TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024075304
公報種別
公開特許公報(A)
公開日
2024-06-03
出願番号
2022186669
出願日
2022-11-22
発明の名称
音声認識システム、学習装置、推論装置、音声認識方法、学習方法、推論方法及びプログラム
出願人
エヌ・ティ・ティ・コミュニケーションズ株式会社
代理人
弁理士法人志賀国際特許事務所
主分類
G10L
15/06 20130101AFI20240527BHJP(楽器;音響)
要約
【課題】様々な環境において、より精度高く音声認識を行うこと。
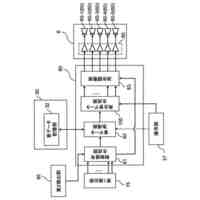
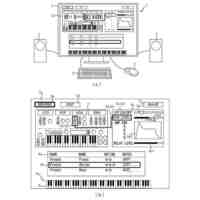
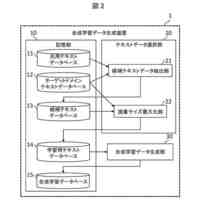
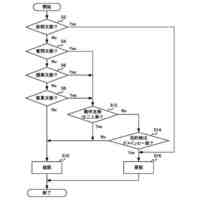
【解決手段】音声認識システムは、認識対象の音声を含む学習用の音声データと当該音声に対応する自然言語を示す正解データと当該音声が集音された位置を示す学習用の位置情報とを取得する学習用情報取得部と、学習用の位置情報に基づく位置ごとに学習用の音声データと正解データとに基づいて機械学習を行い位置ごとの学習モデルをそれぞれ生成する学習モデル生成部と、認識対象の音声を含む推論用の音声データと当該音声が集音された位置を示す推論用の位置情報とを取得する推論用情報取得部と、位置ごとの学習モデルのうち推論用の位置情報に基づく位置に対応する学習モデルを取得する学習モデル取得部と、推論用の音声データと推論用の位置情報に基づく位置に対応する学習モデルとに基づいて推論用の音声データに基づく音声を推論する推論部とを備える。
【選択図】図1
特許請求の範囲
【請求項1】
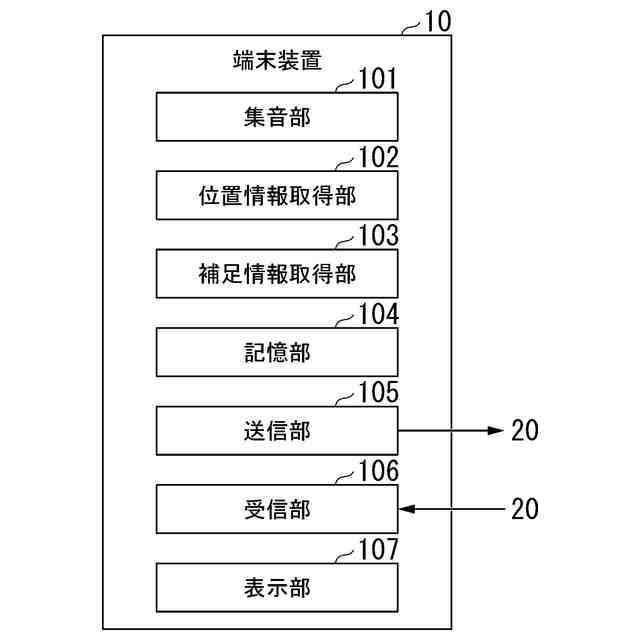
認識対象の音声を含む学習用の音声データと、前記認識対象の音声に対応する自然言語を示す正解データと、前記認識対象の音声が集音された位置を示す学習用の位置情報と、を取得する学習用情報取得部と、
前記学習用の位置情報に基づく位置ごとに、前記学習用の音声データと前記正解データとに基づいて機械学習を行い、前記位置ごとの学習モデルをそれぞれ生成する学習モデル生成部と、
認識対象の音声を含む推論用の音声データと、前記認識対象の音声が集音された位置を示す推論用の位置情報と、を取得する推論用情報取得部と、
前記位置ごとの学習モデルのうち、前記推論用の位置情報に基づく位置に対応する前記学習モデルを取得する学習モデル取得部と、
前記推論用の音声データと、前記推論用の位置情報に基づく位置に対応する前記学習モデルと、に基づいて前記推論用の音声データに基づく音声を推論する推論部と、
を備える音声認識システム。
続きを表示(約 1,300 文字)
【請求項2】
前記学習用の音声データ及び前記推論用の音声データのうち少なくとも一方に含まれる雑音を低減又は除去する調整部
を更に備える請求項1に記載の音声認識システム。
【請求項3】
学習用情報取得部が前記正解データを得られない場合に、前記学習モデル生成部への前記認識対象の音声に対応する自然言語の手入力を受け付ける調整部
を更に備える請求項1に記載の音声認識システム。
【請求項4】
前記学習用の位置情報及び前記推論用の位置情報のうち少なくとも一方は、前記認識対象の音声が集音された位置の周辺が撮像された画像を用いてビジュアルポジショニングシステムによって測定された位置を示す位置情報である
請求項1に記載の音声認識システム。
【請求項5】
前記位置情報は、ウェアラブルデバイスに備えられたカメラによって撮像された前記画像を用いて測定された位置を示す位置情報である
請求項4に記載の音声認識システム。
【請求項6】
前記学習用の音声データ及び前記推論用の音声データのうち少なくとも一方は、前記ウェアラブルデバイスに備えられたマイクロフォンによって集音された音に基づく音声データである
請求項5に記載の音声認識システム。
【請求項7】
前記認識対象の音声を集音するアプリケーションに設定される設定情報の取得を要求する認識設定要求部と、
前記認識設定要求部からの要求に応じて、前記推論部による推論の精度を向上させる、前記アプリケーションに対応付けられた前記設定情報を取得する設定情報取得部と、
前記設定情報取得部によって取得された前記設定情報を前記アプリケーションに適用する認識設定適用部と、
をさらに備える請求項1から6のうちいずれか一項に記載の音声認識システム。
