TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024152561
公報種別
公開特許公報(A)
公開日
2024-10-25
出願番号
2023171074
出願日
2023-10-02
発明の名称
回収されたデータを使用する高速でエネルギー効率に優れたCMOS2P1R1Wレジスタファイルアレイ
出願人
メティス マイクロシステムズ,エルエルシー
代理人
個人
,
個人
,
個人
,
個人
主分類
G11C
11/419 20060101AFI20241018BHJP(情報記憶)
要約
【課題】回収されたデータを利用してエネルギー散逸を自己制限するときに2ポート/マルチポートレジスタファイルアレイの回路速度を向上させるとともに、ローカルビット経路およびグローバルビット経路に沿ってデータを移動する際のエネルギーコストを大幅に削減する。
【解決手段】回収されたデータの電位が信号発生からのBL電圧と一致するときに、選択されたセルのアクションを自己無効化すると同時に、従来の検知方式よりも列ごとに必要な周辺回路トランジスタの数を少なくすることによって、セル読み出し電流の統計的変動に起因するBL信号発生の不確実性が解消される。
【選択図】図1
特許請求の範囲
【請求項1】
複数の従来の8トランジスタ2ポート記憶素子であって、それぞれが1つの読み出しポートおよび1つの書き込みポートを備え、それぞれが一対のNFETの分離された読み出しスタックを備え、前記対のうちの一方のゲート入力が読み出しワード線によって駆動され、前記対のうちの他方のゲート入力がセルストレージノードによって駆動される、複数の従来の8トランジスタ2ポート記憶素子と、
従来のレジスタファイル記憶素子におけるFETの前記分離された読み出しスタックの基準接地電位端子に取って代わる回収端子と、
複数の記憶素子の前記回収端子に結合された回収回路であって、前記回収端子の読み出しポートが共通のビット線に沿って結合され、前記回収回路が、前記ビット線上の信号の発生を自己無効化すること、読み出しスタックの読み出し電流の統計的変動に起因する前記ビット線での信号電圧発生の不確実性を解消すること、および選択された記憶素子で検知されたデータが解決される速度を少なくとも2倍にすることによって、読み出しアクセスに応答する、回収回路と
を備えるレジスタファイルメモリデバイス。
続きを表示(約 2,200 文字)
【請求項2】
複数のトランジスタ記憶素子であって、前記複数のトランジスタ記憶素子のうちのトランジスタ記憶素子が読み出しポートおよび書き込みポートを含み、前記複数のトランジスタ記憶素子のうちの前記トランジスタ記憶素子が第1のnチャネル電界効果トランジスタ(NFET)および第2のNFETに電気的に結合され、前記第2のNFETが、読み出しワード線を含むビットセルによって駆動されるように構成されたゲート端子を含み、前記第1のNFETが、ソース端子およびゲート端子を含み、前記第1のNFETの前記ゲート端子が、前記トランジスタ記憶素子からの前記読み出しポートのセルストレージノードによって駆動されるように構成される、複数のトランジスタ記憶素子と、
