデルに適用して獲得された音声データのピッチ輪郭に関する情報とワードセグメントの発話時間に基づいて、対象フレーズの音声トーン変化を決定することで、音声トーン変化に基づいてロボット発話に好適なジェスチャーを生成する電子装置及びその制御方法を提供しようとする。
【0007】
また、本発明の実施形態は、音声データからピッチ輪郭に関する情報を識別できなかったことに基づいて、音声データにキュービックスプライン補間を適用してピッチ輪郭に関する情報を獲得することで、ピッチ輪郭が識別されないワードフレーズの音声トーン変化を獲得できる電子装置及びその制御方法を提供しようとする。
【0008】
また、本発明の実施形態は、対象文章に含まれたフレーズのうち、音声トーン変化が最も大きなフレーズを対象文章のジェスチャー割り当て候補として決定することで、ロボットの自然なスピーチ-ジェスチャー生成により使用者と自然な相互作用を提供できる電子装置及びその制御方法を提供しようとする。
本発明の技術的課題は、以上で言及した技術的課題に制限されず、言及されていないさらに他の技術的課題は、以下の記載から当業者に明確に理解され得る。
【課題を解決するための手段】
【0009】
本発明の実施形態による電子装置は、コンピュータで実行可能な命令語(computer-executable instructions)を保存したメモリー、及び前記メモリーにアクセス(access)して前記命令語を実行する少なくとも一つ以上のプロセッサーを含み、前記少なくとも一つ以上のプロセッサーは、コーパス(corpus)に含まれた対象文章(target sentence)から、文法に関する単位の第1ワードセグメント(word segment)及び第2ワードセグメントを識別し、前記第1ワードセグメント及び前記第2ワードセグメントの間の休止時間及び予め決定された(predetermined)臨界時間の比較に基づいて、前記第1ワードセグメント及び前記第2ワードセグメントを含む対象フレーズ(target phrase)を決定し、前記対象文章を予め決定された音声合成(text to speech)モデルに適用して獲得された音声データのピッチ輪郭(pitch contour)に関する情報及び前記対象フレーズに含まれたワードセグメントのそれぞれの発話時間(utterance time)に基づいて、前記対象フレーズの音声トーン(voice tone)変化を決定することができる。
【0010】
一実施形態において、前記少なくとも一つ以上のプロセッサーは、前記音声データから前記第1ワードセグメントの第1発話時間、及び前記第2ワードセグメントの第2発話時間を識別し、前記第1発話時間及び前記第1ワードセグメントのピッチ輪郭に関する情報を介して前記第1ワードセグメントの第1音声トーン変化を決定し、前記第2発話時間及び前記第2ワードセグメントのピッチ輪郭に関する情報を介して前記第2ワードセグメントの第2音声トーン変化を決定することができる。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
富士フイルム株式会社
消音器
14日前
積水化学工業株式会社
吸音構造体
10日前
株式会社イシダ
商品処理装置
1日前
ヤマハ株式会社
弦楽器用の支持装置
14日前
富士フイルム株式会社
消音器付き風路
14日前
株式会社総合車両製作所
吸音パネル
1か月前
ヤマハ株式会社
リード
8日前
NOK株式会社
吸音構造体
今日
株式会社レゾナック
吸音材及び車両部材
1か月前
株式会社第一興商
カラオケ装置
23日前
株式会社第一興商
カラオケ装置
1か月前
株式会社第一興商
カラオケ装置
2日前
ヤマハ株式会社
連打判定装置および方法、プログラム
24日前
有限会社舞システム企画
介護情報生成システム
14日前
株式会社エクシング
端末装置、及び、端末装置用プログラム
8日前
ヤマハ株式会社
鍵盤装置
15日前
シャープ株式会社
電子機器および電子機器の制御方法
3日前
株式会社コルグ
電子楽器用アナログエフェクタ
1か月前
トヨタ自動車株式会社
防音カバー
2日前
シャープ株式会社
制御装置、電気機器、およびシステム
17日前
トヨタ自動車株式会社
制御装置
18日前
株式会社麗光
防音積層体とその製造に用いる遮音膜、および遮音膜シート
7日前
富士通株式会社
情報処理プログラム、情報処理方法及び情報処理装置
3日前
本田技研工業株式会社
音声認識方法および音声認識装置
16日前
井関農機株式会社
作業車の操縦者用騒音低減装置
1か月前
コニカミノルタ株式会社
音声変換装置、音声変換方法および音声変換プログラム
22日前
日本電波工業株式会社
音声再生装置及び音声再生方法
1か月前
株式会社ACES
発話情報抽出装置及びそのプログラム
11日前
株式会社ドワンゴ
再生装置、再生方法、プログラム、および再生システム
10日前
シャープ株式会社
雑音低減システム、掃除機、雑音低減方法及びプログラム
21日前
シャープ株式会社
雑音低減システム、掃除機、雑音低減方法及びプログラム
21日前
シャープ株式会社
雑音低減システム、掃除機、雑音低減方法及びプログラム
21日前
シャープ株式会社
雑音低減システム、掃除機、雑音低減方法及びプログラム
21日前
シャープ株式会社
情報処理システム、情報処理方法、及び情報処理プログラム
11日前
ブラザー工業株式会社
カラオケシステム、カラオケ装置、及びカラオケ装置用のプログラム
1か月前
株式会社石森管楽器
リガチャーおよび楽器
1か月前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