TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025137268
公報種別
公開特許公報(A)
公開日
2025-09-19
出願番号
2024036377
出願日
2024-03-08
発明の名称
学習器、学習方法、およびプログラム
出願人
本田技研工業株式会社
代理人
個人
,
個人
,
個人
主分類
G06N
3/008 20230101AFI20250911BHJP(計算;計数)
要約
【課題】従来より実装が実用的にできる人の状態の推定を行うことができる学習器、学習方法、およびプログラムを提供することを目的とする。
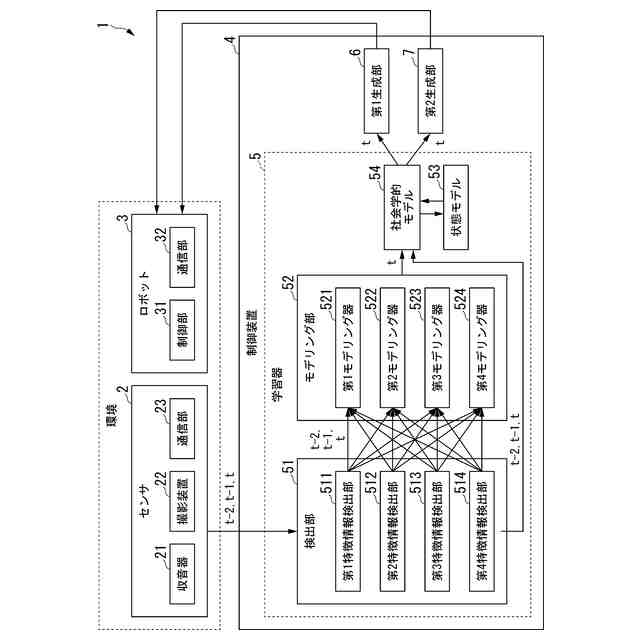
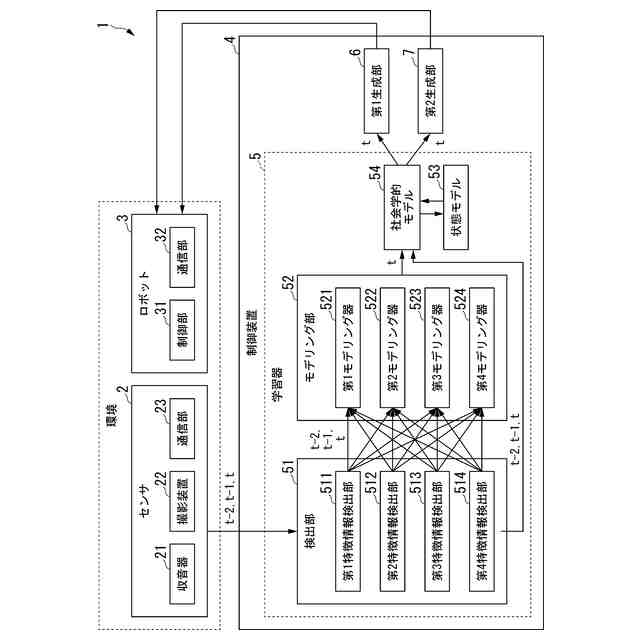
【解決手段】学習器は、複数の人が存在する環境において、視聴覚情報に基づく複数の人の状態に関する情報である複数のセンシングデータを取得する検出部と、取得された複数のセンシングデータを用いて、複数の人の注意に関する情報である複数のモデリングデータを作成するモデリング部と、複数のモデリングデータを入力して、複数の人が存在する環境にいて複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力するモデルと、を備える。
【選択図】図2
特許請求の範囲
【請求項1】
複数の人が存在する環境において、視聴覚情報に基づく複数の前記人の状態に関する情報である複数のセンシングデータを取得する検出部と、
取得された複数の前記センシングデータを用いて、複数の前記人の注意に関する情報である複数のモデリングデータを作成するモデリング部と、
複数の前記モデリングデータを入力して、前記複数の人が存在する環境にいて前記複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力するモデルと、
を備える学習器。
続きを表示(約 1,000 文字)
【請求項2】
複数の前記センシングデータは、
前記複数の人それぞれが発話しているか否かを示す情報と、前記複数の人それぞれの上半身のボディランゲージ情報と、前記複数の人それぞれの位置情報と、前記複数の人それぞれの視線方向を示す情報のうちの少なくとも2つである、
