TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025093156
公報種別
公開特許公報(A)
公開日
2025-06-23
出願番号
2023208726
出願日
2023-12-11
発明の名称
動作指令生成装置
出願人
株式会社日立製作所
代理人
弁理士法人信友国際特許事務所
主分類
B25J
13/08 20060101AFI20250616BHJP(手工具;可搬型動力工具;手工具用の柄;作業場設備;マニプレータ)
要約
【課題】作業環境の撮像視点がずれても、学習時間を増加させず、ロボットが所望の作業を実施するように動作指令を生成する。
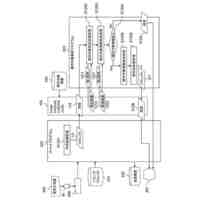
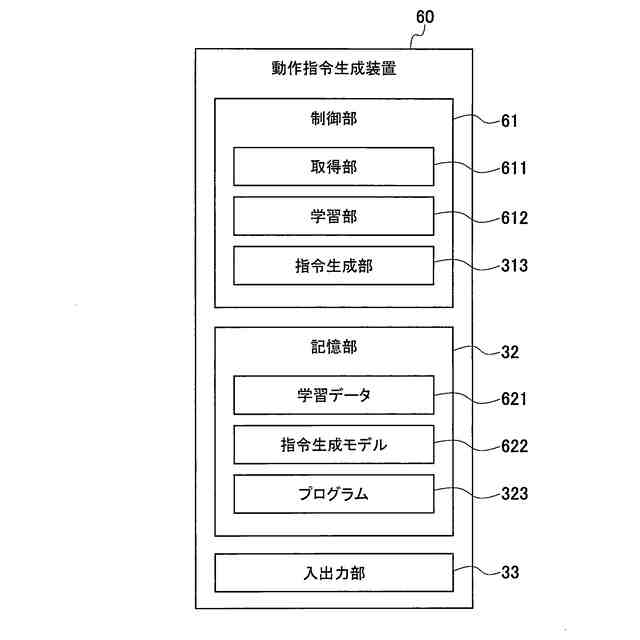
【解決手段】動作指令生成装置30は、複数視点からの作業環境の撮像画像及びロボット10への指令データが反映されたセンサーデータを含む学習データ321から、ランダムに単一視点の撮像画像及び該撮像画像の撮像時刻と同時刻のセンサーデータを抽出して機械学習を行い、ロボットを自律運行させるための指令生成モデル322を生成する学習部312と、現在時刻の撮像画像及びセンサーデータを指令生成モデル322に入力し、ロボットへの次時刻の動作指令を生成する指令生成部313と、を備える。
【選択図】 図2
特許請求の範囲
【請求項1】
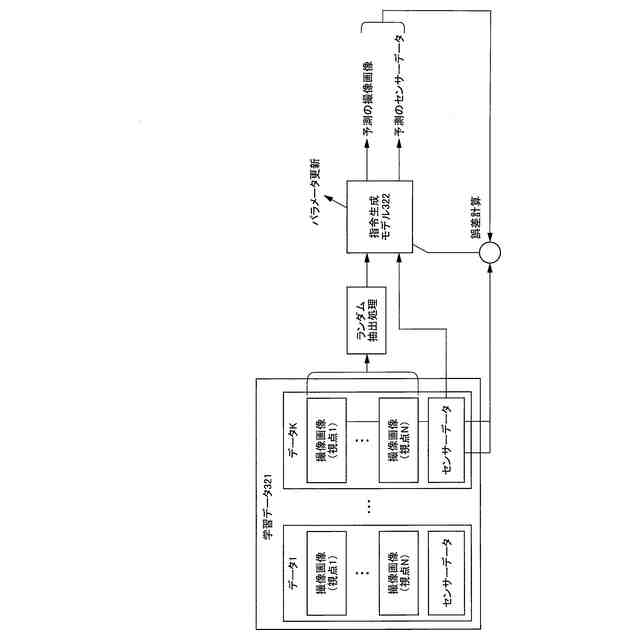
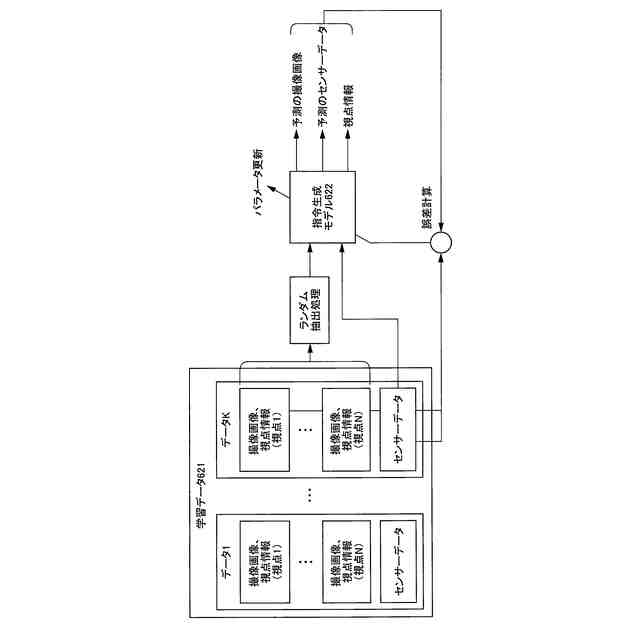
複数視点からの作業環境の撮像画像及びロボットへの指令データが反映されたセンサーデータを含む学習データから、ランダムに単一視点の前記撮像画像及び該撮像画像の撮像時刻と同時刻の前記センサーデータを抽出して機械学習を行い、前記ロボットを自律運行させるための指令生成モデルを生成する学習部と、
現在時刻の前記撮像画像及び前記センサーデータを前記指令生成モデルに入力し、前記ロボットへの次時刻の動作指令を生成する指令生成部と、を備える
動作指令生成装置。
続きを表示(約 1,100 文字)
【請求項2】
前記指令生成モデルは、入力された現在時刻の前記撮像画像及び前記センサーデータを用いて、入力された現在時刻の前記撮像画像の撮像視点と同じ視点の次時刻の前記撮像画像及び前記センサーデータを予測して出力する
請求項1に記載の動作指令生成装置。
【請求項3】
前記学習データは、複数視点からの前記撮像画像のそれぞれの撮像時の撮像装置の位置姿勢情報を含み、
