TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025026831
公報種別
公開特許公報(A)
公開日
2025-02-26
出願番号
2024165835,2023558124
出願日
2024-09-25,2022-03-17
発明の名称
アーチファクトおよび歪みに対するディープラーニングベースの音声強調のためのロバスト性/性能改良
出願人
ドルビー ラボラトリーズ ライセンシング コーポレイション
代理人
弁理士法人ITOH
主分類
G10L
21/0208 20130101AFI20250218BHJP(楽器;音響)
要約
【課題】オーディオ信号を処理する方法並びに対応する装置、コンピュータプログラムおよびコンピュータ可読記憶媒体を提供する。
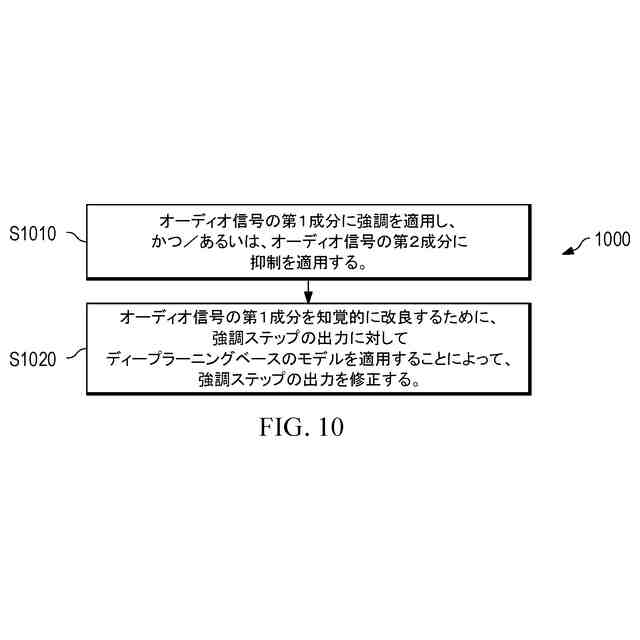
【解決手段】方法1000は、オーディオ信号の第1成分に強調を適用し、かつ/あるいは、第1成分に対してオーディオ信号の第2成分に抑制を適用するステップS1010と、出力にディープラーニングベースのモデルを適用することによってステップS1010の出力を修正しステップS1010によってオーディオ信号に導入されたアーチファクト及び/又は歪みを除去し、かつ、オーディオ信号の第1成分を知覚的に改良するステップS1020と、を含む。
【選択図】図10
特許請求の範囲
【請求項1】
オーディオ信号を処理する方法であって、
前記オーディオ信号の第1成分に強調を適用し、かつ/あるいは、前記第1成分に対して前記オーディオ信号の第2成分に抑制を適用する、第1ステップと、
前記オーディオ信号の前記第1成分を知覚的に改良するために、前記第1ステップの出力にディープラーニングベースのモデルを適用することによって、前記第1ステップの出力を修正する第2ステップと、
を含む、方法。
続きを表示(約 1,500 文字)
【請求項2】
前記第1ステップは、前記オーディオ信号に音声強調を適用するステップである、
請求項1に記載の方法。
【請求項3】
前記第1ステップの出力は、波形ドメインのオーディオ信号であり、前記第1成分が強調されており、かつ/あるいは、前記第1成分に対して前記第2成分が抑制されている、
請求項1または2に記載の方法。
【請求項4】
前記第1ステップの出力は、個々のビンまたは帯域について重み付け係数を示している変換ドメインのマスクであり、かつ、前記オーディオ信号に前記マスクを適用することは、前記第1成分の強調、及び/又は、前記第1成分に対して前記第2成分の抑制を結果として生じる、
請求項1または2に記載の方法。
【請求項5】
第2ステップは、前記第1ステップの出力に係る複数のインスタンスを受信し、
前記インスタンスそれぞれは、前記オーディオ信号に係る複数のフレームのそれぞれ1つに対応し、かつ、
