TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025118580
公報種別
公開特許公報(A)
公開日
2025-08-13
出願番号
2025014943
出願日
2025-01-31
発明の名称
学習装置、学習方法、およびプログラム
出願人
本田技研工業株式会社
代理人
個人
,
個人
,
個人
主分類
G06N
20/00 20190101AFI20250805BHJP(計算;計数)
要約
【課題】機械学習モデルが出力するロジットを高精度に補正することによって、生成される機械学習モデルの精度を向上させること。
【解決手段】データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習する学習部と、前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正する補正部と、を備え、前記学習部は、補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成する、学習装置。
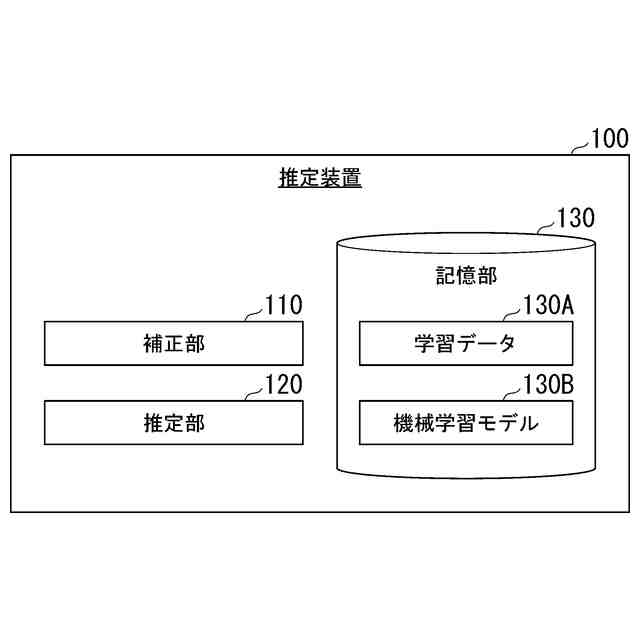
【選択図】図1
特許請求の範囲
【請求項1】
データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習する学習部と、
前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正する補正部と、を備え、
前記学習部は、補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成する、
学習装置。
続きを表示(約 1,100 文字)
【請求項2】
前記補正部は、以下の式(1)に従って、前記誤差関数Lを補正し、
TIFF
2025118580000024.tif
23
170
・・・(1)
式(1)において、Cは、分類対象となるクラスの総数を表し、kは、0以上C-1以下の全ての整数を表し、iは、0以上C-1以下のうち任意の整数を表し、Z
i
は、クラスiについて前記第1機械学習モデルによって出力されたロジットを表し、P(y
i
)は、前記第1機械学習モデルの学習に用いられた学習データのうち、クラスiのサンプルが発生する事前確率を表す、
請求項1に記載の学習装置。
【請求項3】
前記補正部は、式(1)にエントロピー正則化項をさらに追加することによって、前記誤差関数Lを補正する、
請求項2に記載の学習装置。
【請求項4】
前記補正部は、以下の式(2)に従って、前記誤差関数Lを補正し、
TIFF
2025118580000025.tif
23
170
・・・(2)
式(2)において、Cは、分類対象となるクラスの総数を表し、kは、0以上C-1以下の全ての整数を表し、iは、0以上C-1以下のうち任意の整数を表し、b
