TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025026801
公報種別
公開特許公報(A)
公開日
2025-02-25
出願番号
2024129043
出願日
2024-08-05
発明の名称
向上した信頼度を有する音響認識結果提供方法、装置およびコンピュータプログラム
出願人
コーチル インク
,
COCHL INC.
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
15/32 20130101AFI20250217BHJP(楽器;音響)
要約
【課題】音響データを時間単位の区間に分割して、各区間に対する認識を遂行する過程で計算量を減らしながらも認識率の向上を図り、多様な周辺状況に対応して向上した正確度を有する音響認識結果提供方法、装置及びコンピュータプログラムを提供する。
【解決手段】携帯性と移動性が保障される無線通信装置である使用者端末と、外部サーバーが、それぞれネットワークを通じて音響データの認識正確度を向上させるためのサーバーと連結されるシステムにおいて、サーバーが実施する方法は、人工知能モデルを活用して、音響データを獲得する段階、音響データを分割して複数個の音響サブデータを生成する段階及び複数個の音響サブデータを音響認識モデルの入力として処理して各音響サブデータに対応する音響認識結果情報を生成する段階を含む。
【選択図】図3
特許請求の範囲
【請求項1】
コンピューティング装置の一つ以上のプロセッサで遂行される方法において、
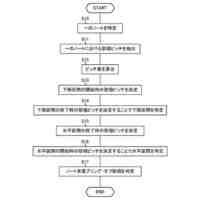
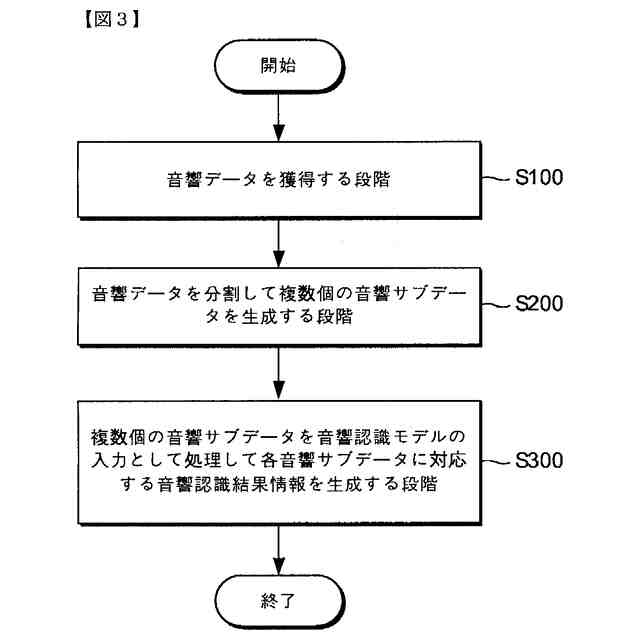
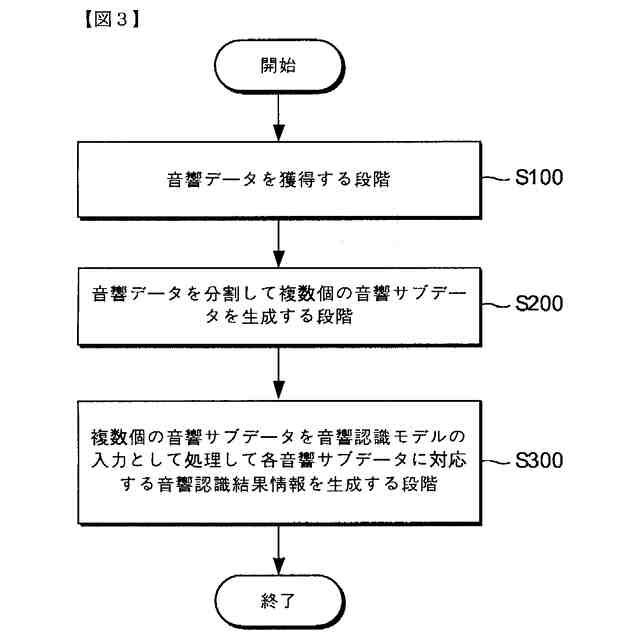
音響データを獲得する段階;
音響データを分割して複数個の音響サブデータを生成する段階;および
前記複数個の音響サブデータを音響認識モデルの入力として処理して各音響サブデータに対応する音響認識結果情報を生成する段階;を含む、向上した信頼度を有する音響認識結果提供方法。
続きを表示(約 2,400 文字)
【請求項2】
前記複数個の音響サブデータを生成する段階は、
前記音響データを予め設定された大きさ単位で分割して複数個の音響サブデータを生成する段階;を含み、
前記音響認識モデルは、
前記複数個の音響サブデータそれぞれを入力として各音響サブデータに対応する複数個の出力を提供する第1認識モデルおよび前記複数個の音響サブデータ間の組み合わせを通じて生成された組み合わせ再検証音響サブデータを入力として、組み合わせ再検証音響サブデータに対応する出力を提供する第2認識モデルを含む、請求項1に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項3】
前記音響認識結果情報を生成する段階は、
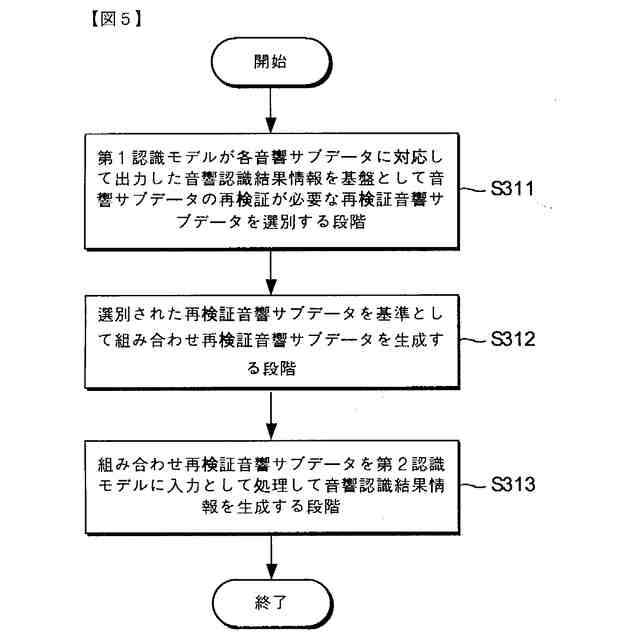
前記第1認識モデルが前記各音響サブデータに対応して出力した音響認識結果情報に基づいて音響サブデータの再検証が必要な再検証音響サブデータを選別する段階;
前記選別された再検証音響サブデータを基準として組み合わせ再検証音響サブデータを生成する段階;および
前記組み合わせ再検証音響サブデータを前記第2認識モデルに入力として処理して音響認識結果情報を生成する段階;を含み、
前記第2認識モデルは、
