TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025026182
公報種別
公開特許公報(A)
公開日
2025-02-21
出願番号
2023131606
出願日
2023-08-10
発明の名称
能動学習プログラム、方法、及び装置
出願人
富士通株式会社
代理人
弁理士法人太陽国際特許事務所
主分類
G06N
3/091 20230101AFI20250214BHJP(計算;計数)
要約
【課題】なるべく少ないラベル付きデータで機械学習モデルの精度を向上させるための能動学習による訓練コストを抑制する。
【解決手段】能動学習装置は、誤差予測訓練データ群34を用いて訓練された誤差予測モデル26に基づいて、ラベル無しデータ群36に含まれる複数のラベル無しデータの各々に対するエネルギー予測モデル24の予測誤差を予測し(E)、複数のラベル無しデータから予測誤差が大きいラベル無しデータを選択して、正解ラベルとなるエネルギーの情報を付与してラベル付きデータを生成し(F)、生成したラベル付きデータをエネルギー予測訓練データとして用いて、エネルギー予測モデル24を訓練する(A)。
【選択図】図10
特許請求の範囲
【請求項1】
複数のデータと、前記複数のデータの各々に対する第1機械学習モデルの予測誤差との組を訓練データとして用いて訓練された第2機械学習モデルに基づいて、複数のラベル無しデータの各々に対する前記第1機械学習モデルの予測誤差を予測し、
予測された前記予測誤差に基づいて、前記複数のラベル無しデータから選択したラベル無しデータに正解ラベルを付与してラベル付きデータを生成し、
生成した前記ラベル付きデータを用いて、前記第1機械学習モデルを再訓練する、
ことを含む処理をコンピュータに実行させるための能動学習プログラム。
続きを表示(約 1,300 文字)
【請求項2】
前記複数のラベル無しデータから、予測された前記予測誤差が所定値以上のラベル無しデータ、又は予測された前記予測誤差が上位所定個のラベル無しデータを選択する請求項1に記載の能動学習プログラム。
【請求項3】
複数のラベル付きデータの各々を前記第1機械学習モデルに入力して得られる予測結果の各々と、前記複数のラベル付きデータの正解ラベルの各々とから前記予測誤差の各々を算出し、算出した予測誤差の各々と前記複数のラベル付きデータの各々とから複数の前記訓練データを生成し、
