TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025013953
公報種別
公開特許公報(A)
公開日
2025-01-28
出願番号
2024187180,2022026883
出願日
2024-10-24,2022-02-24
発明の名称
演算アーキテクチャにおける8ビット浮動小数点オペランドのサポート
出願人
インテル コーポレイション
代理人
弁理士法人ITOH
主分類
G06F
17/16 20060101AFI20250121BHJP(計算;計数)
要約
【課題】8ビット浮動小数点オペランドを使用して演算するためのハードウェアを提供する。
【解決手段】処理システム100において、フェッチした命令をデコードするデコーダを含む。デコードされた命令は、8ビット浮動小数点オペランドに作用して並列ドット積演算を実行する行列命令である。システムはまた、デコードされた命令をスケジューリングするコントローラを含む。コントローラは、デコードされた命令によって指定される8ビット浮動小数点データ・フォーマットに従って入力データを8ビット浮動小数点オペランドに提供する。システムはさらに、デコードされた命令を、シストリック層を使用して実行するシストリック・ドット積回路を含む。各々のシストリック層は、相互接続された乗算器、シフター及び加算器の1つ以上のセットを含み、乗算器、シフター及び加算器の各セットは、8ビット浮動小数点オペランドのドット積を生成する。
【選択図】図1
特許請求の範囲
【請求項1】
集積回路チップを含む装置であって、前記集積回路チップは:
8ビット浮動小数点データ要素と32ビット浮動小数点データ要素とを含む複数のデータ要素を格納する複数のレジスタ;
第1の8ビット浮動小数点フォーマットでエンコードされた第1の複数の8ビット浮動小数点データ要素を含む第1のソース行列、第2の8ビット浮動小数点フォーマットでエンコードされた第2の複数の8ビット浮動小数点データ要素を含む第2のソース行列、及び、複数の32ビット浮動小数点データ要素を含む第3のソース行列のロケーションとオペコードとを示すフィールドを有する単一の行列命令をデコードするデコード回路であって、前記第1の8ビット浮動小数点フォーマットは符号ビットと、5ビットの指数値と、2ビットの仮数値とを含み、前記第2の8ビット浮動小数点フォーマットは符号ビットと、4ビットの指数値と、3ビットの仮数値とを含む、デコード回路;及び
行列演算を加速する行列アクセラレータを含む実行回路であって、前記単一の行列命令に応じて、前記実行回路は、前記第1のソース行列の前記第1の複数の8ビット浮動小数点データ要素と前記第2のソース行列の前記第2の複数の8ビット浮動小数点データ要素とに基づいて複数の積を生成し、前記複数の積のうちの各々の積を、前記第3のソース行列の対応する32ビット浮動小数点データ要素にアキュムレートして、結果の行列の対応する32ビット浮動小数点結果データ要素を生成する、実行回路;
を含む装置。
続きを表示(約 1,600 文字)
【請求項2】
パッケージ・アセンブリを更に含む請求項1に記載の装置において、前記パッケージ・アセンブリは:
グラフィックス・プロセッサ・チップレットを含む前記集積回路チップ;
第1の相互接続ファブリックと、前記第1の相互接続ファブリックに結合された第1のグローバル・キャッシュとを含む第1のベース・チップレットであって、前記グラフィックス・プロセッサ・チップレットは、前記第1のベース・チップレット上にスタックされ、第1の相互接続構造が、前記グラフィックス・プロセッサ・チップレットを前記第1の相互接続ファブリックに結合している、第1のベース・チップレット;