前記複数のトランジスタ記憶素子のうちの前記トランジスタ記憶素子の前記読み出しポートに電気的に接続され、プリチャージされるように構成された、ビット線と、
前記第1のNFETの前記ソース端子に電気的に結合された回収ノードであって、読み出しアクセスアクションおよび前記セルストレージノードの活性化に応答して、前記ビット線でプリチャージされた電圧を前記回収ノードにおいて回収するように構成された、回収ノードと、
前記回収ノードに置き換えられるように構成された基準接地電位端子を含む回収インバータであって、前記複数のトランジスタ記憶素子のうちの前記トランジスタ記憶素子の前記読み出しポートに電気的に結合されるように構成されたゲート端子を含む、回収インバータと、
前記回収ノードに電気的に結合された回収グリッドであって、前記回収ノード上で回収されたデータの電位が信号発生からの前記ビット線における電圧と一致するとき、前記ビット線上の前記信号発生を自己無効化して前記ビット線上の前記信号発生の不確実性を解消するように構成される、回収グリッドと
を備える装置。
【請求項3】
前記回収ノードが、電圧の放電を可能にするアクティブハイパルスを前記第1のNFETの前記ゲート端子に有する前記第1のNFETを介して、前記読み出しアクセスの前に前記電圧を基準接地電位に放電するように構成される、請求項2に記載の装置。
【請求項4】
前記回収インバータの前記ゲート端子が前記ビット線に電気的に結合され、前記回収インバータが、(1)前記セルストレージノードがアクティブであり前記第1のNFETもしくは前記第2のNFETに電気的に結合されているときの、プリチャージされた前記ビット線と前記読み出しアクセス中の前記回収ノードとの間の電位の減少によって、または(2)前記トランジスタ記憶素子に電気的に結合されている電源端子における電圧に実質的に等しい電圧によって、トリガされるように構成された出力端子を含み、前記出力端子が、前記回収インバータの前記ゲート端子から前記回収ノードへの電荷の移動によってトリガされるように構成される、請求項3に記載の装置。
【請求項5】
前記装置が、前記第1のNFETのドレイン端子および前記第2のNFETのドレイン端子に電気的に接続されたグローバルビット線に前記回収インバータの前記ゲート端子が電気的に接続され、前記第1のNFETの前記ゲート端子および前記第2のNFETの前記ゲート端子が前記ビット線によって駆動されるように、グローバル検知方式を実行するように構成され、
前記回収インバータの前記基準接地電位端子が、前記第1のNFETの前記ソース端子に電気的に結合されたグローバル回収端子に置き換えられるように構成され、前記グローバル回収端子が、前記回収インバータの出力端子における上昇出力によって前記第1のNFETがトリガされるときにプリチャージされる前記グローバルビット線から電荷を回収するように構成される、請求項2に記載の装置。
