TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025137328
公報種別
公開特許公報(A)
公開日
2025-09-19
出願番号
2024091632
出願日
2024-06-05
発明の名称
推論装置、学習装置、推論方法、及びプログラム
出願人
NTT株式会社
,
国立大学法人東北大学
代理人
弁理士法人ITOH
,
個人
,
個人
,
個人
主分類
G06F
40/56 20200101AFI20250911BHJP(計算;計数)
要約
【課題】テキストを含むデータから、当該データに関する視覚的情報に明示的に基づいた特徴を生成する。
【解決手段】推論装置において、テキストを含むデータから抽出された視覚的情報であって、前記テキストに関する視覚的情報と、第1テキストとから学習済みモデルに基づいて特徴を生成し、前記特徴を生成部に入力するために出力する特徴生成部を備え、前記生成部は、前記特徴と前記第1テキストとに基づいて第2テキストを出力する。
【選択図】図14
特許請求の範囲
【請求項1】
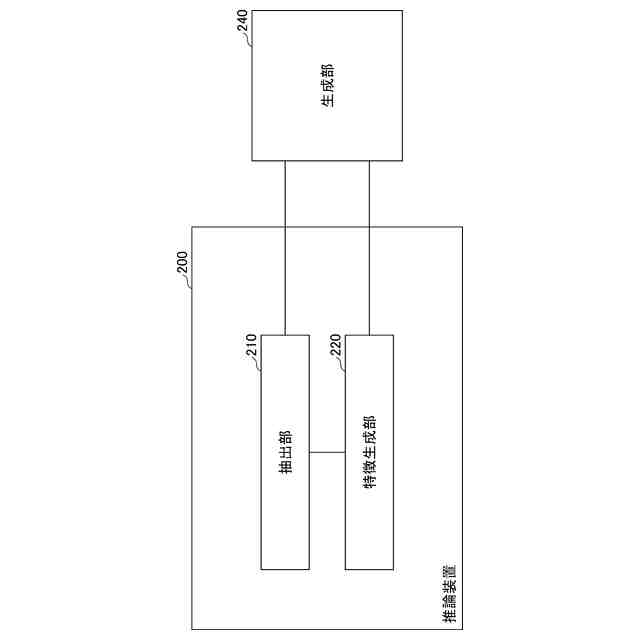
テキストを含むデータから抽出された視覚的情報であって、前記テキストに関する視覚的情報と、第1テキストとから学習済みモデルに基づいて特徴を生成し、前記特徴を生成部に入力するために出力する特徴生成部、を備え、
前記生成部は、前記特徴と前記第1テキストとに基づいて第2テキストを出力する
推論装置。
続きを表示(約 810 文字)
【請求項2】
前記視覚的情報は、前記データにおける前記テキストの領域を示す領域情報と、前記データにおける画像特徴とを含み、前記特徴生成部は、前記視覚的情報と、前記データから抽出された第3テキストと、前記第1テキストとから前記学習済みモデルに基づいて前記特徴を生成する
請求項1に記載の推論装置。
【請求項3】
前記特徴生成部は、前記テキストに重みを付けた情報と前記領域情報に重みを付けた情報とを用いて前記特徴を生成する
請求項2に記載の推論装置。
【請求項4】
テキストを含むデータから抽出された視覚的情報であって、前記テキストに関する視覚的情報と、第1テキストとから特徴を生成し、前記特徴を生成部に入力するために出力する特徴生成部と、