請求項1に記載の学習器。
【請求項3】
前記モデリング部は、
前記モデルの社会的相互作用ダイナミクスを表現するためのノードとエッジからなるグラフを構築するために使用できる前記検出部からの情報を入力し、ノード埋め込み表現を前記モデルへ出力する、
請求項1または請求項2に記載の学習器。
【請求項4】
前記モデルは、
TGN(Temporal Graph Network)モデルに基づくモデルであり、
1つの時刻または複数の連続する時刻について、前記モデリング部が出力する前記モデリングデータを入力し、TGNのノード埋め込み表現に変換し、
変換された前記ノード埋め込み表現に基づく情報をガウスモデルへ入力し、前記ガウスモデルからの出力をデコーダーに入力して前記ロボットへの行動指令を作成する、
請求項1または請求項2に記載の学習器。
【請求項5】
検出部と、モデリング部と、モデルとを有する学習器の学習方法であって、
検出部が、複数の人が存在する環境において、視聴覚情報に基づく複数の前記人の状態に関する情報である複数のセンシングデータを取得し、
モデリング部が、取得された複数の前記センシングデータを用いて、複数の前記人の注意に関する情報である複数のモデリングデータを作成し、
モデルが、複数の前記モデリングデータを入力して、前記複数の人が存在する環境にいて前記複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力する、
学習方法。
【請求項6】
モデルを有する学習器のコンピュータに、
複数の人が存在する環境において、視聴覚情報に基づく複数の前記人の状態に関する情報である複数のセンシングデータを取得させ、
取得された複数の前記センシングデータを用いて、複数の前記人の注意に関する情報である複数のモデリングデータを作成させ、
複数の前記モデリングデータを入力して、前記複数の人が存在する環境にいて前記複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力させる、
プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、学習器、学習方法、およびプログラムに関する。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