前記学習部は、前記学習データから、ランダムに単一視点の前記撮像画像、該撮像画像の撮像時刻と同時刻の前記位置姿勢情報、及び前記センサーデータを抽出して機械学習を行い、前記指令生成モデルを生成する
請求項2に記載の動作指令生成装置。
【請求項4】
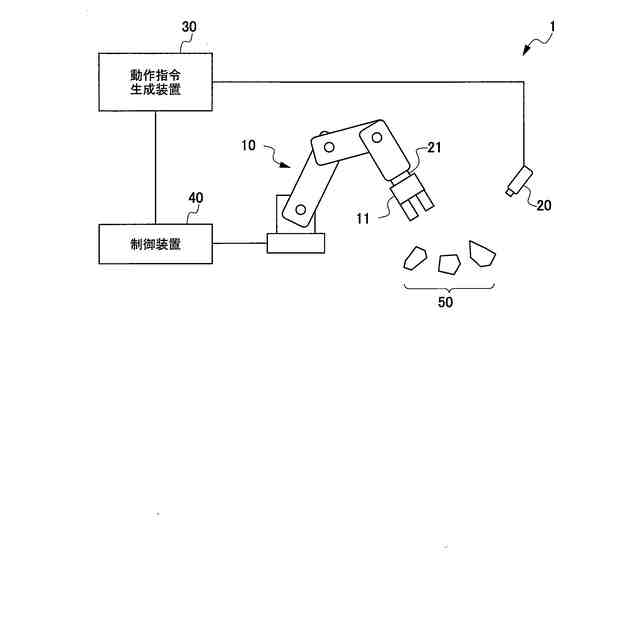
前記撮像画像は、前記ロボットが所定作業を実施する際に時系列に撮像された画像であり、前記ロボットのエンドエフェクタと前記ロボットの作業対象物とが映るように撮像された画像である
請求項3に記載の動作指令生成装置。
【請求項5】
前記学習データに含まれる複数視点からの前記撮像画像は、前記作業環境において、異なる位置姿勢で配置される複数の撮像装置により撮像された前記撮像画像である
請求項4に記載の動作指令生成装置。
【請求項6】
前記学習データに含まれる複数視点からの前記撮像画像は、シミュレータ上に構築された前記作業環境に類似した環境において、異なる位置姿勢で配置される複数の撮像装置による撮像を模擬して生成された前記撮像画像である
請求項4に記載の動作指令生成装置。
【請求項7】
前記学習データに含まれる複数視点からの前記撮像画像は、前記作業環境の単一視点の前記撮像画像を用いて、新規視点の画像生成方法によって生成された前記撮像画像である
請求項4に記載の動作指令生成装置。
【請求項8】
前記学習データに含まれる複数視点からの前記撮像画像は、前記作業環境の単一視点の前記撮像画像に対して、回転、平行移動及び拡大縮小の少なくとも1つを含む画像処理を施した画像を含む
請求項4に記載の動作指令生成装置。
【請求項9】
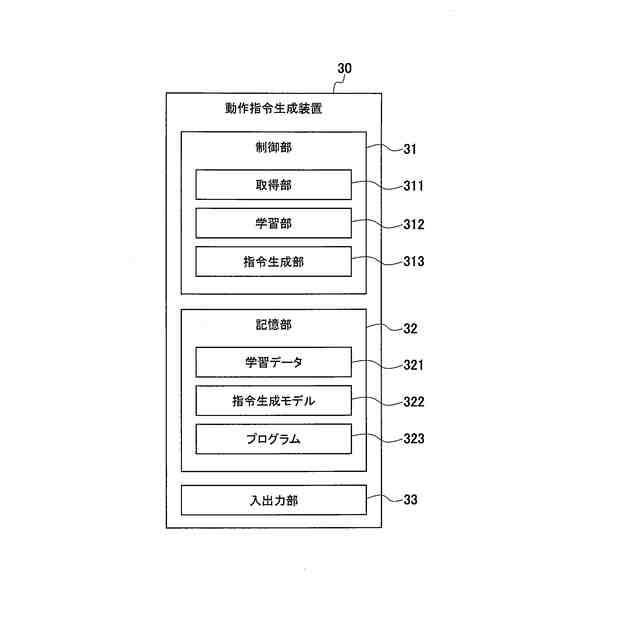
前記指令生成モデルの学習時の前記学習データ、学習の進歩状況を表示する入出力部を備える
請求項1に記載の動作指令生成装置。
【請求項10】
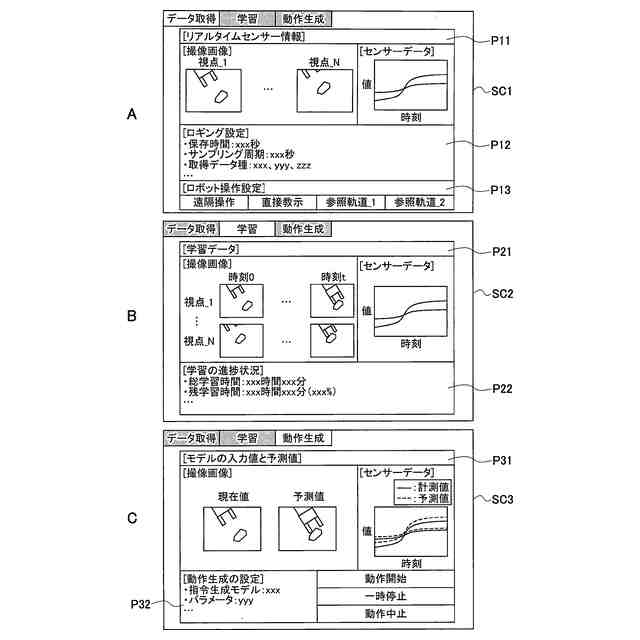
前記入出力部は、前記学習データの取得時の複数視点からの前記撮像画像及び前記センサーデータを表示し、前記動作指令の生成時に入力された前記撮像画像及び前記センサーデータ、並びに、予測された前記撮像画像及び前記センサーデータを表示する
請求項9に記載の動作指令生成装置。
発明の詳細な説明
【技術分野】
【0001】
本発明は、動作指令生成装置に関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
