TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025033006
公報種別
公開特許公報(A)
公開日
2025-03-12
出願番号
2024145936
出願日
2024-08-27
発明の名称
学習装置、学習方法、およびプログラム
出願人
本田技研工業株式会社
,
センスタイム グループ リミテッド
代理人
個人
,
個人
,
個人
主分類
G06T
7/00 20170101AFI20250305BHJP(計算;計数)
要約
【課題】画像に含まれる領域のうち、遠方領域から正確に道路領域を検出する機械学習モデルを生成すること。
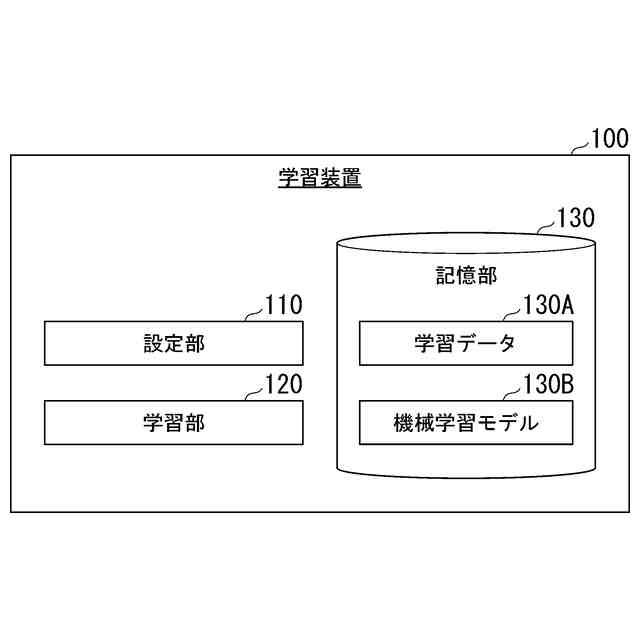
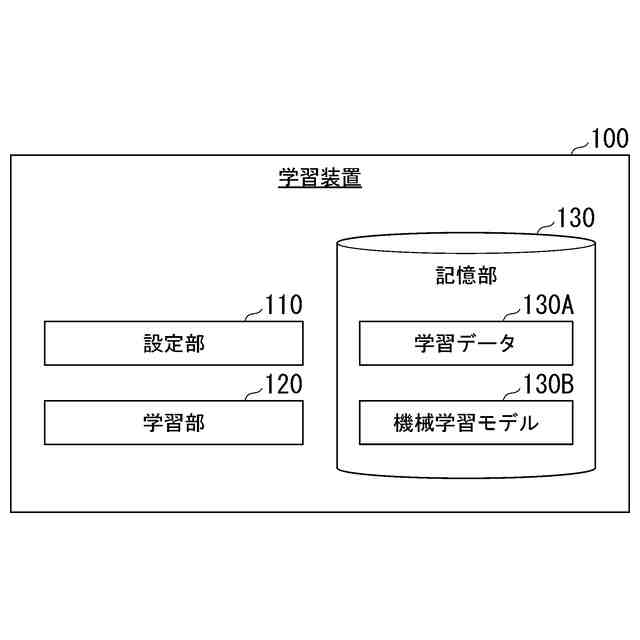
【解決手段】複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習する学習装置であって、前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定する設定部と、前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習する学習部と、を備え、前記設定部は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させる、学習装置。
【選択図】図1
特許請求の範囲
【請求項1】
複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習する学習装置であって、
前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定する設定部と、
前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習する学習部と、を備え、
前記設定部は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させる、
学習装置。
続きを表示(約 730 文字)
【請求項2】
前記設定部は、前記一以上の所定方向として、前記画像の下端中央から上端および左右端に向けて前記重みを増加させる、
請求項1に記載の学習装置。
【請求項3】
前記設定部は、前記一以上の所定方向として、前記画像の下端中央から上端に向けて前記重みを増加させる、
請求項1に記載の学習装置。
【請求項4】
複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習する学習方法であって、コンピュータが、
前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定し、
前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習し、
前記設定は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させる、
学習方法。
【請求項5】
複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習させるプログラムであって、コンピュータに、
前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定させ、
前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習させ、
前記設定は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させる、
プログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、学習装置、学習方法、およびプログラムに関する。