例えば、ロボット等が人とコミュニケーションをとる場合は、人の状態を推定して対話等を行う技術が提案されている。人の状態を推定する手法として、例えば、脳波等を用いた生理学的反応、音声データ(例えば、特許文献1参照)、および顔の外観等の視覚データを用いる。なお、人間の状態は、内部刺激(経験、記憶など)、および外部刺激(他の人間、物体、環境など)の影響を受ける傾向がある。
【先行技術文献】
【特許文献】
【0003】
特開2019-191521号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来技術では、内部刺激や外部刺激の影響に対応するのが困難であり、人が話している最中にしか音声データが使えず、人が偽った表情をする場合もあるので信頼性が低く、脳波等の処理の実装に実用性がなかった。
【0005】
本発明は、上記の問題点に鑑みてなされたものであって、従来より実装が実用的にできる人の状態の推定を行うことができる学習器、学習方法、およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
(1)上記目的を達成するため、本発明の一態様に係る学習器は、複数の人が存在する環境において、視聴覚情報に基づく複数の前記人の状態に関する情報である複数のセンシングデータを取得する検出部と、取得された複数の前記センシングデータを用いて、複数の前記人の注意に関する情報である複数のモデリングデータを作成するモデリング部と、複数の前記モデリングデータを入力して、前記複数の人が存在する環境にいて前記複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力するモデルと、を備える学習器である。
【0007】
(2)上記(1)の一態様に係る学習器において、複数の前記センシングデータは、前記複数の人それぞれが発話しているか否かを示す情報と、前記複数の人それぞれの上半身のボディランゲージ情報と、前記複数の人それぞれの位置情報と、前記複数の人それぞれの視線方向を示す情報のうちの少なくとも2つであるようにしてもよい。
【0008】
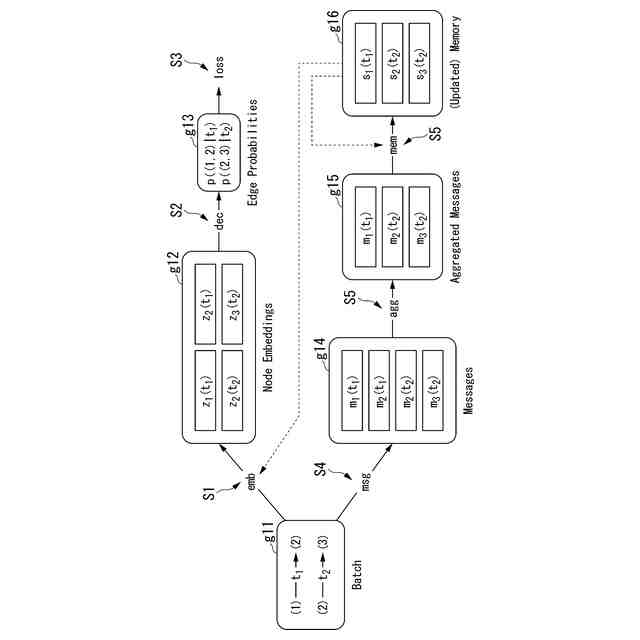