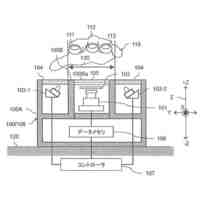
生産効率向上や人件費削減のため、工業製品の組立、溶接、搬送等の人が行っていた作業をロボットに代替させる取り組みが増えている。しかし、これまでのロボットシステムは、膨大なプログラミングや高い専門知識が必要であった。それは、ロボット導入の阻害要因になる。そこで、ロボット装置に取り付けられた各種センサー情報に基づいて、ロボット自身で動作を決定する自律学習型ロボット制御システムが提案されている。これまでのロボット制御システムに比べ、自律学習型ロボット制御システムは、膨大なプログラミングや高い専門知識などが不要であり、ロボットを容易に導入できることが期待される。さらに、自律学習型ロボット制御システムは、ロボット自らの動作経験を記憶して学習することで多様な環境変化に対して柔軟な動作生成が可能になると期待されている。
【0003】
ロボットの動作経験とは、例えば、ロボットを操作するユーザーがロボットに動作を直接教えて記憶させる方法や、人や他のロボットなどの動作を見て真似る方法などが挙げられる。また、一般的に、自律学習型ロボット制御システムには、学習装置が備えられており、動作経験時のセンサー情報の記憶と、動作を生成するためのパラメータの調整とが行われる。この記憶された動作経験時のセンサー情報は学習データとなり、動作を生成するためのパラメータの調整は学習となる。学習装置は、学習データを用いて、学習装置への入力値(学習データ)に対して、期待される出力値が出力されるように学習を繰り返し実行する。
【0004】
学習装置は、例えば、ある動作経験時のロボットの関節角情報と、作業環境の時系列に撮像された撮像画像とを、学習データとして記憶する。学習装置は、記憶した学習データを用いて、時刻(t)の関節角情報及び撮像画像を入力し、時刻(t+1)の関節角情報及び撮像画像を予測するように時機械学習を行う。そして、自律学習型ロボット制御システムは、学習が完了した学習装置にロボットの関節角情報及び撮像画像を逐次に入力することで、自身の状態に応じて自動的に動作指令を生成することが可能になる。
【0005】
上述したようなある時刻のセンサー情報から物体認識などを介せず、直接ロボットへの動作指令を生成する手法は、自律学習型のエンドツーエンドの動作生成手法と呼ばれる。自律学習型のエンドツーエンドの動作生成技術として、例えば、特許文献1に記載のロボットシステムが開示されている。
【0006】