第2の相互接続構造により前記第1のベース・チップレットに結合された第2のベース・チップレットであって、第2の相互接続ファブリックと、前記第2の相互接続ファブリックに結合された第2のグローバル・キャッシュとを含む第2のベース・チップレット;
前記第2のベース・チップレット上にスタックされたプロセッサ・コア・チップレットであって、複数のプロセッサ・コアを含んでおり、第3の相互接続構造が、前記プロセッサ・コア・チップレットを前記第2の相互接続ファブリックに結合している、プロセッサ・コア;
を含む、装置。
【請求項3】
請求項2に記載の装置において、前記グラフィックス・プロセッサ・チップレットは、前記第1及び第2のベース・チップレットを製造するために使用されたプロセス技術とは異なるプロセス技術を用いて製造されている、装置。
【請求項4】
請求項2又は3に記載の装置において、更に:
前記グラフィックス・プロセッサ・チップレット及び前記プロセッサ・コア・チップレットを、統合メモリに結合する1つ以上のメモリ・コントローラであって、前記グラフィックス・プロセッサ・チップレット及び前記プロセッサ・コア・チップレットは、統合された仮想アドレス空間を共有する前記統合メモリにアクセスする、装置。
【請求項5】
請求項1ないし4のうちの何れか一項に記載の装置において、前記単一の行列命令に応じる前記実行回路による実行のためのコマンドのセットをスケジューリングするスケジューラを更に含む装置。
【請求項6】
請求項1ないし5のうちの何れか一項に記載の装置において、前記実行回路は、複数の単一命令多重データ・チャネルを介して前記単一の行列命令を実行するためのものである、装置。
【請求項7】
請求項6に記載の装置において、前記複数の単一命令多重データ・チャネルのうちの個々の単一命令多重データ・チャネルにおいて、前記第1のソース行列の前記第1の複数の8ビット浮動小数点データ要素のうちの8ビット浮動小数点データ要素のグループを、前記第2のソース行列の前記第2の複数の8ビット浮動小数点データ要素のうちの8ビット浮動小数点データ要素の対応するグループに乗算するためのものである、装置。
【請求項8】
請求項6又は7に記載の装置において、前記単一命令多重データ・チャネルは、32ビットの単一命令多重データ・チャネルを含む、装置。
【請求項9】
請求項8に記載の装置において、前記32ビットの単一命令多重データ・チャネルのうちの1つにおいて、前記第1のソース行列の前記第1の複数の8ビット浮動小数点データ要素のうちの4つのグループは、前記第2のソース行列の前記第2の複数の8ビット浮動小数点データ要素のうちの4つの対応するグループと乗算される、装置。
【請求項10】
請求項4に記載の装置において、仮想-物理アドレス・マッピングをもたらす複数のメモリ管理ユニットを更に含む、装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
[0001] 本件は一般にデータ処理に関連し、特に演算アーキテクチャにおける8ビット浮動小数点フォーマット・オペランドをサポートすることに関連する。
続きを表示(約 6,700 文字)
【背景技術】
【0002】
[0002] 現在の並列グラフィックス・データ処理は、例えば、線型補間、テセレーション、ラスタライゼーション、テクスチャ・マッピング、深度テスト等のようなグラフィックス・データに対する特定の演算を実行するために開発されたシステム及び方法を含む。従来、グラフィックス・プロセッサは、グラフィックス・データを処理するために固定機能計算ユニットを使用していた;しかしながら、より最近では、グラフィックス・プロセッサの一部がプログラム可能にされており、このようなプロセッサが、頂点データ及びフラグメント・データを処理するためのより広範なオペレーションをサポートすることを可能にしている。