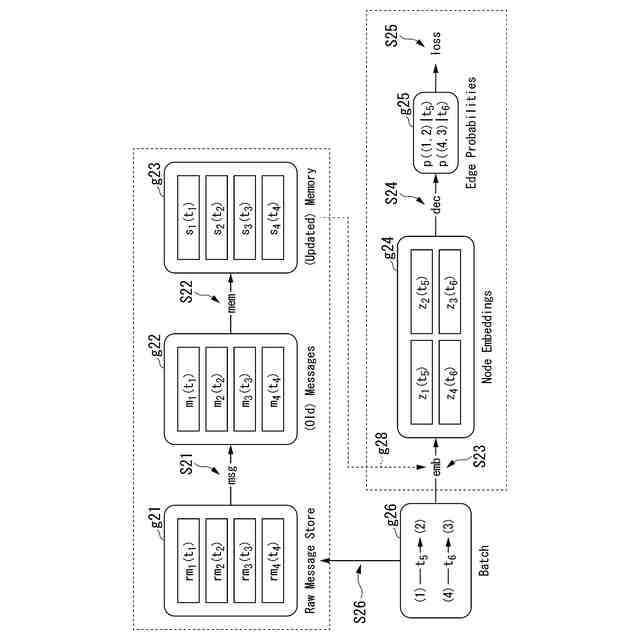
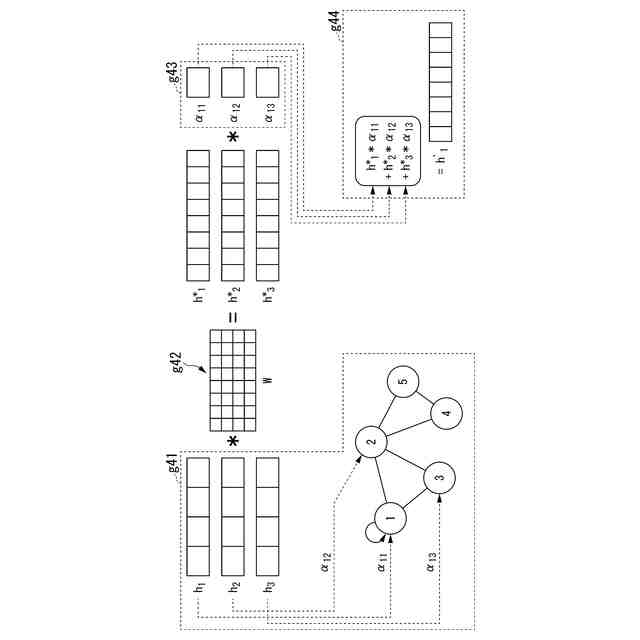
(3)上記(1)または(2)の一態様に係る学習器において、前記モデリング部は、前記モデルの社会的相互作用ダイナミクスを表現するためのノードとエッジからなるグラフを構築するために使用できる前記検出部からの情報を入力し、ノード埋め込み表現を前記モデルへ出力するようにしてもよい。
【0009】
(4)上記(1)から(3)のうちのいずれか1つの一態様に係る学習器において、前記モデリング部は、TGN(Temporal Graph Network)モデルに基づくモデルであり、1つの時刻または複数の連続する時刻について、前記モデリング部が出力する前記モデリングデータを入力し、TGNのノード埋め込み表現に変換し、変換された前記ノード埋め込み表現に基づく情報をガウスモデルへ入力し、前記ガウスモデルからの出力をデコーダーに入力して前記ロボットへの行動指令を作成するようにしてもよい。
【0010】
(5)上記目的を達成するため、本発明の一態様に係る学習方法は、検出部と、モデリング部と、モデルとを有する学習器の学習方法であって、検出部が、複数の人が存在する環境において、視聴覚情報に基づく複数の前記人の状態に関する情報である複数のセンシングデータを取得し、モデリング部が、取得された複数の前記センシングデータを用いて、複数の前記人の注意に関する情報である複数のモデリングデータを作成し、モデルが、複数の前記モデリングデータを入力して、前記複数の人が存在する環境にいて前記複数の人とコミュニケーションを行うロボットへの行動を制御する情報を出力する、学習方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
他の特許を見る
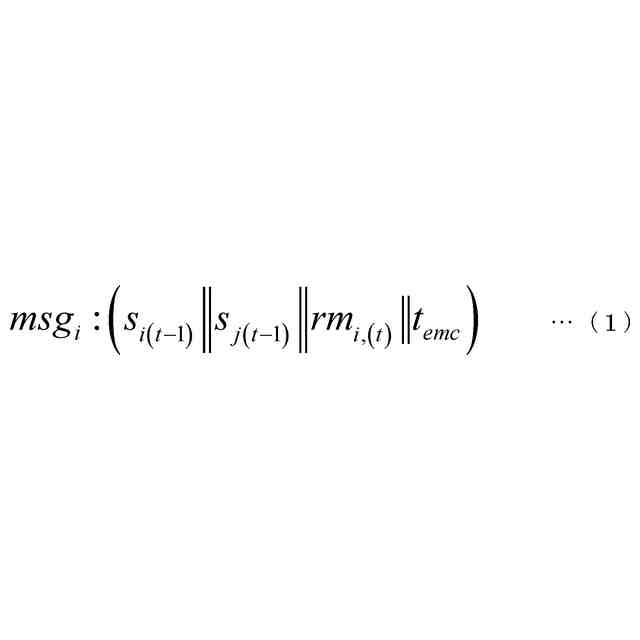
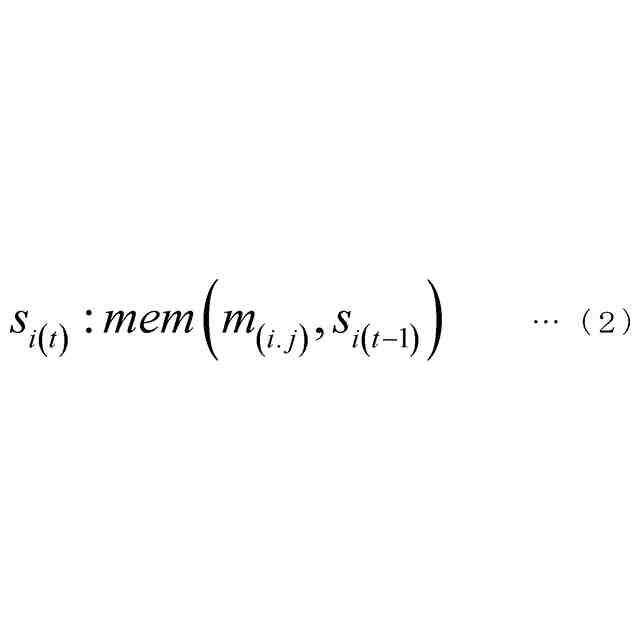
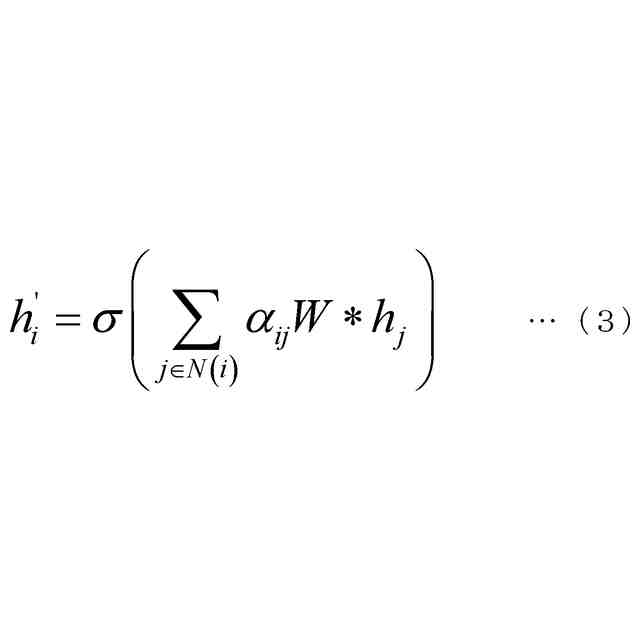
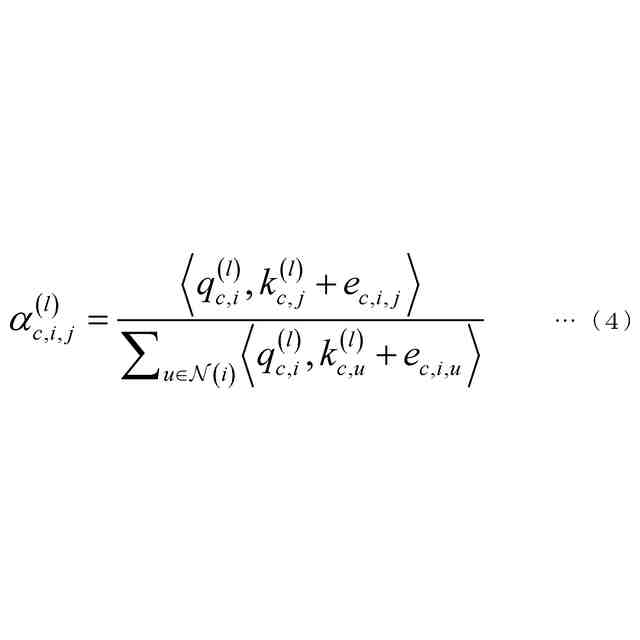
 特許ウォッチ
特許ウォッチ