クラウドAPIを通じて具現されることを特徴とする、請求項2に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項4】
前記再検証音響サブデータを選別する段階は、
前記第1認識モデルの出力に関連した認識項目間の類似度点数を導き出す段階;および
算出された前記類似度点数に基づいて再検証音響サブデータを選別する段階;を含む、請求項3に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項5】
前記再検証音響サブデータを選別する段階は、
前記第1認識モデルの出力に関連した音響認識結果情報が予め設定された再検証項目内に含まれるかどうかを識別する段階;および
前記音響認識結果情報が前記再検証項目内に含まれる場合、前記音響認識結果情報算出に基盤となる音響サブデータを再検証が必要な再検証音響サブデータとして選別する段階;を含む、請求項3に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項6】
前記第1認識モデルは、
各認識項目別確率値を出力し、算出された確率値のうち最大値に該当する確率値に対応する認識項目に基づいて音響認識結果情報を生成することを特徴とし、
前記再検証音響サブデータを選別する段階は、
前記第1認識モデルを通じて算出された各認識項目別確率値のうち予め設定された臨界基準値を超過する認識項目が複数個である場合、前記音響認識結果情報算出に基盤となる音響サブデータを再検証が必要な再検証音響サブデータとして選別する段階;を含む、請求項3に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項7】
前記音響認識結果情報を生成する段階は、
前記音響認識結果情報間の連関関係情報を生成する段階;および
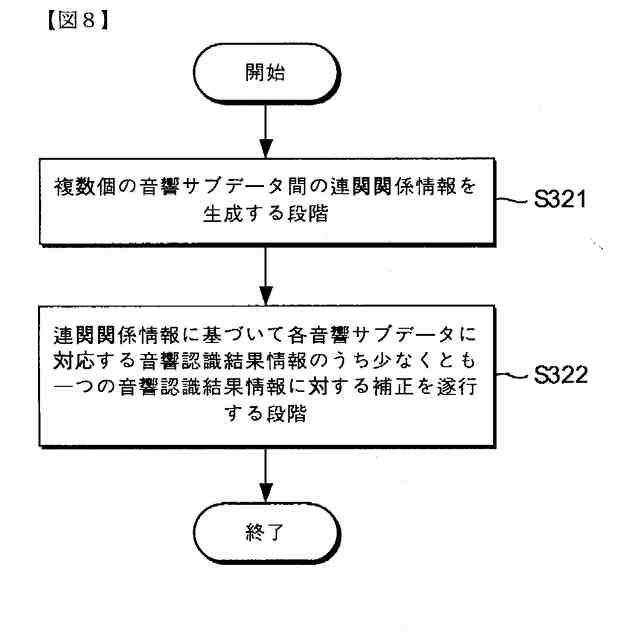
前記連関関係情報に基づいて各音響サブデータに対応する前記音響認識結果情報のうち少なくとも一つの音響認識結果情報に対する補正を遂行する段階;を含む、請求項1に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項8】
前記少なくとも一つの音響認識結果情報に対する補正を遂行する段階は、
第1音響認識結果情報と第2音響認識結果情報が予め設定された時間以内に生成された場合、前記第1音響認識結果と前記第2音響認識結果情報に対応する連関関係情報に基づいて第1音響認識結果および第2音響認識結果のうち少なくとも一つに対する補正を遂行することを特徴とする、請求項7に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項9】
前記方法は、
ムード感知モデルを活用して前記音響認識結果情報に対応するムード情報を生成する段階;をさらに含み、
前記ムード情報は、
音響データが獲得される空間に関連した雰囲気に対する予測情報であって、場所予測情報および感情予測情報を含み、
前記音響認識結果情報を生成する段階は、
第1音響サブデータに対応する第1音響認識結果情報と前記第1音響サブデータに対応する前記ムード情報間の関連性情報を生成する段階;
前記関連性情報が予め設定された基準値以上である場合、前記第1音響認識結果情報に対する補正を遂行しない段階;および
前記関連性情報が予め設定された基準値未満である場合、前記第1音響認識結果情報に対する補正を遂行する段階;を含み、