i
は、バイアス項を表し、λは、ハイパーパラメータを表し、ε(z)は、エントロピー正則化項を表す、
請求項1に記載の学習装置。
【請求項5】
コンピュータが、
データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習し、
前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正し、
補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成する、
学習方法。
【請求項6】
コンピュータに、
データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習させ、
前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正させ、
補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成させる、
プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、学習装置、学習方法、およびプログラムに関する。
続きを表示(約 1,800 文字)
【背景技術】
【0002】
従来、画像を入力として、当該画像に含まれる物体の種別をクラス分類する機械学習モデルの学習において、教師データ(サンプル)の数に関するクラス間の不均衡に伴うモデルの推定精度の低下を防止する技術が知られている。例えば、非特許文献1には、各クラスに対応するサンプルの数に応じて、学習に用いる誤差関数の重み(各クラスに対応する誤差関数の重み)およびロジット(機械学習モデルの出力値)を補正する技術が記載されている。
【先行技術文献】
【非特許文献】
【0003】
Menon et al., “Long-tail learning via logit adjustment”
【発明の概要】
【発明が解決しようとする課題】
【0004】
非特許文献1に記載の技術は、教師データ全体のサンプル数と、各クラスのサンプル数とを用いて、ロジットを補正するものである。しかしながら、このような簡易的手法では、ロジットが高精度に補正されず、結果として、生成される機械学習モデルの精度が低くなる場合があった。
【0005】
本発明は、このような事情を考慮してなされたものであり、機械学習モデルの学習に用いる誤差関数を高精度に補正することによって、生成される機械学習モデルの精度を向上させることができる学習装置、学習方法、およびプログラムを提供することを目的の一つとする。
【課題を解決するための手段】
【0006】
この発明に係る学習装置、学習方法、およびプログラムは、以下の構成を採用した。