【0003】
[0003] パフォーマンスを更に向上させるために、グラフィックス・プロセッサは、典型的には、グラフィックス・パイプラインの異なる部分を通る可能な限り多くのグラフィックス・データを並行的に処理しようとするパイプライン化のような処理技術を実装する。単一命令、多重データ(SIMD)又は単一命令、多重スレッド(SIMT)アーキテクチャを有する並列グラフィックス・プロセッサは、グラフィックス・パイプラインにおける並列処理の量を最大化するように設計される。SIMDアーキテクチャでは、複数の処理エレメントを有するコンピュータは、複数のデータ・ポイントにおいて同じ動作を同時に実行しようとする。SIMTアーキテクチャでは、並列スレッドのグループは、処理効率を高めるために、可能な限り頻繁にプログラム命令を同期させて一緒に実行しようと試みる。
【0004】
[0004] グラフィックス・プロセッサは、人工知能(AI)及び機械学習(ML)の分野におけるアプリケーションに頻繁に利用される。これらの分野の進歩により、MLモデルは、ニューラル・ネットワークのトレーニングのために低精度演算を利用することが可能になっている。従来のトレーニング・プラットフォームは、高性能シストリック・アレイ実装における浮動小数点16(FP16)及びブレイン浮動小数点16(bfloat16又はBF16)データ・フォーマットをサポートしている。最近は、8ビット・データ・フォーマットのような低精度データ・フォーマットを使用するディープ・ニューラル・ネットワークのトレーニングを支援するように作られている。しかしながら、従来のシステムは、8ビット浮動小数点フォーマット・オペランドを使用して演算を実行するためのハードウェア・サポートを提供しない。
【図面の簡単な説明】
【0005】
[0005] 本実施形態の上記の特徴を詳細に理解することができるように、ここで簡単に要約される実施形態のより詳細な説明は、実施形態を参照することによって行われ、そのうちの一部は添付図面に示されている。しかしながら、添付図面は、典型的な実施形態しかを示しておらず、従ってその範囲を限定するように解釈されるべきでないことに留意されたい。
【0006】
[0006]
処理システムのブロック図である。 [0007]
コンピューティング・システム及びグラフィックス・プロセッサを示す。
コンピューティング・システム及びグラフィックス・プロセッサを示す。
コンピューティング・システム及びグラフィックス・プロセッサを示す。
コンピューティング・システム及びグラフィックス・プロセッサを示す。 [0008]
追加的なグラフィックス・プロセッサ及び演算アクセラレータ・アーキテクチャのブロック図を示す。
追加的なグラフィックス・プロセッサ及び演算アクセラレータ・アーキテクチャのブロック図を示す。
追加的なグラフィックス・プロセッサ及び演算アクセラレータ・アーキテクチャのブロック図を示す。 [0009]
グラフィックス・プロセッサのグラフィックス処理エンジンのブロック図である。 [0011]
グラフィックス・プロセッサ・コアで使用される処理要素のアレイを含むスレッド実行ロジックを示す。
グラフィックス・プロセッサ・コアで使用される処理要素のアレイを含むスレッド実行ロジックを示す。 [0011]
追加的な実行ユニットを示す。 [0012]
グラフィックス・プロセッサ命令フォーマットを示すブロック図である。 [0013]