前記ムード感知モデルは、
前記音響認識結果情報を認識して時点別周辺状況に対応する前記ムード情報を出力するように学習されたニューラルネットワークモデルであることを特徴とする、請求項1に記載の向上した信頼度を有する音響認識結果提供方法。
【請求項10】
前記第1音響認識結果情報に対する補正を遂行する段階は、
前記第1音響認識結果と類似性を有する複数のキーワードを識別する段階;
前記複数のキーワードそれぞれと前記ムード情報間の複数の関連性サブ情報を生成する段階;および
前記複数の関連性サブ情報のうち最大値に該当する最大関連性サブ情報を識別し、最大関連性サブ情報に対応するキーワードに基づいて前記第1音響認識結果情報に対する補正を遂行する段階;を含む、請求項9に記載の向上した信頼度を有する音響認識結果提供方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は音響データの認識率を向上させるための方法に関し、より具体的には、音響データを時間単位の区間に分割して、各区間に対する認識を遂行する過程で計算量を減らしながらも認識率の向上を図り、多様な周辺状況に対応して向上した正確度を有する音響認識結果を提供するための方法に関する。
続きを表示(約 7,300 文字)
【背景技術】
【0002】
完全に音を聞くことができないかまたは音をよく区別できない聴覚障害者は音を聞いて状況を判断することが難しいため日常生活に多くの困難があるだけでなく、音情報を利用して室内、室外環境での急迫した状況を認知することができないため即時に対処が不可能である。聴覚障害者だけでなく、イヤホン着用歩行者、高齢者などの聴覚がないか制限された状況では使用者周辺で発生する音響が遮断され得る。追加的に、使用者が睡眠をとるなど音響を感知し難い状況では周辺状況を認知することができず急迫した状況に置かれたり、事故に遭う恐れがある。
一方、このような環境の中で音響イベントを検出し認識する技術開発に対する必要性が台頭している。音響イベントを検出し認識する技術は、実生活環境のコンテクスト認識、急迫した状況認識、メディアコンテンツ認識、有線通信上の状況分析など多様な分野に応用可能な技術であって、持続的に研究されている。
音響イベント認識技術としては、オーディオ信号からMFCC、energy、spectral flux、zero crossing rateなど多様な特徴値を抽出して優秀な特徴を検証する研究とGaussian mixture modelまたはrule基盤の分類方法などに対する研究が主をなしており、最近では前記方法を改善するために、ディープラーニング基盤の機械学習方法が研究されている。しかし、このような方法は低い信号対比雑音比で音響検出の正確度が保障され、周辺の雑音と事件の音響を区別し難いという限界点を有する。
【0003】
すなわち、多様な周辺ノイズを含む実生活環境では信頼度の高い音響イベントの検出が困難であり得る。具体的には、有効な音響イベントを検出するためには、時系列的(すなわち、連続的)に獲得される音響データに対して音響イベントが発生したか否かを判断しなければならず、これと共にどのようなイベントクラスが発生したのかも認識しなければならないため、高い信頼度を担保することが困難であり得る。また、二以上のイベントが同時に発生する場合、単一イベント(monophonic)ではなく多重イベント(polyphonic)認識問題まで解決しなければならないため、音響イベントの認識率がさらに低くなり得る。