前記第2ステップは、前記出力に係る複数のインスタンスに機械学習ベースのモデルを一緒に適用し、前記オーディオ信号に係る複数のフレームのうちの1つ以上において前記オーディオ信号の前記第1成分を知覚的に改良する、
請求項1乃至4いずれか一項に記載の方法。
【請求項6】
前記第2ステップは、前記オーディオ信号の所与のフレームについて、前記第1ステップの出力のインスタンスのシーケンスを受信し、
前記インスタンスそれぞれは、前記オーディオ信号のフレームのシーケンス内のそれぞれ1つに対応しており、
前記フレームのシーケンスは、前記所与のフレームを含み、かつ、
前記第2ステップは、前記所与のフレームにおける前記オーディオ信号の前記第1成分を知覚的に改良するために、前記出力のインスタンスのシーケンスに前記機械学習ベースのモデルを一緒に適用する、
請求項5に記載の方法。
【請求項7】
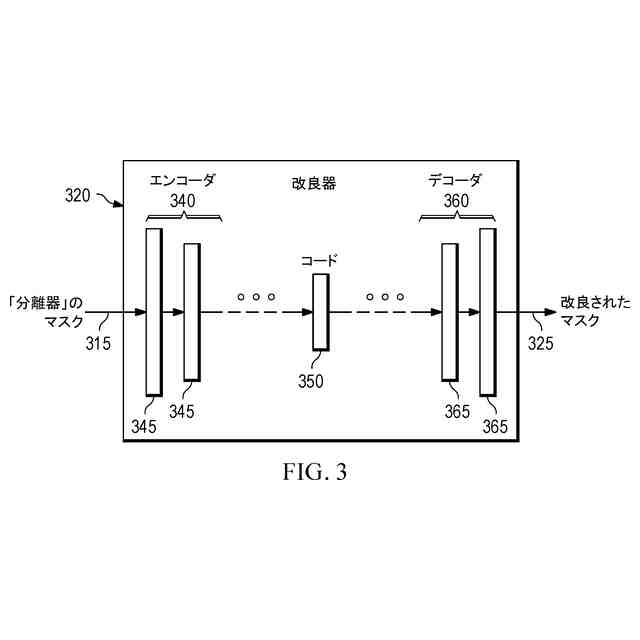
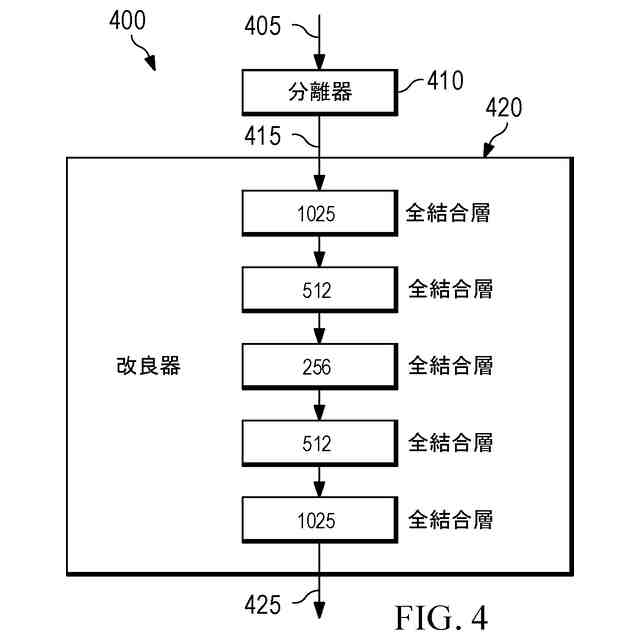
前記第2ステップの前記ディープラーニングベースのモデルは、エンコーダステージおよびデコーダステージを有する自動エンコーダアーキテクチャを実装し、
各ステージは、それぞれの複数の連続したフィルタ層を備え、
前記エンコーダステージは、前記エンコーダステージへの入力を、潜在空間表現にマッピングし、かつ、
前記デコーダステージは、前記エンコーダステージによって出力された前記潜在空間表現を、前記エンコーダステージへの前記入力と同じフォーマットを有する前記デコーダステージの出力にマッピングする、
請求項1乃至6いずれか一項に記載の方法。
【請求項8】
前記第2ステップの前記ディープラーニングベースのモデルは、複数の連続した層を有するリカレントニューラルネットワークアーキテクチャを実装し、
前記複数の層は、長短期記憶タイプ、または、ゲート付き再帰ユニットタイプの層である、
請求項1乃至6いずれか一項に記載の方法。
【請求項9】
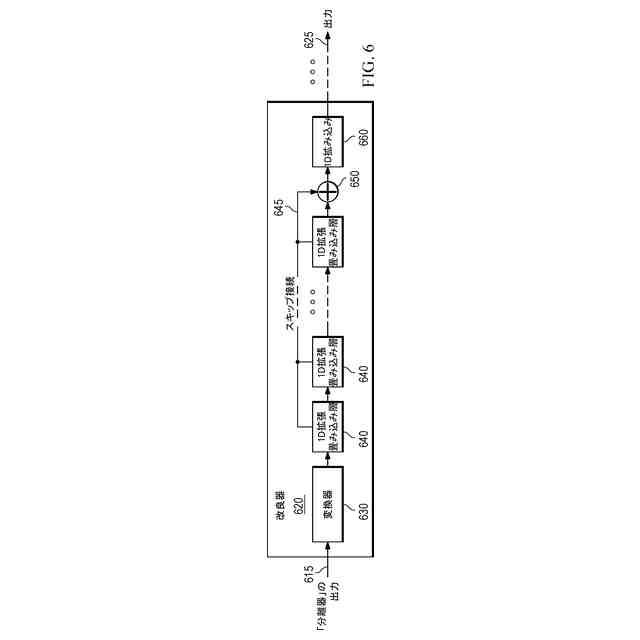
前記ディープラーニングベースのモデルは、複数の連続した畳み込み層を有する生成モデルアーキテクチャを実装する、
請求項1乃至6いずれか一項に記載の方法。
【請求項10】
前記畳み込み層は、拡張畳み込み層であり、任意的に、スキップ接続を含んでいる、
請求項9に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本開示は、オーディオ処理の分野に関する。特に、本開示は、ディープラーニング(deep-learning)モデルまたはシステムを使用するオーディオ強調(例えば、音声強調(audio enhancement))のための技法に関し、そして、オーディオ強調についてディープラーニングモデルまたはシステムをトレーニングするためのフレームワークに関する。