前記特徴及び前記第1テキストが入力された前記生成部から出力される情報と、前記データ及び前記第1テキストに対する正解の第2テキストとを用いて、前記特徴生成部を構成するニューラルネットワークのモデルパラメータを学習する学習部と、
を備える学習装置。
【請求項5】
推論装置が実行する推論方法であって、
テキストを含むデータから抽出された視覚的情報であって、前記テキストに関する視覚的情報と、第1テキストとから特徴を生成し、前記特徴を生成部に入力するために出力するステップを備え、
前記生成部は、前記特徴と前記第1テキストとに基づいて第2テキストを出力する
推論方法。
【請求項6】
コンピュータを、請求項1ないし3のうちいずれか1項に記載の前記推論装置における前記特徴生成部として機能させるためのプログラム。
【請求項7】
コンピュータを、請求項4に記載の前記学習装置における前記特徴生成部、及び前記学習部として機能させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、文書画像に基づいてテキストを出力する技術に関連するものである。
続きを表示(約 1,600 文字)
【背景技術】
【0002】
テキストや画像が様々な位置に配置された文書画像を対象としたタスクを実行する技術が知られている。そのようなタスクとして、例えば、文書画像を知識源として、質問に対して回答テキストを生成する質問応答タスク、文書画像内の特定の情報を抽出する情報抽出タスク等がある。
【0003】
自然の風景等を写した画像である自然画像を対象としたタスクを実行する従来技術の1つとして非特許文献1に開示された技術が知られている。非特許文献1に開示された技術では、事前学習済みの大規模言語モデル(LLM:Large Language Model)が使用されている。
【先行技術文献】
【非特許文献】
【0004】
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. ICML23
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかし、非特許文献1に開示された従来技術では、文書画像を入力とした際に、当該文書画像における、テキストに関するレイアウト情報等の視覚的情報を明示的に考慮した特徴を用いることができない。なお、文書画像は「テキストを含むデータ」の例である。
【0006】