【請求項6】
読み出し安定性マージンを損なうことなくより高い読み出し性能を可能にするために、前記複数のトランジスタ記憶素子のうちの前記トランジスタ記憶素子が前記第1のNFETおよび前記第2のNFETから分離されるように構成される、請求項2に記載の装置。
【請求項7】
前記ビット線における電圧の放電が、前記回収ノードにおける上昇電圧が前記第1のNFETの前記ゲート端子におけるノイズ電圧に漸近的に近づいていることに応答して停止するように構成される、請求項2に記載の装置。
【請求項8】
前記ビット線で発生する電圧信号が、前記ビット線と前記回収ノードとの間に電気的に結合された容量分圧器によって決定される、請求項2に記載の装置。
【請求項9】
前記回収ノードに蓄積された回収された電荷が、前記回収ノードにある前記回収された電荷が前記ビットストレージノードでのノイズ電圧に近づいたときに、読み出し電流の流れを自己無効化するように構成される、請求項2に記載の装置。
【請求項10】
前記ビット線上での前記信号発生が、前記回収ノードにおける前記回収されたデータの電位が上昇して前記ビット線の降下電圧を等化するときに、自己無効化するように構成される、請求項2に記載の装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
関連出願の相互参照
本出願は、2021年9月22日に出願された「Fast,Energy Efficient Cmos 2p1r1w Register File Array Using Harvested Data」と題する米国仮出願第63/247,136号および2021年1月17日に出願された「Fast,Energy Efficient Cmos 2p1r1w Register File Array Using Harvested Data」と題する米国仮出願第63/138,456号に対する優先権を主張する、2022年1月19日に出願された「Fast,Energy Efficient Cmos 2p1r1w Register File Array Using Harvested Data」と題する米国特許出願第17/578,482号に対する優先権を主張するとともにその継続であり、これらはそれぞれ、その内容全体が参照により本明細書に組み込まれる。本出願は、2021年9月22日に出願された「Fast,Energy Efficient Cmos 2p1r1w Register File Array Using Harvested Data」と題する米国仮出願第63/247,136号に対する優先権を主張する。
続きを表示(約 3,600 文字)
【背景技術】
【0002】
A.序論