したがって、実生活環境で時系列的に獲得される音響データに対応して認識率を高めて、向上した信頼度を有する音響認識を提供しようとする需要が存在し得る。
大韓民国登録特許10-2014-0143069
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明が解決しようとする課題は、前述した問題点を解決するためのものであって、音響データを時間単位の区間に分割して各区間に対する認識を遂行する過程で計算量を減らしながらも認識率の向上を図り、多様な周辺状況に対応して向上した正確度を有する音響認識結果を提供するためのものである。
本発明が解決しようとする課題は、以上で言及された課題に制限されず、言及されていないさらに他の課題は下記の記載から通常の技術者に明確に理解され得るであろう。
【課題を解決するための手段】
【0005】
前述した課題を解決するための本発明の多様な実施例に係る向上した信頼度を有する音響認識結果提供方法が開示される。前記方法は、音響データを獲得する段階、音響データを分割して複数個の音響サブデータを生成する段階および前記複数個の音響サブデータを音響認識モデルの入力として処理して各音響サブデータに対応する音響認識結果情報を生成する段階を含むことができる。
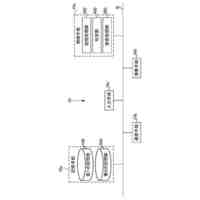
代案的な実施例で、前記複数個の音響サブデータを生成する段階は、前記音響データを予め設定された大きさ単位で分割して複数個の音響サブデータを生成する段階を含み、前記音響認識モデルは、前記複数個の音響サブデータそれぞれを入力として各音響サブデータに対応する複数個の出力を提供する第1認識モデルおよび前記複数個の音響サブデータ間の組み合わせを通じて生成された組み合わせ再検証音響サブデータを入力として、組み合わせ再検証音響サブデータに対応する出力を提供する第2認識モデルを含むことができる。
代案的な実施例で、前記音響認識結果情報を生成する段階は、前記第1認識モデルが前記各音響サブデータに対応して出力した音響認識結果情報に基づいて音響サブデータの再検証が必要な再検証音響サブデータを選別する段階、前記選別された再検証音響サブデータを基準として組み合わせ再検証音響サブデータを生成する段階および前記組み合わせ再検証音響サブデータを前記第2認識モデルに入力として処理して音響認識結果情報を生成する段階を含み、前記第2認識モデルは、クラウドAPIを通じて具現されることを特徴とすることができる。
代案的な実施例で、前記再検証音響サブデータを選別する段階は、前記第1認識モデルの出力に関連した認識項目間の類似度点数を導き出す段階および算出された前記類似度点数に基づいて再検証音響サブデータを選別する段階を含むことができる。
代案的な実施例で、前記再検証音響サブデータを選別する段階は、前記第1認識モデルの出力に関連した音響認識結果情報が予め設定された再検証項目内に含まれるかどうかを識別する段階および前記音響認識結果情報が前記再検証項目内に含まれる場合、前記音響認識結果情報算出に基盤となる音響サブデータを再検証が必要な再検証音響サブデータとして選別する段階を含むことができる。
代案的な実施例で、前記第1認識モデルは、各認識項目別確率値を出力し、算出された確率値のうち最大値に該当する確率値に対応する認識項目に基づいて音響認識結果情報を生成することを特徴とし、前記再検証音響サブデータを選別する段階は、前記第1認識モデルを通じて算出された各認識項目別確率値のうち予め設定された臨界基準値を超過する認識項目が複数個である場合、前記音響認識結果情報算出に基盤となる音響サブデータを再検証が必要な再検証音響サブデータとして選別する段階を含むことができる。