本発明は上記の点に鑑みてなされたものであり、テキストを含むデータから、当該データに関する視覚的情報に明示的に基づいた特徴を生成するための技術を提供することを目的とする。
【課題を解決するための手段】
【0007】
開示の技術によれば、テキストを含むデータから抽出された視覚的情報であって、前記テキストに関する視覚的情報と、第1テキストとから学習済みモデルに基づいて特徴を生成し、前記特徴を生成部に入力するために出力する特徴生成部、を備え、
前記生成部は、前記特徴と前記第1テキストとに基づいて第2テキストを出力する
推論装置が提供される。
【発明の効果】
【0008】
開示の技術によれば、テキストを含むデータから、当該データに関する視覚的情報に明示的に基づいた特徴を生成するための技術が提供される。
【図面の簡単な説明】
【0009】
タスクの例1を示す図である。
タスクの例2を示す図である。
タスクの例3を示す図である。
タスクの例4を示す図である。
タスクの例5を示す図である。
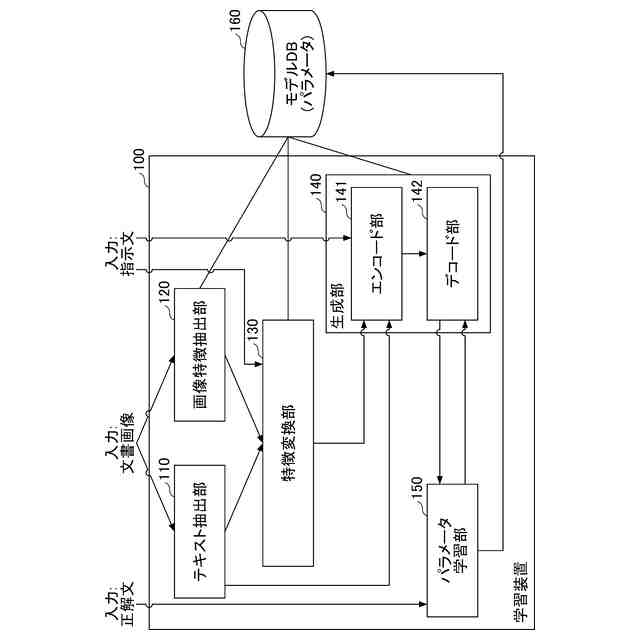
学習装置100の構成例を示す図である。
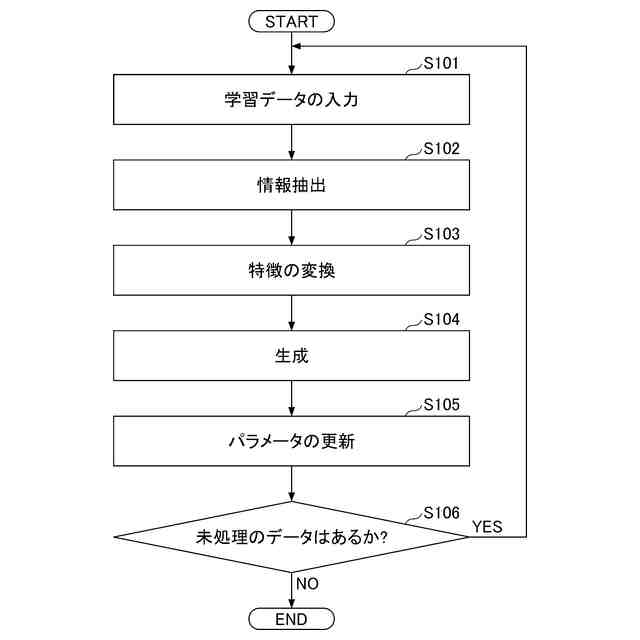
学習装置100の動作例を示すフローチャートである。
生成部140の内部構成例を示す図である。
更新するパラメータと更新しないパラメータを示す図である。
推論装置200の構成例を示す図である。
更新するパラメータと更新しないパラメータを示す図である。
推論装置200の動作例を示すフローチャートである。
学習装置100の他の構成例を示す図である。
推論装置200の他の構成例を示す図である。
装置のハードウェア構成例を示す図である。
【発明を実施するための形態】
【0010】
以下、図面を参照して本発明の実施の形態(本実施の形態)を説明する。以下で説明する実施の形態は一例に過ぎず、本発明が適用される実施の形態は、以下の実施の形態に限られるわけではない。
(【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
他の特許を見る
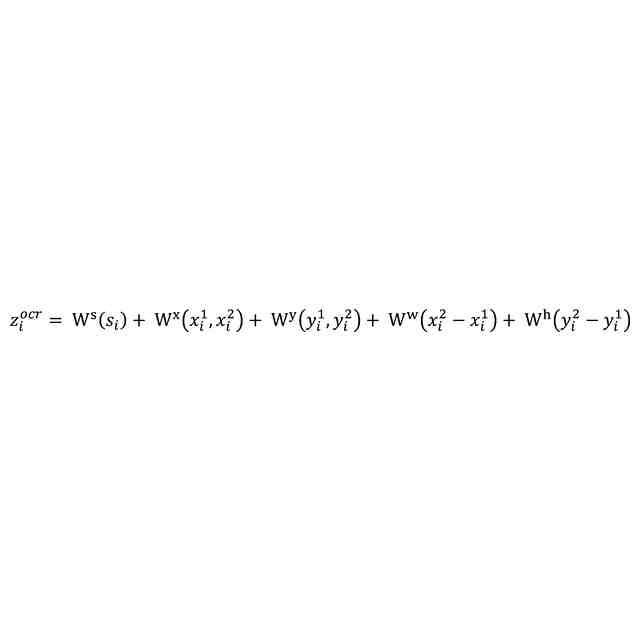
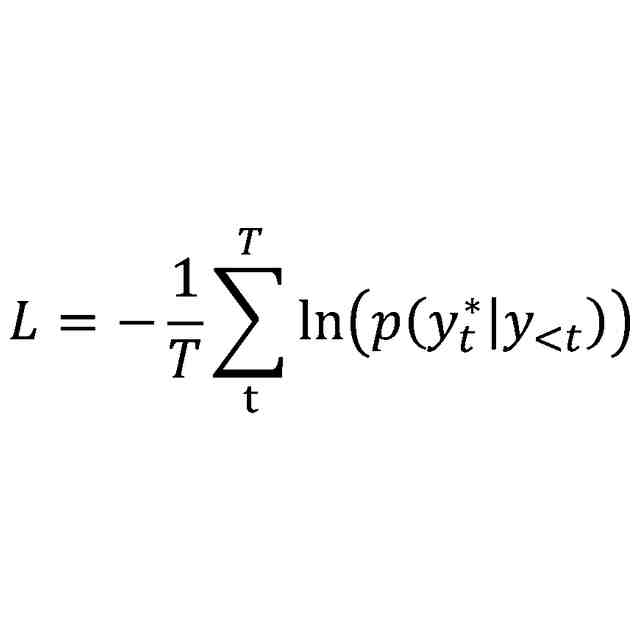



 特許ウォッチ
特許ウォッチ