前記訓練データを用いて前記第2機械学習モデルを訓練する、
ことをさらに含む処理を前記コンピュータに実行させるための請求項1又は請求項2に記載の能動学習プログラム。
【請求項4】
再訓練された前記第1機械学習モデルの精度が所定の基準を満たすまで、前記予測誤差の予測、及び前記ラベル付きデータの生成を繰り返す請求項1又は請求項2に記載の能動学習プログラム。
【請求項5】
前記選択したラベル無しデータから生成された前記ラベル付きデータに基づいて生成した前記訓練データを用いて、前記第2機械学習モデルを再訓練する請求項4に記載の能動学習プログラム。
【請求項6】
前記ラベル付きデータは、分子の構造データに正解ラベルとして分子のエネルギーの情報が付与されたデータであり、
前記第1機械学習モデルは、分子の構造データが入力された場合に、前記分子のエネルギーを予測結果として出力する機械学習モデルである、
請求項1又は請求項2に記載の能動学習プログラム。
【請求項7】
前記ラベル付きデータを生成することは、前記選択したラベル無しデータである前記分子の構造データから、密度汎関数理論を用いて前記分子のエネルギーを計算することを含む請求項6に記載の能動学習プログラム。
【請求項8】
複数のデータと、前記複数のデータの各々に対する第1機械学習モデルの予測誤差との組を訓練データとして用いて訓練された第2機械学習モデルに基づいて、複数のラベル無しデータの各々に対する前記第1機械学習モデルの予測誤差を予測し、
予測された前記予測誤差に基づいて、前記複数のラベル無しデータから選択したラベル無しデータに正解ラベルを付与してラベル付きデータを生成し、
生成した前記ラベル付きデータを用いて、前記第1機械学習モデルを再訓練する、
ことを含む処理をコンピュータが実行する能動学習方法。
【請求項9】
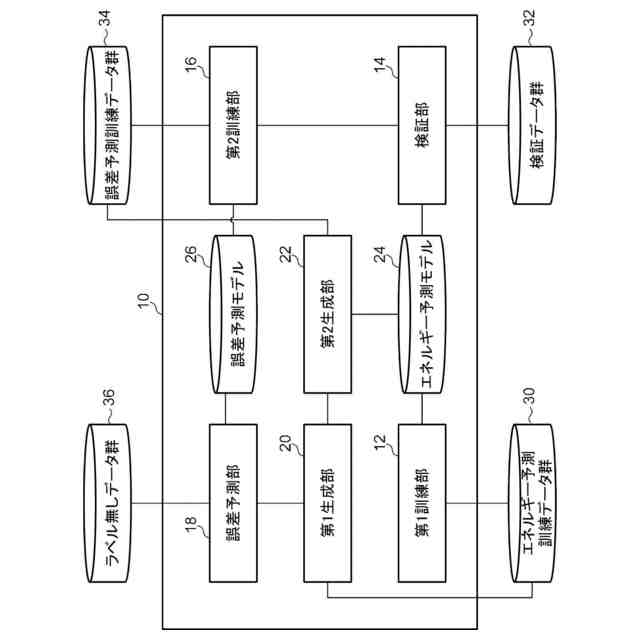
複数のデータと、前記複数のデータの各々に対する第1機械学習モデルの予測誤差との組を訓練データとして用いて訓練された第2機械学習モデルに基づいて、複数のラベル無しデータの各々に対する前記第1機械学習モデルの予測誤差を予測する誤差予測部と、