特許文献1には、機械学習装置が、人とロボットと協働して作業を行う期間中に、人の顔を認識し、人に対応するニューラルネットワークの重みに基づいて、人の行動を分類して人の行動を学習すること、及び、人の行動を分類した結果に基づいてロボットの行動を制御することが記載されている。
【先行技術文献】
【特許文献】
【0007】
特開2018-62016号公報
【発明の概要】
【発明が解決しようとする課題】
【0008】
上述のように、従来、作業環境の撮像画像等の学習データを用いて、機械学習により自動的にロボットの動作を制御する技術(特許文献1)が開示されている。特許文献1に記載の自律学習型のエンドツーエンドの動作生成手法では、基本的にカメラの視点が固定されており、視点のずれは想定されていない。しかし、実用上では、カメラの視点ずれが発生するシーンは多いである。ロボット自体が動くようなモバイルマニピュレータでは、ロボットの移動に伴い、環境に対して、カメラは相対的に移動する。また、据え付け型のロボットにおいても、ロボットの移設によってカメラも移設するため、カメラの視点が学習時の視点とずれることが予想される。カメラの視点がずれる場合、撮像画像中の作業対象物やロボットの位置もずれる。このような視点ずれは全く学習されていないため、自律学習型ロボット制御システムの性能が大きく劣化する。このような場合には、カメラの視点をずらして取得した学習データによって追加学習を行う必要がある。また、追加学習に伴い、学習時間の増加問題が発生する。
【0009】
本発明は、上記問題を解決するために成されたものであり、本発明の目的は、作業環境の撮像視点がずれても、学習時間を増加させず、ロボットが所望の作業を実施するように動作指令を生成することである。
【課題を解決するための手段】
【0010】
上記課題を解決するため、本発明の動作指令生成装置は、複数視点からの作業環境の撮像画像及びロボットへの指令データが反映されたセンサーデータを含む学習データから、ランダムに単一視点の撮像画像及び該撮像画像の撮像時刻と同時刻のセンサーデータを抽出して機械学習を行い、ロボットを自律運行させるための指令生成モデルを生成する学習部と、現在時刻の撮像画像及びセンサーデータを指令生成モデルに入力し、ロボットへの次時刻の動作指令を生成する指令生成部と、を備える。
【発明の効果】
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
株式会社日立製作所
制御装置
3日前
株式会社日立製作所
電動機制御装置
10日前
株式会社日立製作所
レール把持装置
今日
株式会社日立製作所
機能割付システム
17日前
株式会社日立製作所
環境評価システム
5日前
株式会社日立製作所