追加的なグラフィックス・プロセッサ・アーキテクチャのブロック図である。 [0014]
グラフィックス・プロセッサ・コマンド・フォーマット及びコマンド・シーケンスを示す。
グラフィックス・プロセッサ・コマンド・フォーマット及びコマンド・シーケンスを示す。 [0015]
データ処理システムのための例示的なグラフィックス・ソフトウェア・アーキテクチャを示す。 [0016]
IPコア開発システムを示すブロック図である。 [0017]
集積回路パッケージ・アセンブリの側断面図を示す。 [0018]
基板(例えば、ベース・ダイ)に接続されたハードウェア論理チップレットの複数のユニットを含むパッケージ・アセンブリを示す。 [0019]
交換可能なチップレットを含むパッケージ・アセンブリを示す。 [0020]
チップ集積回路における例示的なシステムを示すブロック図である。 [0021]
SoC内で使用するための例示的なグラフィックス・プロセッサを示すブロック図である。
SoC内で使用するための例示的なグラフィックス・プロセッサを示すブロック図である。 [0022]
実施形態によるデータ処理システムのブロック図である。 [0023]
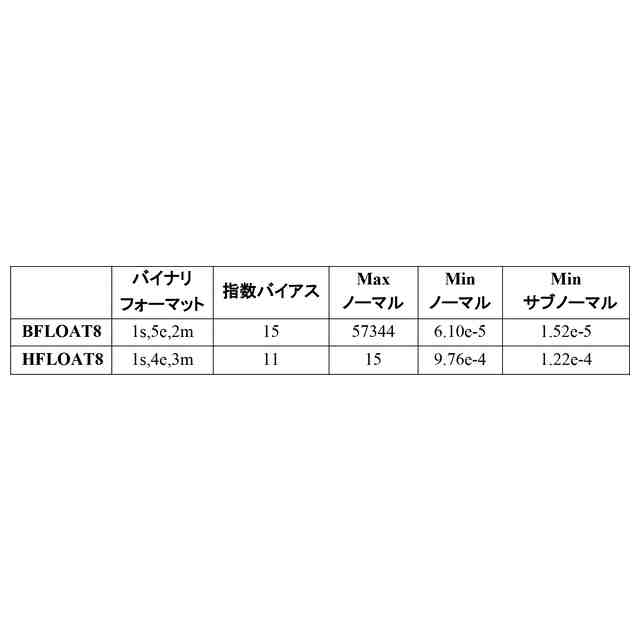
実施形態によるブレイン・フロート8(BFLOAT8又はBF8)のバイナリ・フォーマットを示すブロック図である。 [0024]
実施形態による命令パイプラインによって実行されるシストリックDP 8ビットFPフォーマット動作を示すブロック図である。 [0025]
実施形態による8ビット浮動小数点フォーマット入力オペランドに関してシストリック・ドット積を実行するシストリック・アレイ回路を示すブロック図である。
実施形態による8ビット浮動小数点フォーマット入力オペランドに関してシストリック・ドット積を実行するシストリック・アレイ回路を示すブロック図である。 [0026]
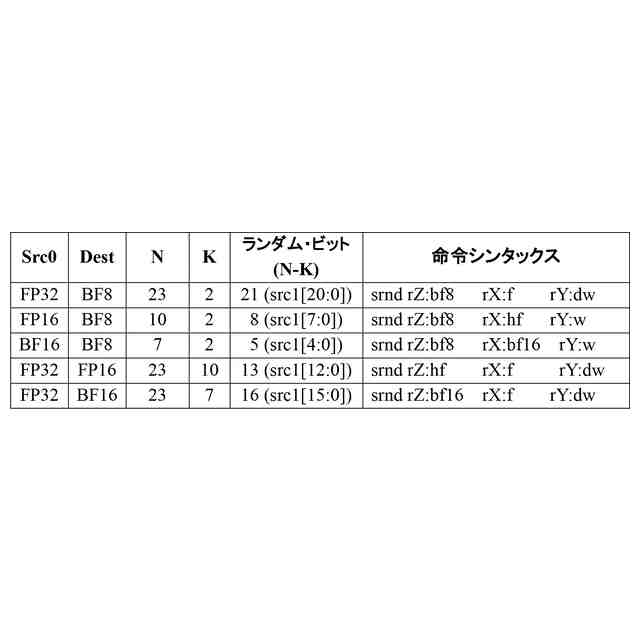
本件で説明される実施形態に従ってシストリック・アレイ回路によって実行することが可能な命令を示す。 [0027]
実施形態によるプログラム・コード・コンパイル・プロセスを示す。 [0028]
8ビット浮動小数点フォーマットの入力オペランドに関するシストリック・ドット積蓄積の命令を実行するための方法の実施形態を示すフローチャートである。 [0029]
8ビット浮動小数点フォーマットの入力オペランドに関するシストリック・ドット積蓄積のための方法の実施形態を示すフローチャートである。 [0030]
実施形態に従って命令パイプラインにより実行される8ビットFPフォーマット変換動作を示すブロック図である。 [0031]
本件で説明される実施形態に従って処理ユニットにより実行することが可能な命令を示す。 [0032]
実施形態によるプログラム・コード・コンパイル・プロセスを示す。 [0033]
浮動小数点データを8ビット浮動小数点フォーマット・データに変換する命令を実行するための方法の実施形態を示すフローチャートである。 [0034]
浮動小数点データを8ビット浮動小数点フォーマット・データに変換する方法の実施形態を示すフローチャートである。 [0035]
実施形態に従って命令パイプラインによって実行される確率的丸め演算を伴う8ビットFPフォーマット変換を示すブロック図である。 [0036]
実施形態による仮数及び乱数の符号-大きさ表現の固定小数点加算を示すブロック図である。 [0037]
本件で説明される実施形態に従って処理ユニットによって実行することが可能な命令を示す。 [0038]
実施形態によるプログラム・コード・コンパイル・プロセスを示す。 [0039]