予測された前記予測誤差に基づいて、前記複数のラベル無しデータから選択したラベル無しデータに正解ラベルを付与してラベル付きデータを生成する第1生成部と、
生成した前記ラベル付きデータを用いて、前記第1機械学習モデルを再訓練する第1訓練部と、
を含む能動学習装置。
発明の詳細な説明
【技術分野】
【0001】
開示の技術は、能動学習プログラム、能動学習方法、及び能動学習装置に関する。
続きを表示(約 2,500 文字)
【背景技術】
【0002】
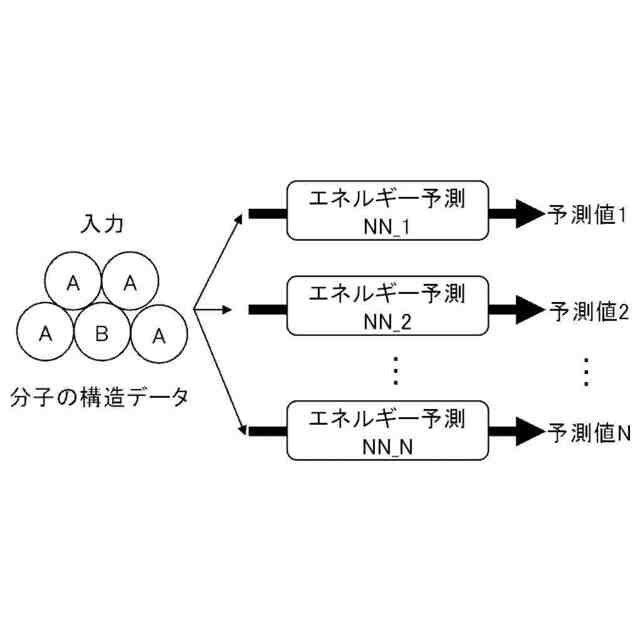
従来、分子の構造データに基づいて、その分子のエネルギーを予測するニューラルネットワークが提案されている。このニューラルネットワークは、「構造」と「エネルギー」とからなるラベル付きデータを用いて教師あり学習により訓練される。この「エネルギー」は、例えば、密度汎関数理論(DFT:Density Functional Theory)と呼ばれる数値計算手法で計算される。DFTによる分子のエネルギーの計算時間は非常に長く、1つの構造のエネルギーの計算に、半日から3日かかる場合もある。そのため、教師あり学習のためのラベル付きデータを大量に集めることが困難である。
【0003】
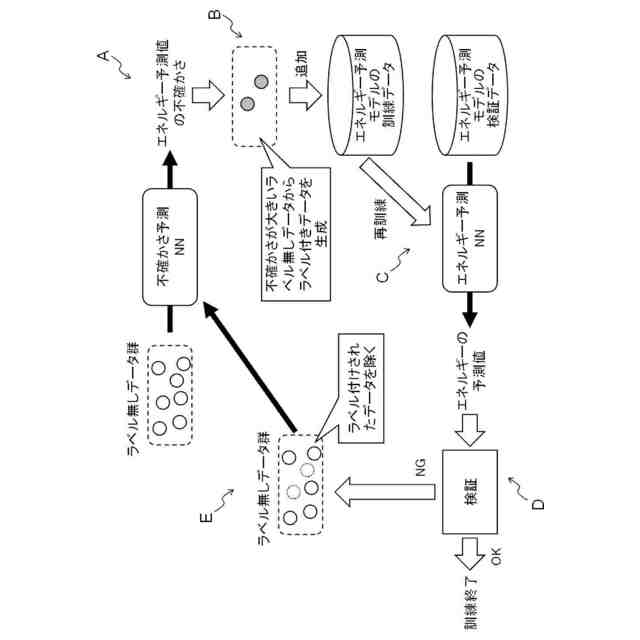
そこで、可能な限り少ないラベル付きデータでニューラルネットワークを高精度化するための能動学習の手法が提案されている。例えば、ニューラルネットワークによるエネルギーの予測値の不確かさを予測する機械学習モデルを用いて、ラベル無しデータについて、エネルギーの予測値の不確かさを予測する技術が提案されている。この技術は、予測された不確かさが大きいラベル無しデータに対してラベル付けを行い、ラベル付けされたデータを用いて、エネルギーを予測するニューラルネットワークの訓練を行う。
【0004】
また、能動学習に関連する技術として、特徴量からなる訓練用例を受け付け、訓練用例にラベルを付与し、ラベルが付与された訓練用例を用いて1つ以上の生徒モデルを生成し、生徒モデルによる予測とラベルとの誤差を算出する情報処理装置が提案されている。この装置は、誤差を予測するモデルである誤差予測モデルを生成し、誤差予測モデルに基づき、誤差が大きくなると予測される用例を出力する。