図17-24a~図17-24cに参考文献[1]-[30]を示す。CMOSチップのチップ電力密度は30年以上にわたり定電界(Dennard)スケーリングによって一定に保たれてきたが[1]、MOSFET閾値電圧をスケーリングすることによるリークの指数関数的な増加に起因したゲートオーバードライブの非スケーリング性によって回路速度が低下することに伴い[5~6]、低動作電圧およびスケーリングされた形状でCMOSデバイスの電気的変動が増加することにより[2~4]、スケーリングによるCMOS電圧は1Vよりはるかに低い値に制限されている。これらの制限により、定電界スケーリングは2004年に終焉を迎えた[7]。定電圧スケーリングでは、チップ電力密度はスケーリング係数の3乗に比例して増加し[8]、熱除去効率が低いことによりプロセッサクロック周波数が5GHz未満に制限されているため[9]、そのエネルギー効率によってプロセッサの性能はますます制約される。
【0003】
[10]における様々な算術演算およびメモリアクセスのエネルギー消費量は、算術演算に消費されるエネルギーよりもメモリアクセスでのデータ移動で消費されるエネルギーの方が相対的なエネルギーコストが高いことを示している。プロセッサのキャッシュのミス率を下げることによってメモリストール時間を性能に応じてスケーリングするために、CPUチップには大規模な最終レベルキャッシュが含まれている。しかし、メモリビットセルの大部分はほとんどの時間アイドル状態であるので、大規模なオンチップCPUキャッシュメモリのエネルギー散逸は、CPUのエネルギーの50%以上を消費するキャッシュおよびレジスタファイル(RF)によるリークによって支配される[10]。
【0004】
深層ニューラルネットワーク(DNN)モデルの訓練は、単純な行列数値演算および畳み込み算出で構成されており、計算を並列で実行できればこれらの速度を大幅に高めることができるので、AIワークロードを高速化するためにCPUよりもGPUが広く好まれている。GPUは、数万のスレッドを使用して、エクストリームマルチスレッドによる高スループット性能を追求する[11]。エクストリームマルチスレッドは、複雑なスレッドスケジューラおよび大きなレジスタファイルを必要とし、エネルギーとレイテンシとの両方の点でアクセスにコストがかかる[12]。GPUでは、DNN処理のボトルネックはメモリアクセスにあり、各積和(MAC)演算には、メモリ読み出しアクセス3回、メモリ書き込みアクセス1回が必要である[13]。データの再利用およびデータのローカル蓄積を最大化するエネルギー効率に優れたデータフローでは、レジスタファイルアレイによって消費されるエネルギーが、MAC演算のエネルギーの70%近くに寄与する[13]。
【0005】
CPU内の各スレッドは、そのレジスタコンテキストをオンチップで記憶しなければならない。大規模な最終レベルのオンチップキャッシュを使用して単一スレッドのレイテンシを隠すCPUとは異なり、GPUは、多数のスレッドを使用し、それらを切り替えることでメモリアクセスのレイテンシを隠す[14]。これらのスレッドのレジスタコンテキストを保持するだけでも、かなりのオンチップストレージが必要になる。数万のスレッドを備えたレジスタファイルアレイは、現在のGPUにおける最大のオンチップメモリリソースのうちの1つであり[15]、レジスタファイルおよびSRAMバッファがCPU性能、有効電力、リークの制限要因となっている[16]。