代案的な実施例で、前記音響認識結果情報を生成する段階は、音響認識結果情報間の連関関係情報を生成する段階および前記連関関係情報に基づいて各音響サブデータに対応する前記音響認識結果情報のうち少なくとも一つの音響認識結果情報に対する補正を遂行する段階;を含むことができる。
代案的な実施例で、前記少なくとも一つの音響認識結果情報に対する補正を遂行する段階は、第1音響認識結果情報と第2音響認識結果情報が予め設定された時間以内に生成された場合、前記第1音響認識結果と前記第2音響認識結果情報に対応する連関関係情報に基づいて第1音響認識結果および第2音響認識結果のうち少なくとも一つに対する補正を遂行することを特徴とすることができる。
代案的な実施例で、前記方法は、ムード感知モデルを活用して前記音響認識結果情報に対応するムード情報を生成する段階をさらに含み、前記ムード情報は音響データが獲得される空間に関連した雰囲気に対する予測情報であって、場所予測情報および感情予測情報を含み、前記音響認識結果情報を生成する段階は、第1音響サブデータに対応する第1音響認識結果情報と前記第1音響サブデータに対応する前記ムード情報間の関連性情報を生成する段階、前記関連性情報が予め設定された基準値以上である場合、前記第1音響認識結果情報に対する補正を遂行しない段階および前記関連性情報が予め設定された基準値未満である場合、前記第1音響認識結果情報に対する補正を遂行する段階を含み、前記ムード感知モデルは、前記音響認識結果情報を認識して時点別周辺状況に対応する前記ムード情報を出力するように学習されたニューラルネットワークモデルであることを特徴とすることができる。
【0006】
本発明の他の実施例によると、向上した信頼度を有する音響認識結果提供装置が開示される。前記装置は、一つ以上のインストラクションを保存するメモリおよび前記メモリに保存された前記一つ以上のインストラクションを実行するプロセッサを含み、前記プロセッサは前記一つ以上のインストラクションを実行することによって、前述した向上した信頼度を有する音響認識結果提供方法を遂行できる。
本発明のさらに他の実施例によると、コンピュータで読み取り可能な記録媒体に保存されたコンピュータプログラムが開示される。前記コンピュータプログラムはハードウェアであるコンピュータと結合されて、前述した向上した信頼度を有する音響認識結果提供方法を遂行できる。
本発明のその他の具体的な事項は詳細な説明および図面に含まれている。
【発明の効果】
【0007】
本発明の多様な実施例により、音響データを時間単位の区間に分割して、各区間に対する認識を遂行する過程で計算量を減らしながらも認識率の向上を図り、多様な周辺状況に対応して向上した正確度を有する音響認識結果を提供することができる。
本発明の効果は以上で言及された効果に制限されず、言及されていないさらに他の効果は下記の記載から通常の技術者に明確に理解され得るであろう。
【図面の簡単な説明】
【0008】
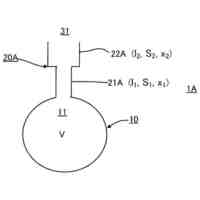
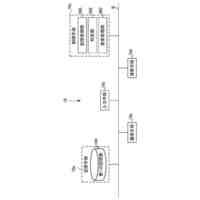
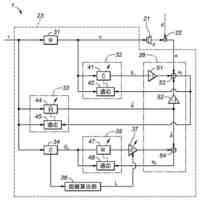
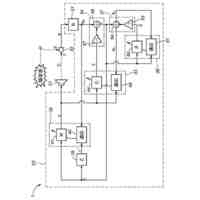