【先行技術文献】
【特許文献】
【0005】
国際公開2022/113338号
Kristof T. Schutt, Oliver T. Unke, and Michael Gastegger, "Equivariant Message Passing for the Prediction of Tensorial Properties and Molecular Spectra," PMLR, 2021.
Johannes Gasteiger, Muhammed Shuaibi, Anuroop Sriram, Stephan Gunnemann, Zachary Ulissi, C. Lawrence Zitnick, and Abhishek Das, "GemNet-OC: Developing Graph Neural Networks for Large and Diverse Molecular Simulation Datasets," Transactions on Machine Learning Research, 2022.
Joseph Musielewicz, Xiaoxiao Wang, Tian Tian, and Zachary Ulissi, "FINETUNA: Fine-tuning Accelerated Molecular Simulations," arXiv:2205.01223v2 [physics.comp-ph] 1 Jul 2022.
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、ニューラルネットワークによるエネルギーの予測値の不確かさを予測する機械学習モデルを用いる従来技術では、不確かさを予測するために複数のニューラルネットワークを必要とする。すなわち、この従来技術は、能動学習のために複数のニューラルネットワークを用意する必要があり、能動学習による訓練コストが高いという問題がある。
【0007】
一つの側面として、開示の技術は、なるべく少ないラベル付きデータで機械学習モデルの精度を向上させるための能動学習による訓練コストを抑制することを目的とする。
【課題を解決するための手段】
【0008】
