TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025133124
公報種別
公開特許公報(A)
公開日
2025-09-11
出願番号
2024027507
出願日
2024-02-27
発明の名称
情報処理装置、情報処理方法及びプログラム
出願人
株式会社PKUTECH
代理人
個人
,
個人
主分類
G06F
16/9035 20190101AFI20250904BHJP(計算;計数)
要約
【課題】大規模言語モデル等を用いた際に、ユーザの欲しい回答を得るための質問を自動で生成する情報処理装置等を提供する。
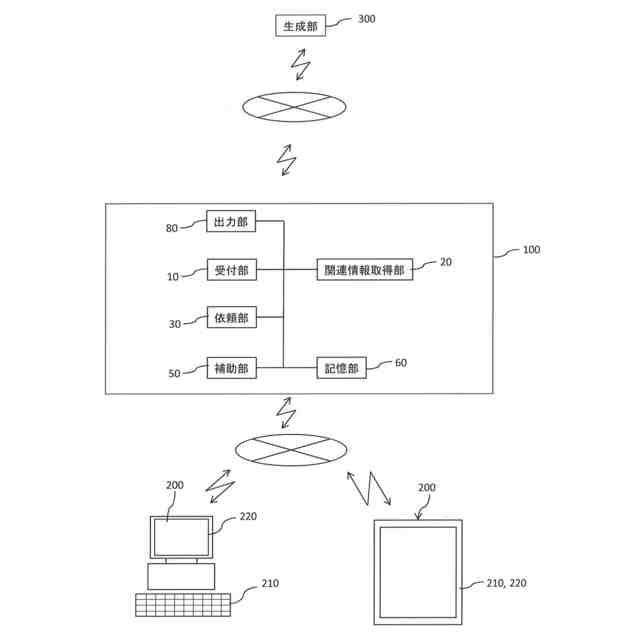
【解決手段】情報処理装置100は、ユーザから入力質問を受け付ける受付部10と、前記ユーザに関する関連情報を取得する関連情報取得部20と、前記入力質問と前記関連情報を生成部に出力し、前記生成部から回答を受領することで、第一質問を取得する依頼部30と、を有する。
【選択図】 図1
特許請求の範囲
【請求項1】
ユーザから入力質問を受け付ける受付部と、
前記ユーザに関する関連情報を取得する関連情報取得部と、
前記入力質問と前記関連情報を生成部に出力し、前記生成部から回答を受領することで、第一質問を取得する依頼部と、
を備える、情報処理装置。
続きを表示(約 950 文字)
【請求項2】
前記関連情報取得部は、前記ユーザの所属に関する情報を取得し、
前記依頼部は、前記関連情報として前記ユーザの所属に関する情報を用いる、請求項1に記載の情報処理装置。
【請求項3】
前記関連情報取得部は、前記ユーザのスケジュールに関する情報を取得し、
前記依頼部は、前記関連情報として前記ユーザのスケジュールに関する情報を用いる、請求項1又は2に記載の情報処理装置。
【請求項4】
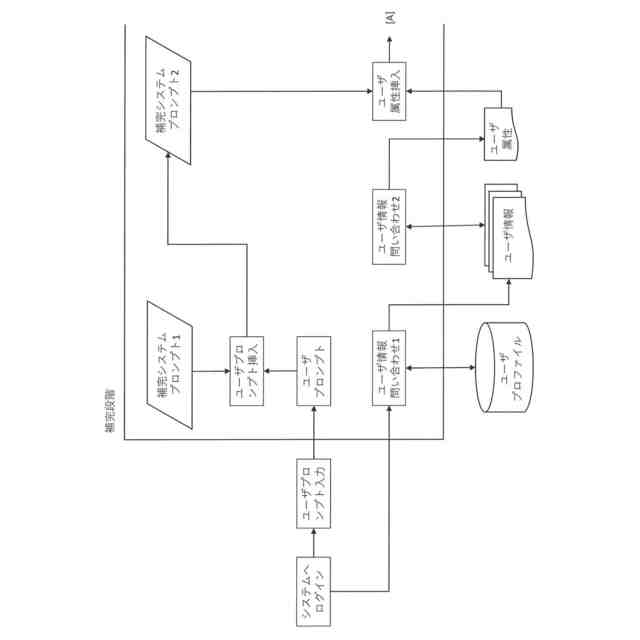
前記依頼部は、前記第一質問に対して、不足している第一不足情報の抽出を前記生成部に依頼する、請求項1又は2に記載の情報処理装置。
【請求項5】
前記依頼部は、前記生成部で抽出された不足している第一不足情報を出力し、ユーザからの入力を促す、請求項4に記載の情報処理装置。