航空機用の推進装置
10日前
株式会社日立製作所
沿岸環境監視システム
10日前
株式会社日立製作所
設計支援装置および設計支援方法
今日
株式会社日立製作所
情報処理システム及び情報処理方法
13日前
株式会社日立製作所
情報処理システム及び情報処理方法
3日前
株式会社日立製作所
情報抽出システム及び情報抽出方法
6日前
株式会社日立製作所
乗客コンベアの制御装置及び制御方法
18日前
株式会社日立製作所
行動解析システム、及び行動解析方法
17日前
株式会社日立製作所
管理装置、管理方法、及び制御システム
3日前
株式会社日立製作所
水電解システム及び絶縁配管の保守方法
4日前
株式会社日立製作所
サービス提供方法調整システムおよび方法
12日前
株式会社日立製作所
物流網計画システムおよび物流網計画方法
6日前
株式会社日立製作所
計算機システム及びパラメータ探索支援方法
13日前
株式会社日立製作所
ガイドレール取り付け方法及び接続クランプ
12日前
株式会社日立製作所
プロトコル分析装置及びプロトコル分析方法
7日前
株式会社日立製作所
欠損データ補完装置及び欠損データ補完方法
4日前
株式会社日立製作所
電力系統安定化装置および電力系統安定化方法
11日前
株式会社日立製作所
電力系統安定化装置および電力系統安定化方法
11日前
株式会社日立製作所
管理システム、管理方法、および管理プログラム
10日前
株式会社日立製作所
ワークロード制御装置及びワークロード制御方法
7日前
株式会社日立製作所
環境負荷軽減支援装置、及び環境負荷軽減支援方法
17日前
株式会社日立製作所
計算機システム及びITシステムの障害調査支援方法
今日
株式会社日立製作所
計算機システム及びクラス分類の結果の修正支援方法
7日前
株式会社日立製作所
生成モデルを利用した情報構築装置及び情報構築方法
5日前
株式会社日立製作所
作業支援システム、作業支援方法、作業支援プログラム
4日前
株式会社日立製作所
電力貯蔵装置監視システムおよび電力貯蔵装置監視方法
20日前
株式会社日立製作所
撮影装置
10日前
株式会社日立製作所
作成支援装置、作成支援方法、および作成支援プログラム
12日前
株式会社日立製作所
テスト支援装置、テスト支援方法、及びテスト支援システム
17日前
株式会社日立製作所
情報分析システム、情報分析方法、および情報分析プログラム
20日前
株式会社日立製作所
模擬シーン生成装置、体験装置、及び、動作改善支援システム
10日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