続きを表示(約 2,500 文字)
【0002】
関連出願の相互参照
本出願は、2021年3月22日に出願された国際出願PCT/CN2021/082199、2021年6月8日に出願された欧州特許出願第21178178.6号、および、2021年4月28日に出願された米国仮特許出願第63/180,705号について優先権を主張するものであり、これらの出願それぞれは、参照により、その全体が本明細書に組み込まれている。
【背景技術】
【0003】
音声強調は、雑音の多い混合信号(noisy mixture signal)から音声信号(音声成分(speech component))を強調または分離することを目的とする。多数の音声強調手法が、過去数十年にわたり開発されてきた。近年、音声強調は、教師あり学習タスク(supervised learning task)として定式化されており、ここでは、クリーンな音声およびバックグラウンドノイズの識別パターンがトレーニングデータから学習される。しかしながら、これらのアルゴリズムは、異なる音響環境(acoustic environment)を取り扱うときに、全てが、異なる処理歪み(processing distortion)にわずらわされる。典型的な処理歪みは、ターゲット損失、干渉、および、アルゴリズムアーチファクトを含んでいる。
【0004】
従って、アーチファクト及び/又は歪みを低減することができる、音声強調を含む、オーディオ処理に係る改良されたディープラーニングベースの方法に対する必要性が存在している。
【発明の概要】
【0005】
上記に鑑みて、本開示は、オーディオ信号を処理する方法、並びに、対応する装置、コンピュータプログラム、および、コンピュータ可読記憶媒体を提供し、それぞれの請求項が特徴を有している。
【0006】
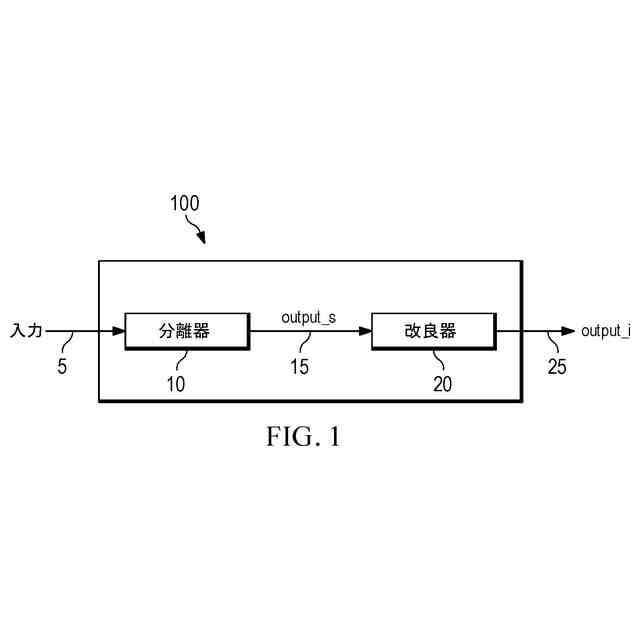
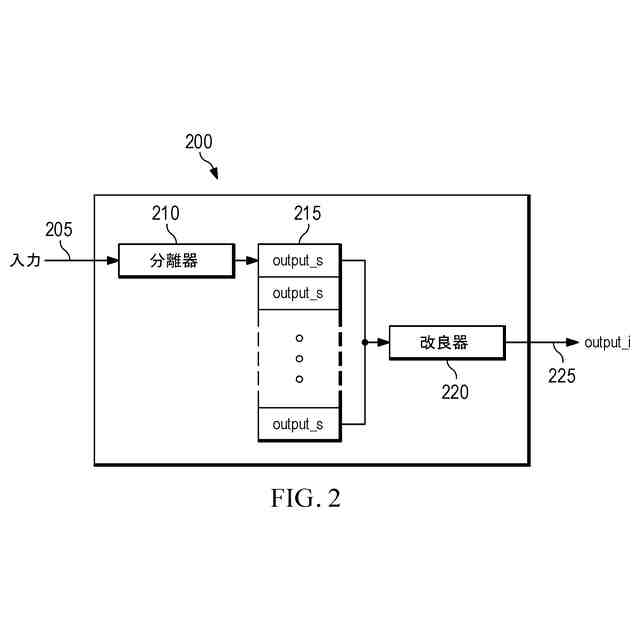
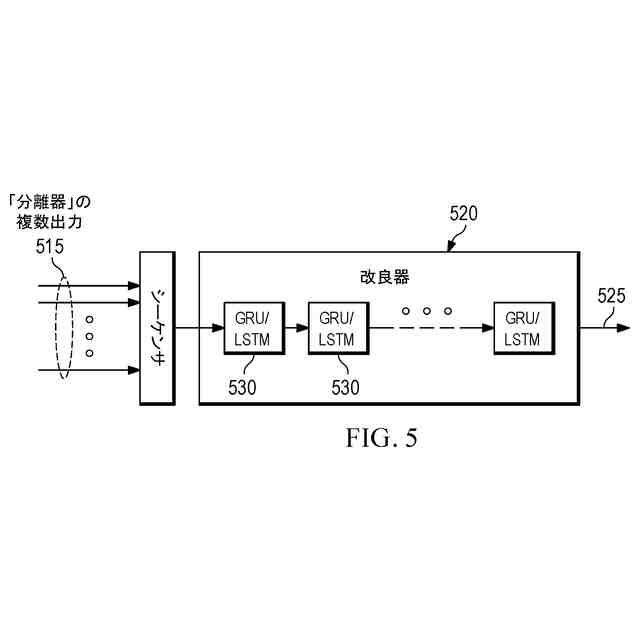
本開示の一態様に従って、オーディオ信号を処理する方法が提供される。本方法は、前記オーディオ信号の第1成分に強調を適用し、かつ/あるいは、前記第1成分に対して前記オーディオ信号の第2成分に抑制を適用する、第1ステップを含み得る。第1ステップは、オーディオ信号の任意の残差成分から第1成分を少なくとも部分的に分離するか、または、そうするためのマスクを生成する、強調ステップまたは分離ステップであってよい。かくして、第1ステップは、また、ノイズ除去動作を実行すると言うこともできる。第1成分の強調は、第2成分に対するものであり得る。