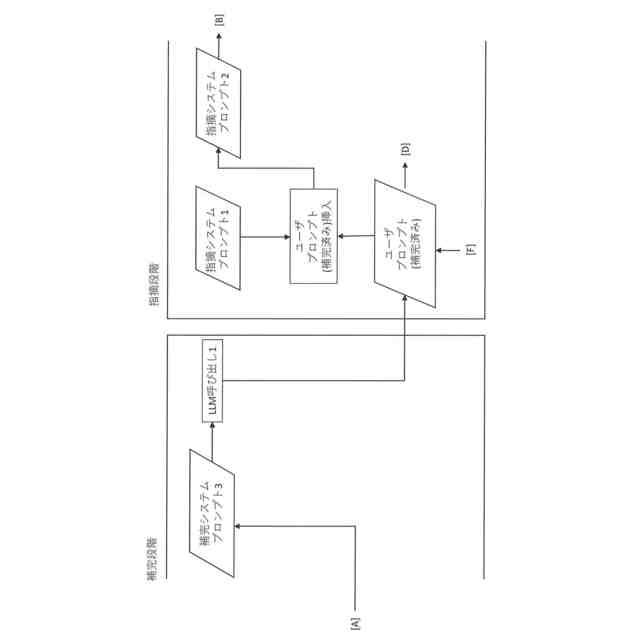
【請求項6】
前記依頼部は、前記第一不足情報に対応するユーザから入力された第一入力情報と前記第一質問を前記生成部に出力し、前記生成部から回答を受領することで、第二質問を取得する、請求項5に記載の情報処理装置。
【請求項7】
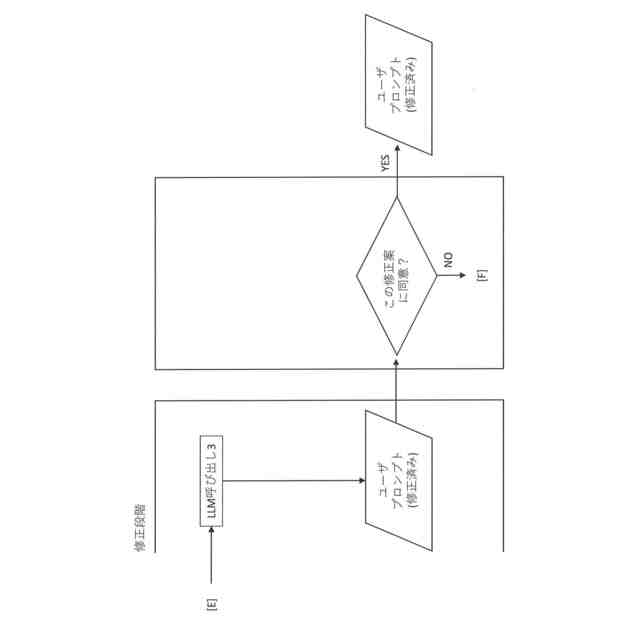
依頼部は、ユーザに対して前記第二質問に同意するか否かの入力を促す、請求項6に記載の情報処理装置。
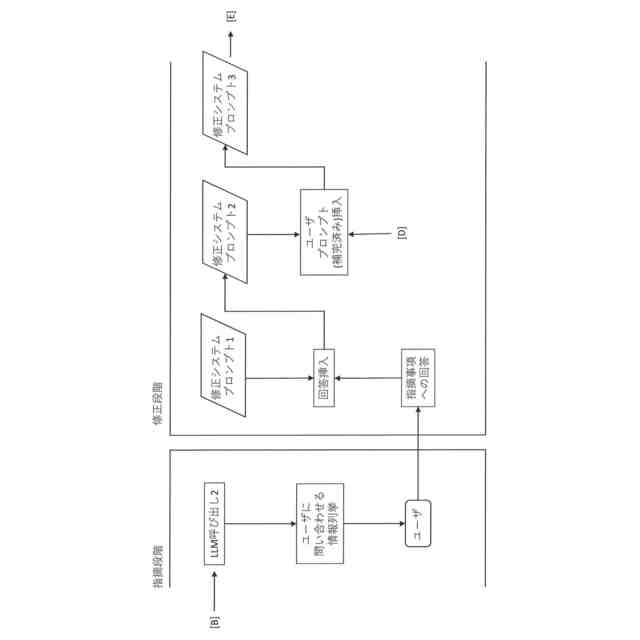
【請求項8】
ユーザが前記第二質問に同意しない場合、前記依頼部は、前記第二質問に対して、不足している第二不足情報の抽出を前記生成部に依頼する、請求項7に記載の情報処理装置。
【請求項9】
前記依頼部は、前記生成部で抽出された不足している第二不足情報をユーザに出力し、前記第二不足情報に対応するユーザから入力された第二入力情報と、前記第二質問を前記生成部に出力し、前記生成部から回答を受領することで、第二質問を取得する、請求項8に記載の情報処理装置。
【請求項10】
受付部によって、入力質問を受け付ける工程と、
関連情報取得部ユーザに関する関連情報を取得する工程と、
前記入力質問と前記関連情報を生成部に出力し、前記生成部から回答を受領することで、第一質問を取得する工程と、
を備える、情報処理方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、大規模言語モデル等を用いた際に、ユーザの欲しい回答を得るための質問を自動で生成する情報処理装置、情報処理方法及びプログラムに関する。
続きを表示(約 1,200 文字)
【背景技術】
【0002】
近年、ChatGPT等の人工知能機能を有する外部のチャットボットを利用することについて注目を集めている。例えば、特許文献1の[0041][0042]では、プロセッサ220が、特定のドメイン文書301内の内容に対して質疑回答(QA)が可能なチャットボットを生成するために大規模言語モデル310を用いることで、与えられた文書301から予想される質問を示すクエリデータ302を生成し、プロセッサ220が、言語モデル310で生成されたクエリデータ302を学習データとし、対話ボットのための検索モデル320の学習に利用することが示されている。