【請求項8】
前記設定情報は、集音する前記音声の周波数帯、又は、前記音声を集音する際のバッファリング時間を示す情報を含む
請求項7に記載の音声認識システム。
【請求項9】
認識対象の音声を含む音声データと、前記認識対象の音声に対応する自然言語を示す正解データと、前記認識対象の音声が集音された位置を示す位置情報と、を取得する取得部と、
前記位置情報に基づく位置ごとに、前記音声データと前記正解データとに基づいて機械学習を行い、前記位置ごとの学習モデルをそれぞれ生成する学習モデル生成部と、
を備える学習装置。
【請求項10】
認識対象の音声を含む推論用の音声データと、前記認識対象の音声が集音された位置を示す推論用の位置情報と、を取得する取得部と、
集音された位置ごとの学習用の音声データを用いて行われた機械学習によって前記位置ごとに生成された学習モデルのうち、前記推論用の位置情報に基づく位置に対応する前記学習モデルを取得する学習モデル取得部と、
前記推論用の音声データと、前記推論用の位置情報に基づく位置に対応する前記学習モデルと、に基づいて前記推論用の音声データに基づく音声を推論する推論部と、
を備える推論装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識システム、学習装置、推論装置、音声認識方法、学習方法、推論方法及びプログラムに関する。
続きを表示(約 2,400 文字)
【背景技術】
【0002】
近年、特にディープラーニングをはじめとするAI(人工知能)の進化に伴って、音声認識技術の認識精度が飛躍的に向上している。昨今、音声認識技術が活用される場面は多岐にわたり、認識精度のさらなる向上が求められている。例えば、非特許文献1に記載の音声認識技術は、医療分野又は金融・保険分野等の特定の領域に特化した音声認識エンジンを備え、利用場面に応じて所望の音声認識エンジンを選択可能な構成にすることで認識精度の向上を図っている。
【先行技術文献】
【非特許文献】
【0003】
“AmiVoiceとは”、[online]、株式会社アドバンスト・メディア、[令和4年11月16日検索]、インターネット<URL:https://acp.amivoice.com/amivoice/>
【発明の概要】
【発明が解決しようとする課題】
【0004】
音声認識技術の活用形態として、例えば話者の音声を自動的にテキスト化して聴覚障がい者に提供するサービスがある。このような音声認識技術は、例えば屋外をはじめとする雑音が多い環境及び雑音の状況が変化する環境においても用いられることがある。この場合、たとえ特定の領域に特化した音声認識エンジンを選択可能な音声認識技術が用いられたとしても、雑音によって認識精度が低下することがある。
【0005】
従来、例えば講演会場、会議室、又は電話による通話等のような特定の環境における雑音を除去するための技術は検討されている。しかしながら、例えば駅では、雑踏から生じる音や話し声、構内アナウンス、及び列車の走行音等の多種多様な雑音が入り混じっている。また、例えば工事現場やアミューズメント施設等では、駅とは異なる種類や大きさの雑音が入り混じっている。そして、このような雑音は時期によっても変化する。このように、場所や時期等によって発生する雑音は多種多様であるため、従来技術では、様々な環境において一様に認識精度を高くするような音声認識技術を実現することが難しいという課題があった。
【0006】
本発明は、このような状況に鑑みてなされたものであり、雑音が発生する様々な環境において、より精度高く音声認識を行うことができる音声認識システム、学習装置、推論装置、音声認識方法、学習方法、推論方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
本発明の一態様は、認識対象の音声を含む学習用の音声データと、前記認識対象の音声に対応する自然言語を示す正解データと、前記認識対象の音声が集音された位置を示す学習用の位置情報と、を取得する学習用情報取得部と、前記学習用の位置情報に基づく位置ごとに、前記学習用の音声データと前記正解データとに基づいて機械学習を行い、前記位置ごとの学習モデルをそれぞれ生成する学習モデル生成部と、認識対象の音声を含む推論用の音声データと、前記認識対象の音声が集音された位置を示す推論用の位置情報と、を取得する推論用情報取得部と、前記位置ごとの学習モデルのうち、前記推論用の位置情報に基づく位置に対応する前記学習モデルを取得する学習モデル取得部と、前記推論用の音声データと、前記推論用の位置情報に基づく位置に対応する前記学習モデルと、に基づいて前記推論用の音声データに基づく音声を推論する推論部と、を備える音声認識システムである。