浮動小数点値に対して効率的な確率的丸めを実行するための命令を実行する方法の実施形態を示すフローチャートである。 [0040]
浮動小数点値に対して効率的な確率的丸めを実行するための方法の実施形態を示すフローチャートである。 [0041]
実施形態に従う異なるバイナリ符号化及び指数バイアスを使用する2つの8ビット浮動小数点フォーマットを示すブロック図である。 [0042]
実施形態に従う命令パイプラインによって実行されるハイブリッド8ビットFPフォーマットのシストリック動作を示すブロック図である。 [0043]
実施形態によるハイブリッド浮動小数点・確率的動作を行うためのシストリック・アレイ回路のハイブリッドFMAユニットを示すブロック図である。 [0044]
本件で説明される実施形態に従うシストリック・アレイ回路によって実行することが可能な命令を示す。 [0045]
実施形態によるプログラム・コード・コンパイル・プロセスを示す。 [0046]
ハイブリッド浮動小数点シストリック動作の命令を実行するための方法の実施形態を示すフローチャートである。 [0047]
ハイブリッド浮動小数点シストリック動作のための方法の実施形態を示すフローチャートである。 [0048]
実施形態に従って命令パイプラインによって実行される混合モード8ビットFPフォーマット動作を示すブロック図である。 [0049]
実施形態に従う少なくとも1つの8ビットFPフォーマット・オペランドを使用して混合モードMAC動作を実行するためのハードウェア回路の例示的な略図を示す。 [0050]
本件で説明される実施形態に従って処理ユニットによって実行することが可能な命令のセットを示す。 [0051]
実施形態によるプログラム・コード・コンパイル・プロセスを示す。 [0052]
8ビット浮動小数点フォーマット・オペランドを用いて混合モード演算を実行するための命令を実行する方法の実施形態を示すフローチャートである。 [0053]
8ビット浮動小数点フォーマット・オペランドを用いて混合モード演算を実行するための方法の実施形態を示すフローチャートである。
【発明を実施するための形態】
【0007】
[0054] グラフィックス処理ユニット(GPU)は、例えばグラフィックス演算、機械学習演算、パターン解析演算、及び/又は種々の汎用GPU(GPGPU)機能を加速させるために、ホスト/プロセッサ・コアに通信可能に結合される。GPUは、バス又は他の相互接続(例えば、PCIe又はNVLinkのような高速相互接続)を介してホスト・プロセッサ/コアに通信可能に結合されてもよい。或いは、GPUは、コアと同じパッケージ又はチップ上に統合されてもよいし、内部プロセッサ・バス/相互接続(即ち、パッケージ又はチップの内部)でコアに通信可能に結合されてもよい。GPUが接続される方法にかかわらず、プロセッサ・コアは、作業記述子に含まれる一連のコマンド/命令の形式で、作業をGPUに割り当てることができる。そして、GPUは、これらのコマンド/命令を効率的に処理するために、専用の回路/ロジックを使用する。
【0008】
[0055] 以下の説明では、より完全な理解をもたらすために、多くの具体的な詳細が述べられている。しかしながら、本願で説明される実施形態は、これらの具体的な詳細の1つ以上によらず実施されてもよいことは、当業者に明らかであろう。他の例において、周知の特徴は、本実施形態の詳細を不明瞭にすることを避けるために記載されていない。
【0009】
システム概要
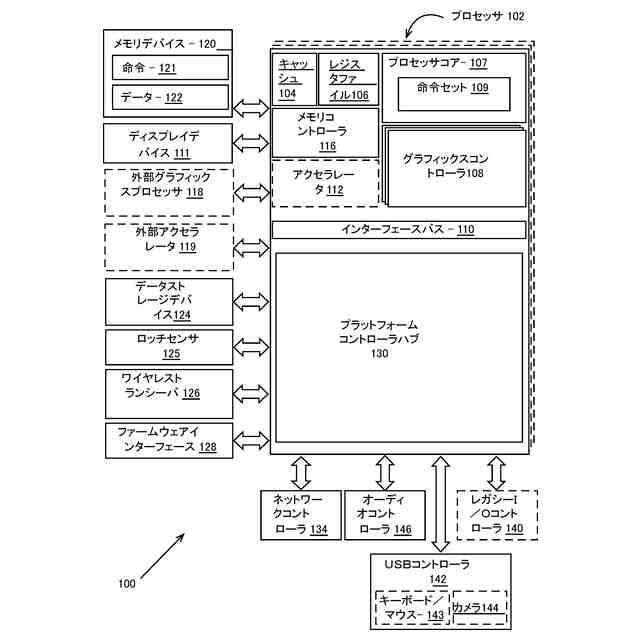