【0006】
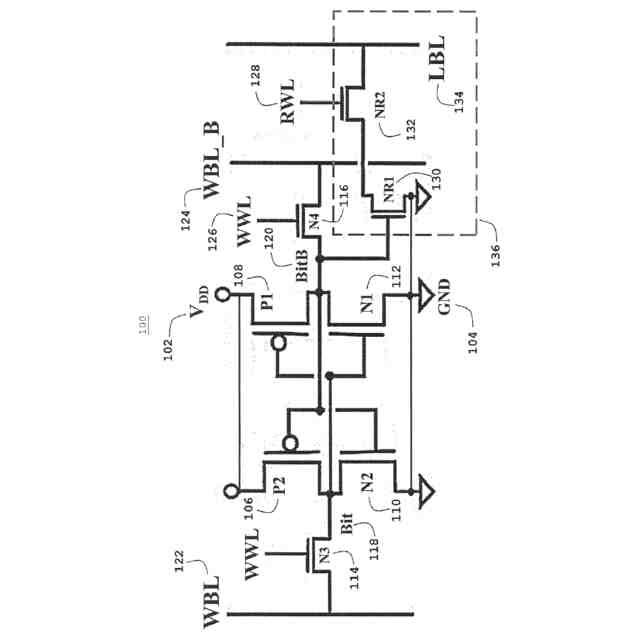
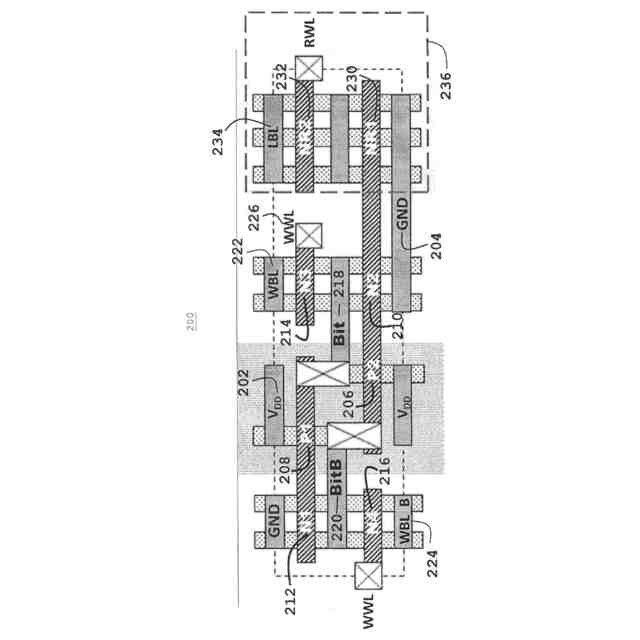
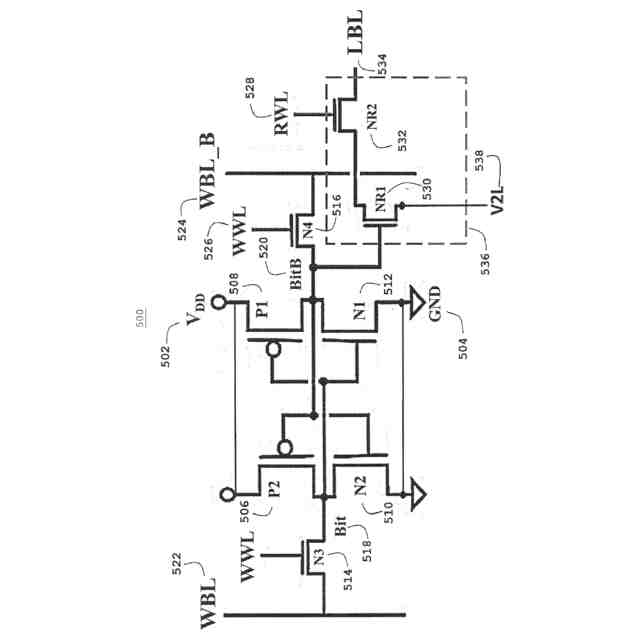
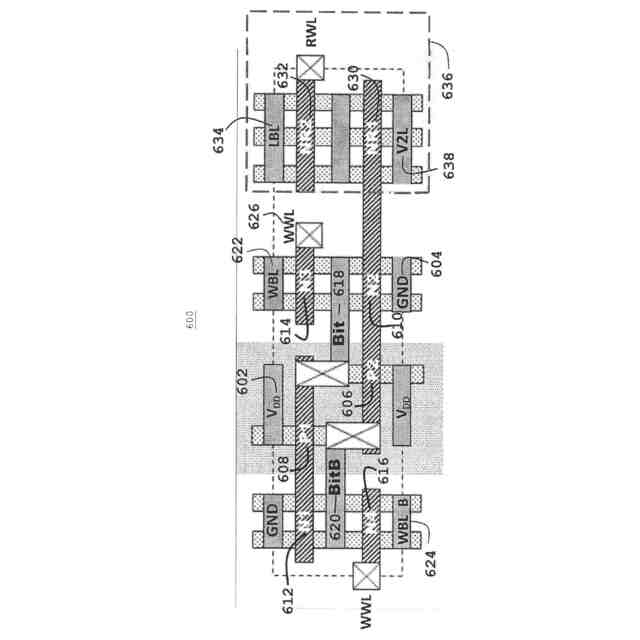
B.先行技術:従来の2ポートIRIWレジスタファイルアレイ回路
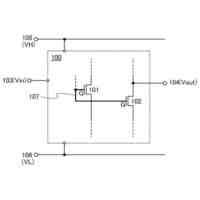
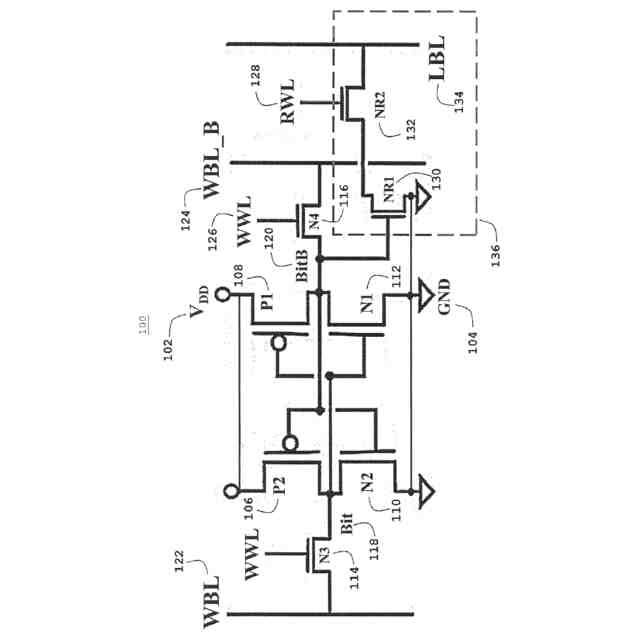
(i)図1の100(概略図)および図2の200(レイアウト)に示す2ポートレジスタファイル(2P RF)ビットセルは、LBL、134、234でより高速な信号発生速度を提供するとともに、従来の6T SRAMビットセルと比較してVMINが低いことを実証する。2P RFセルは、主に、メモリアクセススループット性能を高めるために同じサイクルでメモリに対する読み出しと書き込みとの両方のアクセスが必要な場合に使用され、高速NFETトランジスタ、すなわち破線ボックス136、236に示す読み出しスタック内のNR1 130、230、およびNR2 132、232を使用して、ローカルビット線LBL134、234に接続されたビットセルの分離された読み出しポートにおいてより高い読み出し電流を達成する。読み出しスタック136、236の分離は、6T SRAMセルで必要とされるようなより高い読み出し安定性マージンとトレードオフする必要なしに、より高い読み出し性能を可能にする。分離された読み出しスタックは、低電圧での書き込みマージンをより低いVMINに合わせて個別に最適化することも可能にする。2P RFビットセル内の読み出しポートを駆動する図1の100、図2の200の分離されたNFET読み出しスタック(NR1 130、230、NR2 132、232)はまた、通常は性能に合わせて最適化されるが、他のビットセルデバイスよりもリークが多い。
【0007】
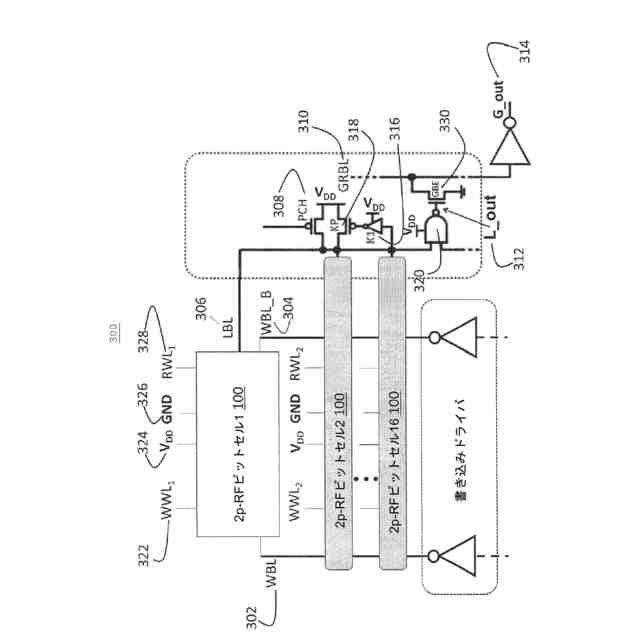
想定されている従来の2P RFビット経路(図3の300)はベースライン基準として機能し、このベースライン基準に対する改善は、一般的に産業界および学術界から同様に報告されている[17~20]。これらの最近(過去4年以内)の基準はすべて、レジスタファイルアレイの実装を比較するためのベースライン基準としてこの「ドミノ読み出し」フルスイングビット線手法を前提としている。
【0008】