【0008】
また、本発明の一態様は、認識対象の音声を含む音声データと、前記認識対象の音声に対応する自然言語を示す正解データと、前記認識対象の音声が集音された位置を示す位置情報と、を取得する取得部と、前記位置情報に基づく位置ごとに、前記音声データと前記正解データとに基づいて機械学習を行い、前記位置ごとの学習モデルをそれぞれ生成する学習モデル生成部と、を備える学習装置である。
【0009】
本発明の一態様は、認識対象の音声を含む推論用の音声データと、前記認識対象の音声が集音された位置を示す推論用の位置情報と、を取得する取得部と、集音された位置ごとの学習用の音声データを用いて行われた機械学習によって前記位置ごとに生成された学習モデルのうち、前記推論用の位置情報に基づく位置に対応する前記学習モデルを取得する学習モデル取得部と、前記推論用の音声データと、前記推論用の位置情報に基づく位置に対応する前記学習モデルと、に基づいて前記推論用の音声データに基づく音声を推論する推論部と、を備える推論装置である。
【0010】
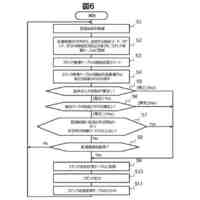
また、本発明の一態様は、コンピュータによる音声認識方法であって、認識対象の音声を含む学習用の音声データと、前記認識対象の音声に対応する自然言語を示す正解データと、前記認識対象の音声が集音された位置を示す学習用の位置情報と、を取得する学習用情報取得ステップと、前記学習用の位置情報に基づく位置ごとに、前記学習用の音声データと前記正解データとに基づいて機械学習を行い、前記位置ごとの学習モデルをそれぞれ生成する学習モデル生成ステップと、認識対象の音声を含む推論用の音声データと、前記認識対象の音声が集音された位置を示す推論用の位置情報と、を取得する推論用情報取得ステップと、前記位置ごとの学習モデルのうち、前記推論用の位置情報に基づく位置に対応する前記学習モデルを取得する学習モデル取得ステップと、前記推論用の音声データと、前記推論用の位置情報に基づく位置に対応する前記学習モデルと、に基づいて前記推論用の音声データに基づく音声を推論する推論ステップと、を有する音声認識方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社トランストロン
軸構造
3日前
学校法人幾徳学園
鍵盤楽器
7日前
日本製紙パピリア株式会社
表面材および吸音材
7日前
株式会社イノアックコーポレーション
防音構造
14日前
ヤマハ株式会社
動画処理方法
3日前
ヤマハ株式会社
管楽器及び管楽器用のキー
15日前
ヤマハ株式会社
鍵盤ユニット
15日前
日産自動車株式会社
音声認識方法及び音声認識装置
3日前
ヤマハ株式会社
音データ生成方法
8日前
株式会社日立情報通信エンジニアリング
音声入力支援システム、音声入力支援方法
7日前
カシオ計算機株式会社
ペダル装置及び電子鍵盤楽器
9日前
ローランド株式会社
音色設定プログラム、音色設定装置および音色設定方法
7日前
株式会社日立製作所
合成学習データ生成装置、合成学習データ生成方法
14日前
カシオ計算機株式会社
鍵盤楽器
7日前
カシオ計算機株式会社
機材制御システムとその親機、子機、および機材制御プログラム
7日前
カシオ計算機株式会社
機材制御システムとその親機、子機、および機材制御プログラム
7日前
株式会社マリ
いびき防止装置、いびき防止方法、およびプログラム
9日前
エーアイエムアイ インコーポレイテッド
音楽生成器
7日前
日産自動車株式会社
シート状防音構造体、並びにこれを用いた自動車用部品およびダクト閉塞用蓋部品
7日前
ウェルヴィル株式会社
プログラム及び情報処理方法
1日前
日東電工株式会社
アクティブノイズコントロールシステム及びアクティブノイズコントロール方法
3日前
ドルビー・インターナショナル・アーベー
深層生成ネットワークを用いたリアルタイムパケット損失隠蔽
7日前
ドルビー ラボラトリーズ ライセンシング コーポレイション
ディープニューラルネットワークを用いた適応ブロックスイッチング
1日前
ドルビー・インターナショナル・アーベー
フィルタバンク領域でオーディオサンプルを処理するための生成ニューラルネットワークモデル
1日前
コーニンクレッカ フィリップス エヌ ヴェ
環境内の音声を表すビットストリーム
15日前
株式会社サンセイアールアンドディ
遊技機
14日前
コニカミノルタ株式会社
放射線検出装置
7日前
シャープ株式会社
動画像復号装置および動画像符号化装置
1日前
他の特許を見る










 特許ウォッチ
特許ウォッチ