第1成分は、例えば、音声(音声成分)であり得る。第2成分は、例えば、ノイズ(雑音成分)であってよく、バックグラウンド(背景成分)であり得る。本方法は、さらに、前記第1ステップの出力にディープラーニングベースのモデルを適用することによって、前記第1ステップの出力を修正する第2ステップを含み得る。第2ステップは、前記第1ステップによって前記オーディオ信号に導入されたアーチファクト及び/又は歪みを除去し、かつ、前記オーディオ信号の前記第1成分を知覚的に改良する。第2ステップは、修正ステップであってよく、または、改良ステップであってもよい。それは、第1ステップによって導入される歪み及び/又はアーチファクトの除去をもたらし得る。第2ステップは、第1ステップの出力に応じて、強調された第1成分及び/又は抑制された第2成分を有する波形信号に対して動作してよく、または、マスクに対して動作し得る。
【0007】
上記で説明されるように構成されて、提案される方法は、音声強調ステップ(例えば、ディープラーニングベースの音声強調ステップ)といった、オーディオ処理ステップによって導入される、アーチファクトおよび歪みを除去することができる。これは、手近なオーディオ処理から生じるアーチファクトおよび歪みを除去するように、特定的にトレーニングすることができる、ディープラーニングベースのモデルによって達成される。
【0008】
いくつかの実施形態において、前記第1ステップは、前記オーディオ信号に音声強調を適用するステップであり得る。従って、第1成分は音声成分に対応することができ、そして、第2成分は、ノイズ、バックグラウンド、または残差成分に対応することができる。
【0009】
いくつかの実施形態において、第1ステップの出力は、波形ドメインのオーディオ信号(例えば、波形信号)であり、そこでは、前記第1成分が強調され、かつ/あるいは、前記第1成分に対して前記第2成分が抑制されている。かくして、第1ステップは、時間ドメイン(波形ドメイン)オーディオ信号を受信し、時間ドメインオーディオ信号を(直接)修正することによって、第1成分の強調及び/又は第2成分の抑制を適用することができる。
【0010】
いくつかの実施形態において、前記第1ステップの出力は、個々のビンまたは帯域について重み付け係数を示している変換ドメインのマスクであり得る。変換ドメイン(変換された領域)は、例えば、周波数ドメインまたはスペクトルドメインであり得る。(変換ドメイン)ビンは、時間-周波数ビンであってよい。マスクは、例えば、振幅マスク、位相感応マスク、複素マスク、バイナリマスク、等であってよい。さらに、(変換ドメイン)オーディオ信号に前記マスクを適用することは、前記第1成分の強調、及び/又は、前記第1成分に対して前記第2成分の抑制を結果として生じ得る。