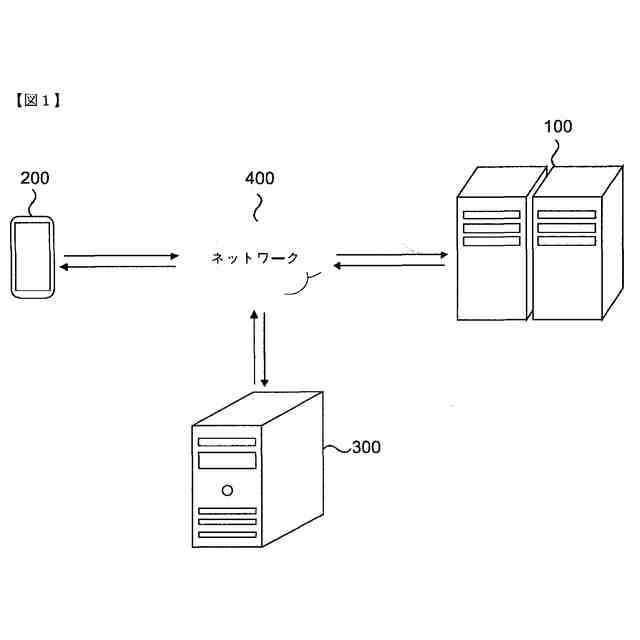
本発明の一実施例に係る向上した信頼度を有する音響認識結果提供方法を遂行するためのシステムを概略的に示した図面である。
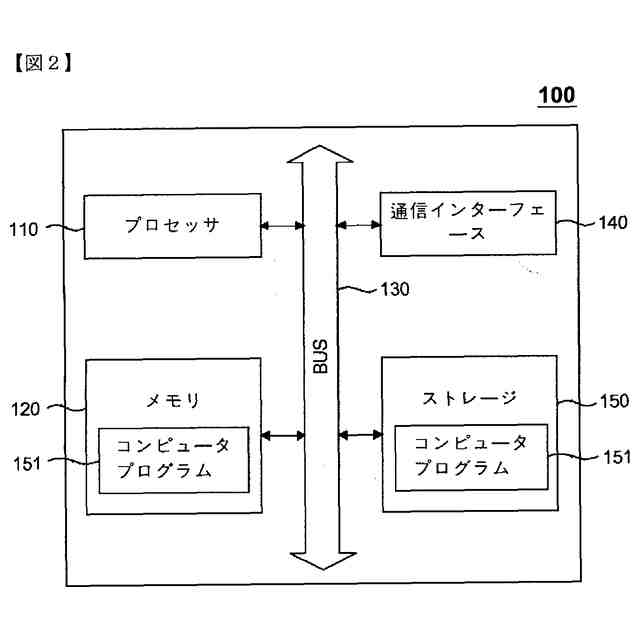
本発明の一実施例に関連した向上した信頼度を有する音響認識結果提供方法を遂行するサーバーのハードウェア構成図である。
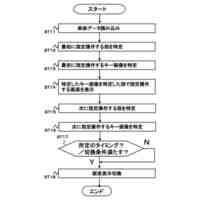
本発明の一実施例に関連した向上した信頼度を有する音響認識結果提供方法を例示的に示したフローチャートを図示する。
本発明の一実施例に関連した音響データの分割過程を説明するための例示図である。
本発明の一実施例に関連した音響データの分割過程を説明するための例示図である。
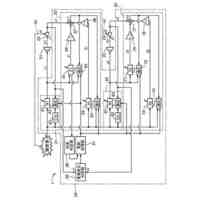
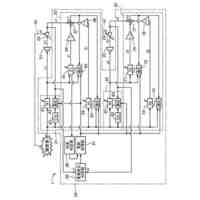
本発明の一実施例に関連した複数の人工知能モデルを活用した再検証を通じて音響認識結果情報を生成する過程を例示的に示したフローチャートである。
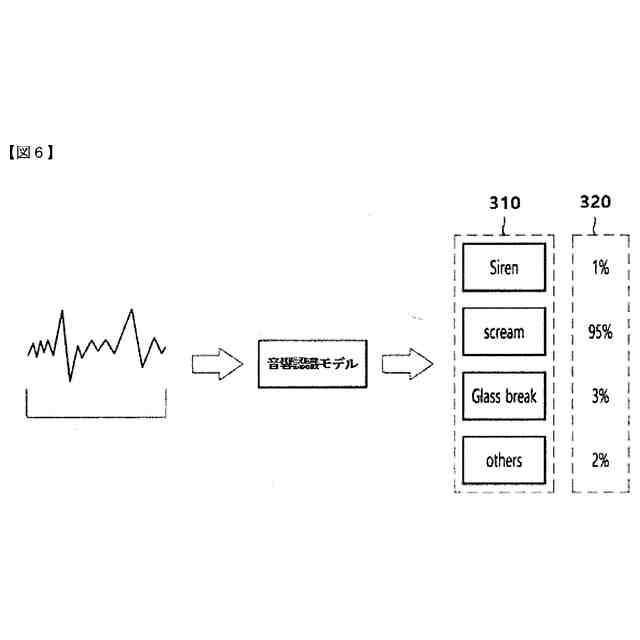
本発明の一実施例に関連した音響認識モデルが音響認識結果を導き出す過程を例示的に示した例示図である。
本発明の一実施例に関連した第1認識モデルおよび第2認識モデルを活用して音響データを認識する過程に関する例示図である。
本発明の一実施例に関連した音響サブデータ間の連関関係により音響認識結果情報に対する補正を遂行する過程を例示的に示したフローチャートである。
本発明の一実施例に関連した音響認識結果情報を補正する過程を説明するための例示図である。
本発明の一実施例に関連した音響認識結果情報を補正する過程を説明するための例示図である。
本発明の一実施例に関連した周辺環境および雰囲気を考慮して音響認識結果情報を生成する過程を例示的に示したフローチャートである。
本発明の一実施例に関連した一般的な認識過程を通じて導き出される音響認識結果情報の限界点を説明するための例示図である。
本発明の一実施例に関連した特定音響サブデータの前、後時点で対応する音響サブデータを通じて全般的な雰囲気を把握し、把握された雰囲気を考慮してより向上した正確度の音響認識結果情報を出力する過程を例示的に示した例示図である。
【発明を実施するための形態】
【0009】
多様な実施例が図面を参照して説明される。本明細書で、多様な説明が本発明の理解を提供するために提示される。しかし、このような実施例はこのような具体的な説明がなくても実行され得ることが明白である。
本明細書で使われる用語「コンポーネント」、「モジュール」、「システム」等はコンピュータ-関連エンティティ、ハードウェア、ファームウェア、ソフトウェア、ソフトウェアおよびハードウェアの組み合わせ、またはソフトウェアの実行を指し示す。例えば、コンポーネントはプロセッサ上で実行される処理過程(procedure)、プロセッサ、客体、実行スレッド、プログラム、および/またはコンピュータであり得るが、これらに制限されるものではない。例えば、コンピューティング装置で実行されるアプリケーションおよびコンピューティング装置がすべてコンポーネントであり得る。一つ以上のコンポーネントはプロセッサおよび/または実行スレッド内に常駐することができる。一コンポーネントは一つのコンピュータ内にローカル化され得る。