[0056] 図1は、実施形態による処理システム100のブロック図である。システム100は、シングル・プロセッサ・デスクトップ・システム、マルチプロセッサ・ワークステーション・システム、又は、多数のプロセッサ102又はプロセッサ・コア107を有するサーバー・システムで使用されてもよい。一実施形態では、システム100は、ローカル又はワイド・エリア・ネットワークへの有線又は無線の接続を利用するモノのインターネット(IoT)のデバイスにおけるもののようなモバイルの、ハンドヘルドの、又は埋め込み式のデバイスで使用するための、システム・オン・チップ(SoC)集積回路内に組み込まれた処理プラットフォームである。
【0010】
[0057] 一実施形態では、システム100は、サーバー・ベースのゲーム・プラットフォーム;ゲーム及びメディア・コンソールを含むゲーム・コンソール;モバイル・ゲーム・コンソール、ハンドヘルド・ゲーム・コンソール、又はオンライン・ゲーム・コンソールを含むこと、それらと結合すること、又はそれらの中に統合されることが可能である。幾つかの実施形態では、システム100は、移動電話、スマート・フォン、タブレット・コンピューティング・デバイス、又は、小さな内部記憶容量しか有しないラップトップのようなモバイル・インターネット接続デバイスの一部である。また、処理システム100は、スマート・ウォッチ・ウェアラブル・デバイスのようなウェアラブル・デバイス;現実世界の視覚、聴覚、又は触覚の体験を補うための、或いはその他の文字、音声、図形、ビデオ、ホログラフィック画像又はビデオ、又は触覚的なフィードバックを提供するための、視覚、聴覚、触覚の出力を提供するために拡張現実(AR)又は仮想現実(VR)機能で強化されたスマート・アイウェア又は衣類;その他の拡張現実(AR)デバイス;又はその他の仮想現実(VR)デバイスを含むこと、それらに結合すること、又はそれらに統合されることが可能である。幾つかの実施形態では、処理システム100は、テレビジョン又はセット・トップ・ボックス・デバイスを含むか、又はその一部である。一実施形態では、システム100は、バス、トラクター・トレーラー、自動車、モーター又は電動自転車、飛行機又はグライダ(又はそれらの任意の組み合わせ)などの自動運転を行う乗り物を含むこと、それらに結合すること、又はそれらに統合されることが可能である。自動運転を行う乗り物は、乗り物の周囲で感知された環境を処理するためにシステム100を使用することが可能である
[0058] 一部の実施形態では、1つ以上のプロセッサ102はそれぞれ、実行されるとシステム又はユーザー・ソフトウェアのための演算を実行する命令を処理するために1つ以上のプロセッサ・コア107を含む。本件における実施形態において、プロセッサは、コマンド/命令を効率的に処理するための専用ハードウェア回路と言及することが可能であり、プロセッサ回路と言及されてもよい。幾つかの実施形態では、1つ以上のプロセッサ・コア107のうちの少なくとも1つは、特定の命令セット109を処理するように構成される。幾つかの実施形態において、命令セット109は、複合命令セット演算(CISC)、縮小命令セット演算(RISC)、又は超長命令ワード(VLIW)による演算を促進することができる。1つ以上のプロセッサ・コア107は、他の命令セットのエミュレーションを促進するための命令を含むことが可能な異なる命令セット109を処理することができる。プロセッサ・コア107はまた、デジタル信号プロセッサ(DSP)などの他の処理デバイスを含んでもよい。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る







 特許ウォッチ
特許ウォッチ