具体的には、第1成分の強調及び/又は第2成分の抑制は、ノイズまたはバックグラウンドに関連する時間周波数タイルを除去または抑制することによって、変換ドメインオーディオ信号にマスクを適用することにより達成され得る。本方法は、オーディオ信号を変換ドメインに変換する(初期)ステップ、及び/又は、逆変換を実施する(最終)ステップを任意的に含み得ることが理解される。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
アクセサリー型集音器
今日
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
水中音響材
10日前
大和ハウス工業株式会社
音再現設備
14日前
日産自動車株式会社
防音構造体
28日前
岡山県
吸音構造
7日前
セイコーエプソン株式会社
吸音ボード
28日前
株式会社第一興商
カラオケ装置
14日前
株式会社第一興商
カラオケ装置
6日前
コスモネクスト株式会社
入力支援プログラム及び入力支援方法
21日前
京セラ株式会社
音出力装置及び音出力方法
28日前
本田技研工業株式会社
能動型騒音低減装置
28日前
本田技研工業株式会社
能動型騒音低減装置
6日前
本田技研工業株式会社
能動型騒音低減装置
6日前
個人
発音体モジュール
1日前
日本放送協会
音声認識装置およびプログラム
28日前
カシオ計算機株式会社
楽器用電子機器
6日前
株式会社コルグ
音波生成装置、音波生成方法、プログラム
21日前
株式会社永セ仁
「パワハラ」等ハラスメント発言に係る職場環境測定システム
10日前
ソフトバンクグループ株式会社
行動制御システム
21日前
株式会社AZSTOKE
調整装置、およびプログラム
6日前
本田技研工業株式会社
音声認識装置、音声認識方法、およびプログラム
13日前
永楽電気株式会社
放送音声文字化システム及び放送設備における故障診断方法
28日前
パイオニア株式会社
情報処理装置
15日前
東日本電信電話株式会社
演奏補助装置、演奏補助方法、及び、演奏補助プログラム
13日前
ヤマハ株式会社
響板、その製造方法および響板を備える楽器
13日前
ドーナッツロボティクス株式会社
音声処理システム、音声処理方法
21日前
ヤマハ株式会社
信号生成方法、表示制御方法およびプログラム
7日前
株式会社イノアックコーポレーション
防音カバー
6日前
株式会社イノアックコーポレーション
防音カバー
6日前
三菱重工業株式会社
サイレンサ
1か月前
ソフトバンクグループ株式会社
データ処理装置、データ処理方法、及びプログラム
28日前
カシオ計算機株式会社
情報処理装置、情報処理方法及びプログラム
15日前
カシオ計算機株式会社
楽音制御システム
13日前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