一コンポーネントは2個以上のコンピュータの間に分配され得る。また、このようなコンポーネントはその内部に保存された多様なデータ構造を有する多様なコンピュータ読み取り可能な媒体から実行することができる。コンポーネントは例えば一つ以上のデータパケットを有する信号(例えば、ローカルシステム、分散システムで他のコンポーネントと相互作用する一つのコンポーネントからのデータおよび/または信号を通じて他のシステムとインターネットのようなネットワークを通じて伝送されるデータ)によりローカルおよび/または遠隔処理を通じて通信することができる。
また、用語「または」は排他的「または」ではなく内包的「または」を意味するものと意図される。すなわち、別途に特定されないか文脈上明確でない場合に、「XはAまたはBを利用する」という自然的な内包的置換のうち一つを意味するものと図される。すなわち、XがAを利用したり;XがBを利用したり;またはXがAおよびBすべてを利用する場合、「XはAまたはBを利用する」がこれらの場合のいずれにも適用され得る。また、本明細書に使われた「および/または」という用語は列挙された関連アイテムのうち一つ以上のアイテムの可能なすべての組み合わせを指し示し含むものと理解されるべきである。
また、「含む」および/または「含む」という用語は、該当特徴および/または構成要素が存在することを意味するものと理解されるべきである。ただし、「含む」および/または「含む」という用語は、一つ以上の他の特徴、構成要素および/またはこれらのグループの存在または追加を排除しないものと理解されるべきである。また、別途に特定されないか単数の形態を指示するものと文脈上明確でない場合に、本明細書と請求の範囲で単数は一般的に「一つまたはそれ以上」を意味するものと解釈されるべきである。
【0010】
当業者は追加的にここで開示された実施例に関連して説明された多様な例示的論理的ブロック、構成、モジュール、回路、手段、ロジック、およびアルゴリズム段階が電子ハードウェア、コンピュータソフトウェア、または両方すべての組み合わせで具現され得ることを認識しなければならない。ハードウェアおよびソフトウェアの相互交換性を明白に例示するために、多様な例示的コンポーネント、ブロック、構成、手段、ロジック、モジュール、回路、および段階はそれらの機能性の側面で一般的に前述された。そのような機能性がハードウェアでまたはソフトウェアで具現されるかどうかは全般的なシステムに賦課された特定アプリケーション(application)および設計制限にかかっている。熟練した技術者はそれぞれの特定アプリケーションのために多様な方法で説明された機能性を具現することができる。ただし、そのような具現の決定が本発明の領域を逸脱させるものと解釈されてはならない。
提示された実施例に対する説明は本発明の技術分野で通常の知識を有する者が本発明を利用したりまたは実施できるように提供される。このような実施例に対する多様な変形は本発明の技術分野で通常の知識を有する者に明白であろう。ここに定義された一般的な原理は、本発明の範囲を逸脱することなく他の実施例に適用され得る。そして、本発明はここに提示された実施例に限定されるものではない。本発明はここに提示された原理および新規の特徴と一貫する最広義の範囲で解釈されるべきである。
本明細書で、コンピュータは少なくとも一つのプロセッサを含むすべての種類のハードウェア装置を意味するもので、実施例により該当ハードウェア装置で動作するソフトウェア的構成も包括する意味として理解され得る。例えば、コンピュータはスマートフォン、タブレットPC、デスクトップ、ノートパソコンおよび各装置で駆動される使用者クライアントおよびアプリケーションをすべて含む意味として理解され得、また、これに制限されるものではない。