(1):この発明の一態様に係る学習装置は、データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習する学習部と、前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正する補正部と、を備え、前記学習部は、補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成するものである。
【0007】
(2):上記(1)の態様において、前記補正部は、以下の式(1)に従って、前記誤差関数Lを補正し、
TIFF
2025118580000002.tif
23
170
・・・(1)
式(1)において、Cは、分類対象となるクラスの総数を表し、kは、0以上C-1以下の全ての整数を表し、iは、0以上C-1以下のうち任意の整数を表し、Z
i
は、クラスiについて前記第1機械学習モデルによって出力されたロジットを表し、P(y
i
)は、前記第1機械学習モデルの学習に用いられた学習データのうち、クラスiのサンプルが発生する事前確率を表すものである。
【0008】
(3):上記(2)の態様において、前記補正部は、式(1)にエントロピー正則化項をさらに追加することによって、前記誤差関数Lを補正するものである。
【0009】
(4):上記(1)の態様において、前記補正部は、以下の式(2)に従って、前記誤差関数Lを補正し、
TIFF
2025118580000003.tif
23
170
・・・(2)
式(2)において、Cは、分類対象となるクラスの総数を表し、kは、0以上C-1以下の全ての整数を表し、iは、0以上C-1以下のうち任意の整数を表し、b
i
は、バイアス項を表し、λは、ハイパーパラメータを表し、ε(z)は、エントロピー正則化項を表すものである。
【0010】
(5):この発明の別の態様に係る学習方法は、コンピュータが、データを入力として、前記データの少なくとも一部がある種別を表すクラスに該当するロジットを出力するように学習された第1機械学習モデルを学習し、前記第1機械学習モデルの出力を用いて、前記第1機械学習モデルの学習に用いた誤差関数を補正し、補正された前記誤差関数を用いて、前記第1機械学習モデルを再学習することによって、第2機械学習モデルを生成するものである。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
他の特許を見る
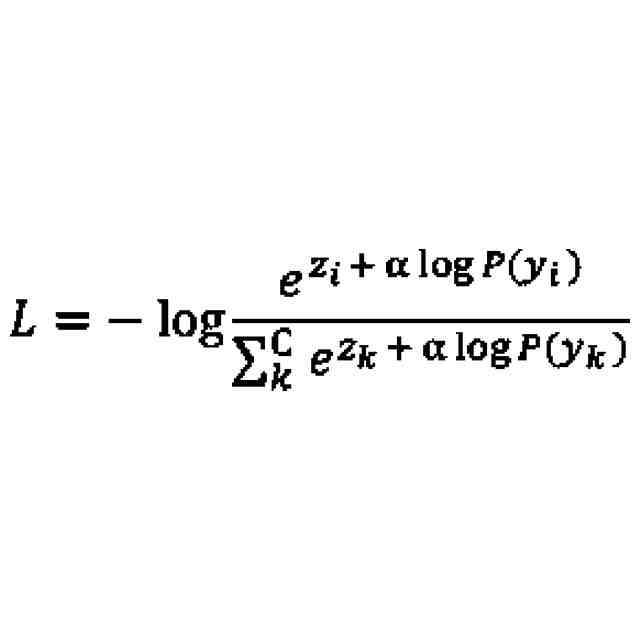
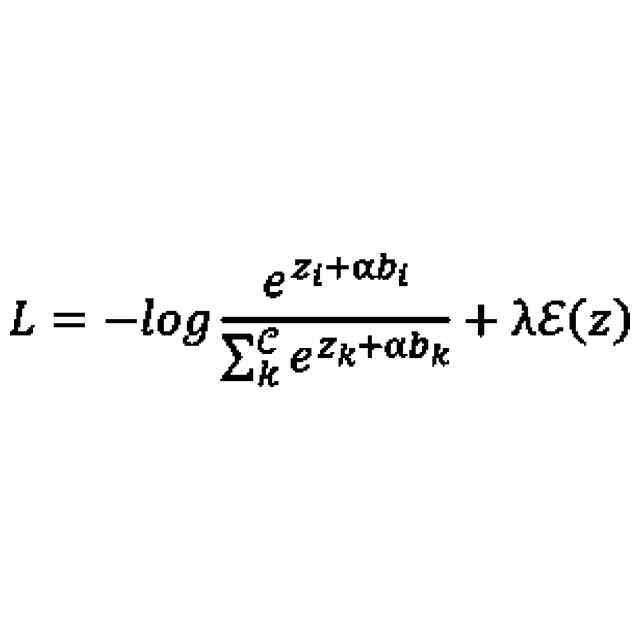

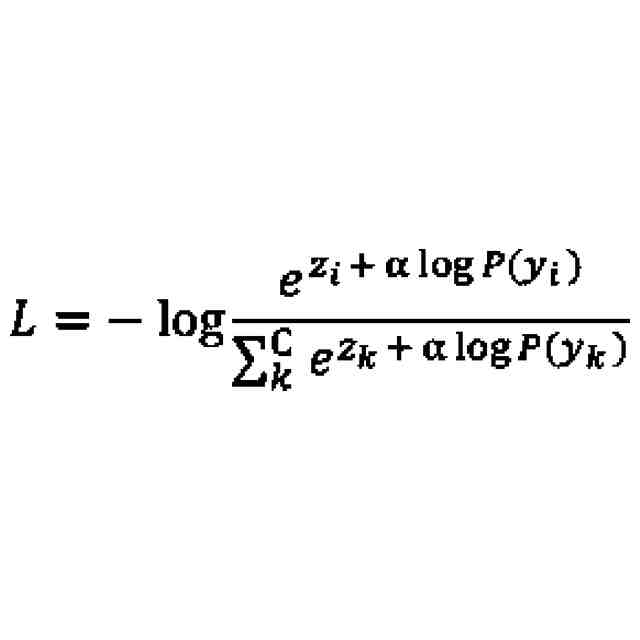
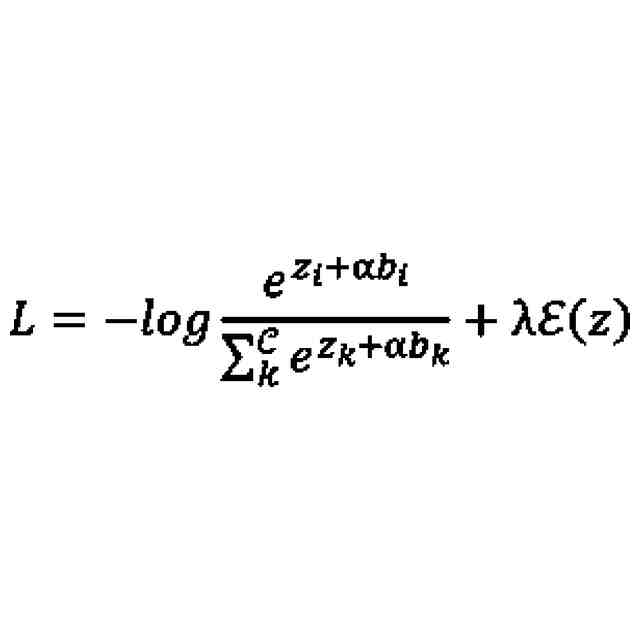
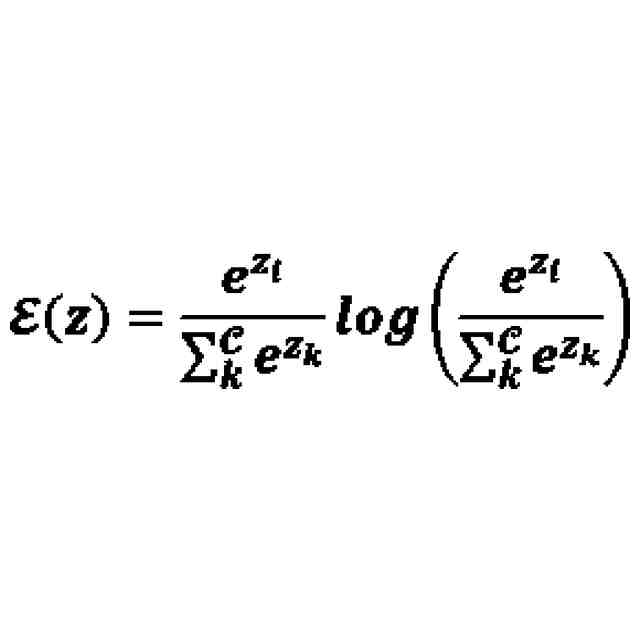
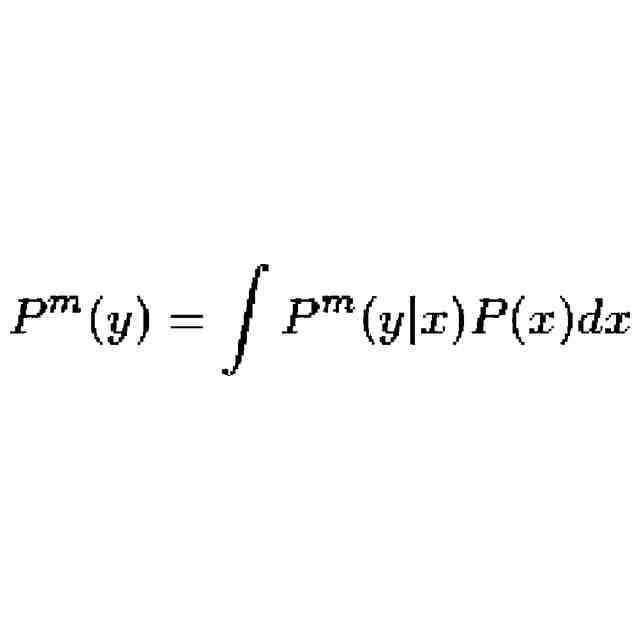
 特許ウォッチ
特許ウォッチ