続きを表示(約 1,600 文字)
【背景技術】
【0002】
従来、車両の運転支援又は自動運転に活用するために、画像に含まれる道路領域を検出する技術が知られている。例えば、特許文献1には、入力された画像をx方向にスキャンして、エッジを抽出し、当該エッジ付近での色の違いに基づいて白線を検出することによって道路領域を検出する技術が開示されている。
【先行技術文献】
【特許文献】
【0003】
特開2020-038101号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
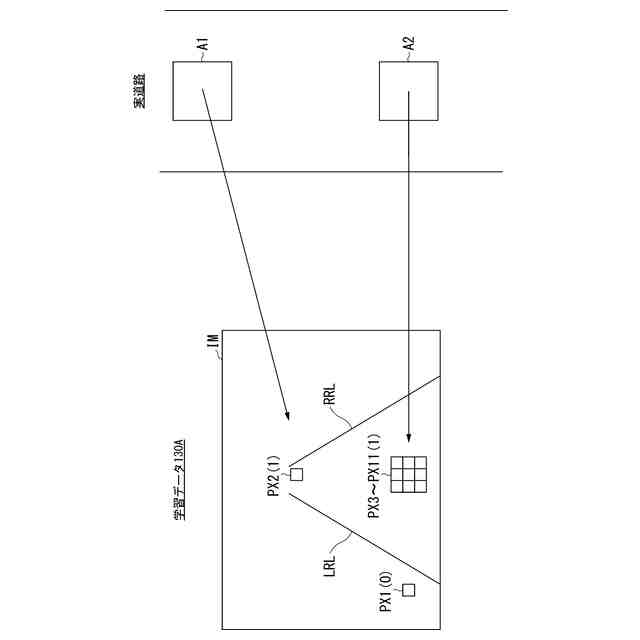
しかしながら、特許文献1に記載の技術では、画像に含まれる領域のうち、遠方であるほどピクセル数が減少することに起因して、スキャンの精度が低下することがあり得る。このように、従来技術では、画像に含まれる領域のうち、遠方領域から正確に道路領域を検出することができない場合があった。
【0005】
本発明は、このような事情を考慮してなされたものであり、画像に含まれる領域のうち、遠方領域から正確に道路領域を検出する機械学習モデルを生成することができる学習装置、学習方法、およびプログラムを提供することを目的の一つとする。
【課題を解決するための手段】
【0006】
この発明に係る学習装置、学習方法、およびプログラムは、以下の構成を採用した。
(1):この発明の一態様に係る学習装置は、複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習する学習装置であって、前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定する設定部と、前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習する学習部と、を備え、前記設定部は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させるものである。
【0007】
(2):上記(1)の態様において、前記設定部は、前記一以上の所定方向として、前記画像の下端中央から上端および左右端に向けて前記重みを増加させるものである。
【0008】
(3):この発明の別の態様に係る学習方法は、複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習する学習方法であって、コンピュータが、前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定し、前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習し、前記設定は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させるものである。
【0009】
(4):この発明の別の態様に係るプログラムは、複数のピクセルを含む画像を入力として、それぞれの前記ピクセルが道路を表すか否かを示す判別値を出力する機械学習モデルを学習させるプログラムであって、コンピュータに、前記機械学習モデルによって出力された判別値と、それぞれの前記ピクセルが道路を表すか否かを示す学習データとの間の誤差に対して重みを設定させ、前記重みが設定された前記誤差に基づいて算出された損失関数の値を低減するように前記機械学習モデルを学習させ、前記設定は、前記画像の下端中央から一以上の所定方向に向けて前記重みを増加させるものである。
【発明の効果】
【0010】
(1)~(4)によれば、画像に含まれる領域のうち、遠方領域から正確に道路領域を検出する機械学習モデルを生成することができる。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る


 特許ウォッチ
特許ウォッチ