以下、添付された図面を参照して本発明の実施例を詳細に説明する。
本明細書で説明される各段階はコンピュータによって遂行されるものとして説明されるが、各段階の主体はこれに制限されるものではなく、実施例により各段階の少なくとも一部が互いに異なる装置で遂行されてもよい。
本発明の多様な実施例に係る向上した信頼度を有する音響認識結果提供方法は、音響データの認識率が向上するように認識された音響データに対する追加的な検証を遂行する方法、一定時間内に出力される音響認識結果に基づいて音響認識結果のうち少なくとも一部を補正する方法、または周辺環境と雰囲気をリアルタイムで把握し、これを音響データとともに考慮して音響認識結果を導き出す方法を含むことができる。実施例で、音響データの認識正確度の向上は、音響データで特定イベントを感知する認識正確度が向上することを意味し得る。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
アクセサリー型集音器
今日
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
音響材
7日前
横浜ゴム株式会社
水中音響材
10日前
ヤマハ株式会社
ヘルムホルツ共鳴器
1か月前
大和ハウス工業株式会社
音再現設備
14日前
日産自動車株式会社
防音構造体
28日前
岡山県
吸音構造
7日前
セイコーエプソン株式会社
吸音ボード
28日前
株式会社第一興商
カラオケ装置
14日前
株式会社第一興商
カラオケ装置
1か月前
株式会社第一興商
カラオケ装置
6日前
京セラ株式会社
音出力装置及び音出力方法
28日前
コスモネクスト株式会社
入力支援プログラム及び入力支援方法
21日前
本田技研工業株式会社
能動型騒音低減装置
28日前
本田技研工業株式会社
能動型騒音低減装置
6日前
本田技研工業株式会社
能動型騒音低減装置
6日前
日本放送協会
音声認識装置およびプログラム
28日前
本田技研工業株式会社
能動型騒音低減装置
1か月前
個人
発音体モジュール
1日前
株式会社アナザーウェア
鍵盤画面表示プログラム及びそのシステム
1か月前
カシオ計算機株式会社
楽器用電子機器
6日前
トヨタ自動車株式会社
異音診断システム
1か月前
株式会社コルグ
音波生成装置、音波生成方法、プログラム
21日前
株式会社永セ仁
「パワハラ」等ハラスメント発言に係る職場環境測定システム
10日前
ソフトバンクグループ株式会社
行動制御システム
21日前
株式会社AZSTOKE
調整装置、およびプログラム
6日前
本田技研工業株式会社
音声認識装置、音声認識方法、およびプログラム
13日前
永楽電気株式会社
放送音声文字化システム及び放送設備における故障診断方法
28日前
東日本電信電話株式会社
演奏補助装置、演奏補助方法、及び、演奏補助プログラム
13日前
パイオニア株式会社
情報処理装置
15日前
ヤマハ株式会社
響板、その製造方法および響板を備える楽器
13日前
ヤマハ株式会社
信号生成方法、表示制御方法およびプログラム
7日前
ドーナッツロボティクス株式会社
音声処理システム、音声処理方法
21日前
株式会社イノアックコーポレーション
防音カバー
6日前
続きを見る
他の特許を見る

 特許ウォッチ
特許ウォッチ