(ii)論理ゲートを用いたフルスイング短BL検知:小信号差動検知は、面積のオーバーヘッドが小さいこと、また動作がロバストであることから、典型的には6Tアレイで使用されるが、差動検知増幅器が論理回路内の遅延スケーリングを追跡せず、ビット線上の小信号発生速度がビット線の負荷容量に依存し、デバイスの形状に合わせてスケーリングしない各ビットセル内のローカル相互接続によって支配されるので[21]、RFアレイにとってはそれほど魅力的ではない。またトランジスタ寸法のスケーリングは、検知増幅器入力での不規則な不整合を悪化させて[22]、大きな検知増幅器電圧オフセットにつながり、BL信号はこのオフセットを性能のオーバーヘッドとして克服しなければならない。
【0009】
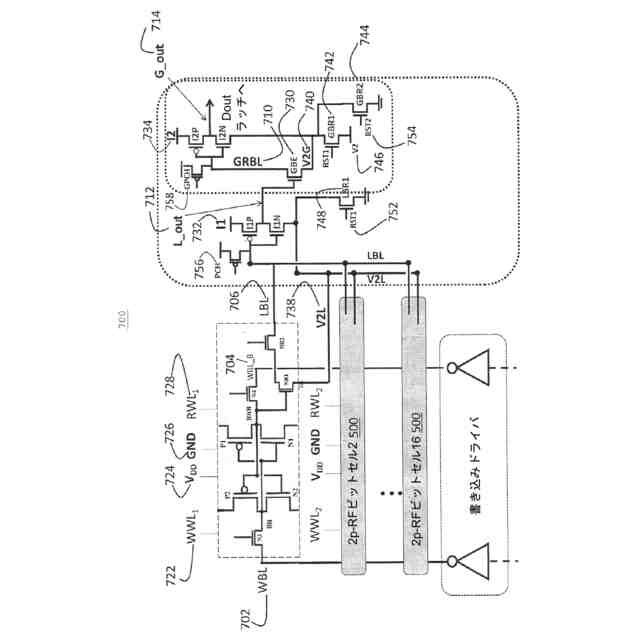
図3に示すRFアレイ用の代替の大信号検知方式は、NANDゲート[21]および短ビット線(16/32ビット/BL)を使用する。「ドミノ読み出し」方式では、検知用のスタティックCMOS回路、短ビット線、およびビット線上のレール間スイングが、差動検知で見られる性能スケーリング問題を解消する一方で、上部金属レベルのグローバルビット線が、検知データをアレイの高さ全体にわたって低抵抗でルーティングする。この方式は2P RFアレイ用に業界全体で広く採用されており、2P RFアレイは、(GPU)チップサイズならびにスイッチングおよびリーク電力の点で高コストでありながら、GPUにおいて論理ゲート技術によってスケーリングするはるかに高い性能を実現することが可能になる。
【0010】
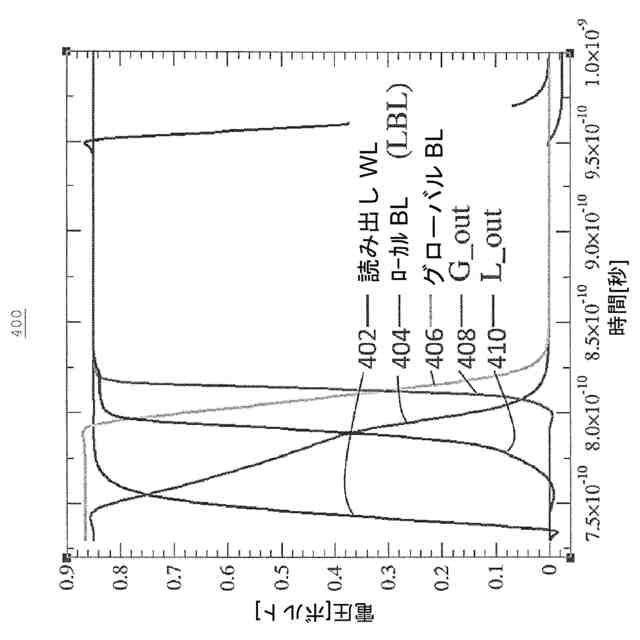
(iii)動的読み出しアクセス:出力ノードをプリチャージして、評価中に入力が安定した状態でクロックエッジの到着時にはるかに高速に評価できるようにする動的回路は、事実上すべての高速メモリアレイにおいて見られる。ローカルビット線およびグローバルビット線のプリチャージ、ならびに読み出しWL選択遷移の到着エッジでのビットセルによるそれらの評価は、2P RFビットセルアレイの一例である。しかし、評価中に(図4のLBLおよびGRBLから)基準接地電位に廃棄されたすべての電荷を次の読み出しサイクル前のBLプリチャージ段階中に再供給する必要があるので、これらの技法はエネルギー効率が悪い。典型的な2P RFアレイインスタンス[23]では、8KBインスタンス内の読み出しWLによって256ものローカルBL列がアクセスされる。しかし、同じサイクル中にWL方向の数行のみが選択され(読み出しWL、書き込みWL、プリチャージ、およびWL方向の他のいくつかの制御信号)、2P RFアレイ内にビットセルから出力ラッチまでのビット経路を作成し、これは2P RFアレイ内の主要な(>95%)エネルギー消費構成要素となる。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社半導体エネルギー研究所
半導体装置
今日
株式会社東芝
磁気ディスク装置及びデータ制御方法
5日前
ワシントン・ユニバーシティ
抗APOE抗体
7日前
他の特許を見る

 特許ウォッチ
特許ウォッチ