一つの態様として、開示の技術は、第2機械学習モデルに基づいて、複数のラベル無しデータの各々に対する前記第1機械学習モデルの予測誤差を予測する。第2機械学習モデルは、複数のデータと、前記複数のデータの各々に対する第1機械学習モデルの予測誤差との組を訓練データとして用いて訓練されている。そして、開示の技術は、予測された前記予測誤差に基づいて、前記複数のラベル無しデータから選択したラベル無しデータに正解ラベルを付与してラベル付きデータを生成し、生成した前記ラベル付きデータを用いて、前記第1機械学習モデルを再訓練する。
【発明の効果】
【0009】
一つの側面として、なるべく少ないラベル付きデータで機械学習モデルの精度を向上させるための能動学習による訓練コストを抑制することができる、という効果を有する。
【図面の簡単な説明】
【0010】
分子のエネルギー予測のNNについて説明するための図である。
背景技術を説明するための図である。
背景技術における不確かさ予測NNを説明するための図である。
本実施形態に係る能動学習装置の機能ブロック図である。
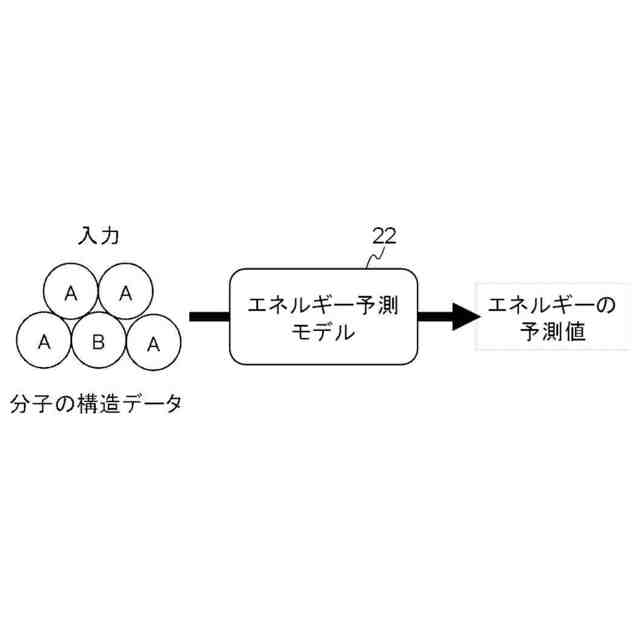
エネルギー予測モデルを説明するための図である。
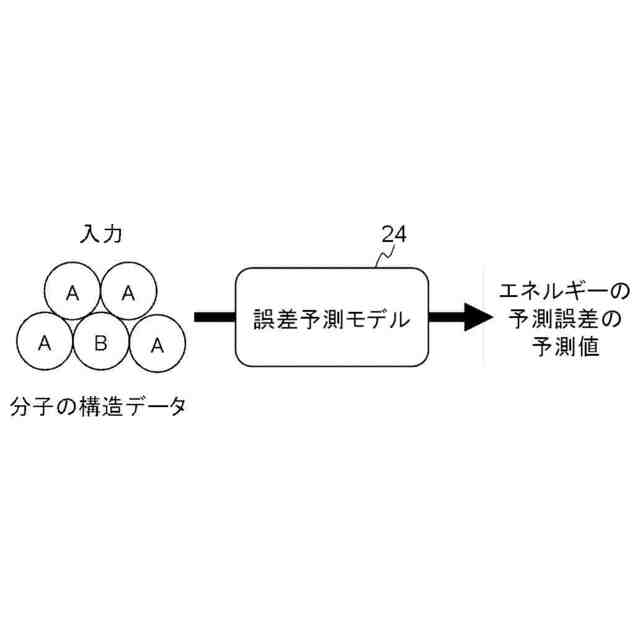
誤差予測モデルを説明するための図である。
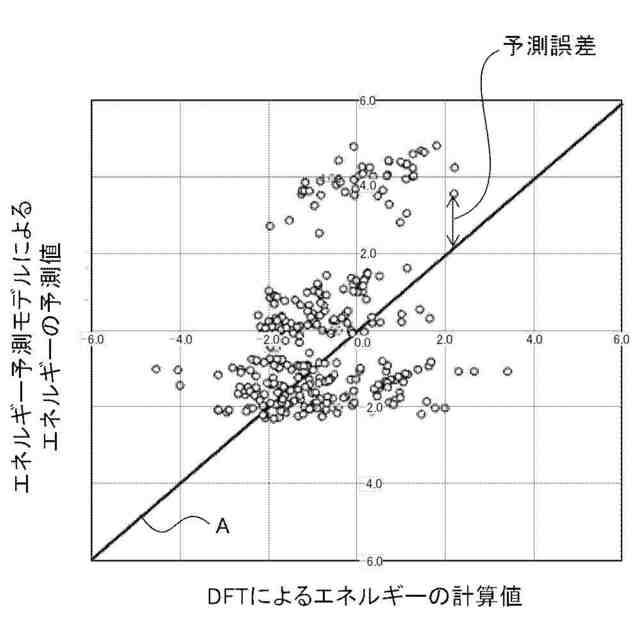
DFTによるエネルギーの計算値と、エネルギー予測モデルによるエネルギーの予測値との関係の一例を示す図である。
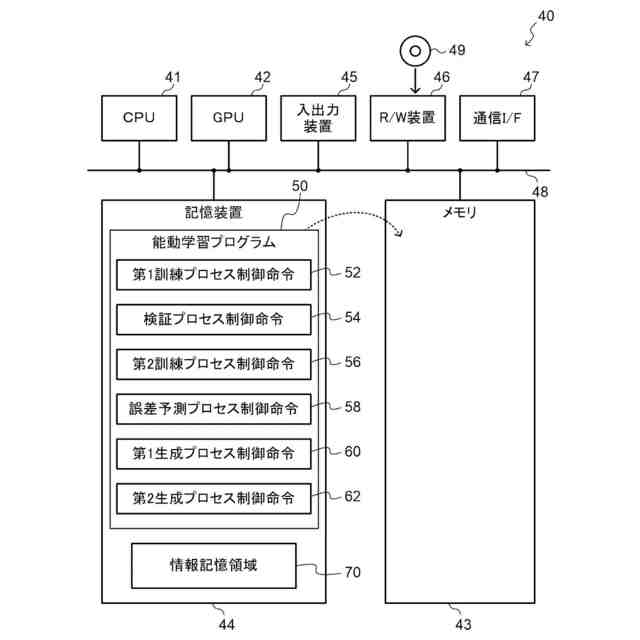
能動学習装置として機能するコンピュータの概略構成を示すブロック図である。
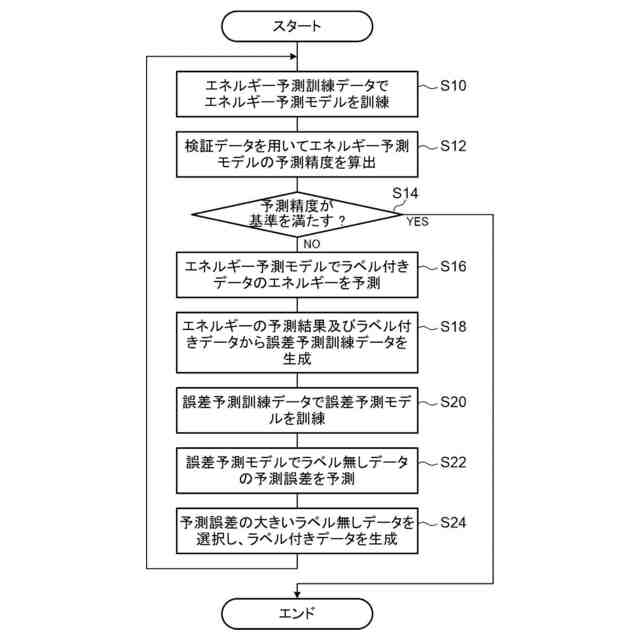
能動学習処理の一例を示すフローチャートである。
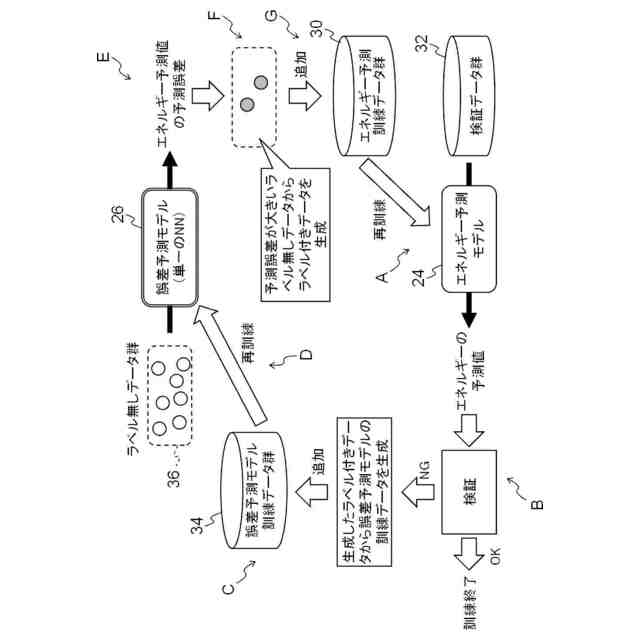
能動学習装置における処理の概略を示す図である。
本手法の効果についての検証結果を示す図である。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る

 特許ウォッチ
特許ウォッチ