【0003】
他方で、ChatGPT等の人工知能機能を有する外部のチャットボットを利用する場合、どのように質問を行うかによって、回答の精度や内容の適切性等が異なるものとなっており、使い慣れていない人物が適切な質問を行うことが難しいという問題がある。
【先行技術文献】
【特許文献】
【0004】
特開2023‐076413号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
本発明は、大規模言語モデル等を用いた際に、ユーザの欲しい回答を得るための質問を自動で生成する情報処理装置、情報処理方法及びプログラムを提供する。
【課題を解決するための手段】
【0006】
[概念1]
本発明による情報処理装置は、
ユーザから入力質問を受け付ける受付部と、
前記ユーザに関する関連情報を取得する関連情報取得部と、
前記入力質問と前記関連情報を生成部に出力し、前記生成部から回答を受領することで、第一質問を取得する依頼部と、
を備えてもよい。
【0007】
[概念2]
概念1による情報処理装置において、
前記関連情報取得部は、前記ユーザの所属に関する情報を取得し、
前記依頼部は、前記関連情報として前記ユーザの所属に関する情報を用いてもよい。
【0008】
[概念3]
概念1又は2による情報処理装置において、
前記関連情報取得部は、前記ユーザのスケジュールに関する情報を取得し、
前記依頼部は、前記関連情報として前記ユーザのスケジュールに関する情報を用いてもよい。
【0009】
[概念4]
概念1乃至3のいずれか1つによる情報処理装置において、
前記依頼部は、前記第一質問に対して、不足している第一不足情報の抽出を前記生成部に依頼してもよい。
【0010】
[概念5]
概念4による情報処理装置において、
前記依頼部は、前記生成部で抽出された不足している第一不足情報を出力し、ユーザからの入力を促してもよい。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
他の特許を見る





 特許ウォッチ
特許ウォッチ