TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024167376
公報種別
公開特許公報(A)
公開日
2024-12-03
出願番号
2024151554,2020217693
出願日
2024-09-03,2020-12-25
発明の名称
転移因子検出法
出願人
国立研究開発法人農業・食品産業技術総合研究機構
代理人
個人
,
個人
,
個人
主分類
C12Q
1/6874 20180101AFI20241126BHJP(生化学;ビール;酒精;ぶどう酒;酢;微生物学;酵素学;突然変異または遺伝子工学)
要約
【課題】配列中の転移因子を特定する手段を提供する。
【解決手段】本開示の方法は、リファレンスゲノム配列の情報を必要とすることなく、転移因子を検出できる。例えば、次世代シーケンサーのショートリードの解析から、転移因子を検出することができる。本開示の方法は、配列未知の転移因子の検出に使用可能である。また、本開示の方法は、実際に転移を起こしている活性な転移因子を検出し得る。本開示は、転移因子を検出するための方法、プログラム、記録媒体またはシステムならびに特定された転移因子またはその使用に関する。
【選択図】なし
特許請求の範囲
【請求項1】
配列中の転移因子を特定する方法であって、
(A)2種類のサンプル由来のショートリードから、X塩基の配列を1塩基ずつずらして切り出す工程と、
(B)得られた複数のX塩基の各配列の頻度を取得する工程と、
(C)得られた複数のX塩基の配列において、ぞれぞれの配列の前半部分および後半部分のリファレンス配列上での位置を取得して比較する工程と、
を含む、方法。
続きを表示(約 1,200 文字)
【請求項2】
前記前半部分および前記後半部分の塩基長がX/2塩基である、請求項1に記載の方法。
【請求項3】
Xは20塩基以上である、請求項1または2に記載の方法。
【請求項4】
配列中の転移因子の標的部位重複(TSD)及び/またはジャンクションを検出する方法であって、
(A)2種類のサンプル由来のショートリードから、X塩基の配列を1塩基ずつずらして切り出す工程と、
(B)得られた複数のX塩基の各配列の頻度を取得する工程と、
(C)得られた複数のX塩基の配列において、ぞれぞれの配列の前半部分および後半部分のリファレンス配列上での位置を取得して比較する工程と、
を含む、方法。
【請求項5】
前記前半部分および前記後半部分の塩基長がX/2塩基である、請求項4に記載の方法。
【請求項6】
Xは20塩基以上である、請求項4または5に記載の方法。
【請求項7】
(A)2種類のサンプル由来のショートリードから、X塩基の配列を1塩基ずつずらして切り出す工程と、
(B)得られた複数のX塩基の各配列の頻度を取得する工程と、
(B1)複数のX塩基の各配列をソートして出力する工程と、
(B2)該2種類のサンプルのいずれかに特異的なX塩基の配列を抽出する工程と、
(C1)抽出されたX塩基の配列において、それぞれの配列の前半X/2塩基の配列に対応するリファレンス配列上での位置を取得する工程と、
(C2)抽出されたX塩基の配列において、それぞれの配列の後半X/2塩基の配列に対応するリファレンス配列上での位置を取得する工程と、
(C3)C1およびC2で得られた位置データを染色体別にわけてソートする工程と、
(D)C3においてソートされた位置データから、それぞれのジャンクション位置がずれてTSDを形成し、かつTSDの長さがs1以上s2以下のものを出力する工程と、
(E)TSDが2種類以上ある前半X/2塩基の3’末端側に隣接するTSDと後半X/2塩基の5’末端側に隣接するTSDとを選抜し、選抜したデータセットから、5’末端側に隣接するTSDと3’末端側に隣接するTSDとが同一である該X塩基の配列のペアをすべて選抜する工程と、
(F)該2種類のサンプルのいずれにも存在する該X/2塩基の配列のペアであって、かつ2種類以上の異なるTSD配列を持つペアを選抜する工程と、
(G)C1およびC2で得られた位置データから、Fにおいて選抜されたペアを出力する工程と
を含む、請求項1または4に記載の方法。
【請求項8】
Xが20以上である、請求項7に記載の方法。
【請求項9】
s1が3以上である、請求項7または8に記載の方法。
【請求項10】
s2が20以下である、請求項7~9のいずれか一項に記載の方法。
発明の詳細な説明
【技術分野】
【0001】
本開示は、配列情報、とりわけ、ゲノム等の生体分子の配列情報の情報処理の分野に関する。本開示は、転移因子の検出により、医療、ヘルスケア、農業、林業、畜産業、水産業、環境での応用および基礎研究の分野において利用可能である。
続きを表示(約 9,100 文字)
【背景技術】
【0002】
ゲノム中には多くの種類の転移因子が様々なコピー数で存在しており、大部分は変異が起こって不活性な状態である。これらの大量の不活性な転移因子の情報が障害となって、塩基配列情報から活性のある新規な転移因子を検出するのは困難であった。
【発明の概要】
【課題を解決するための手段】
【0003】
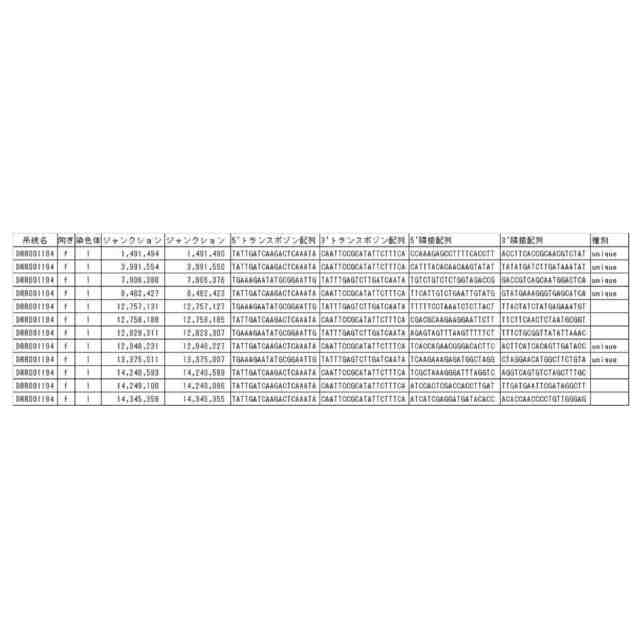
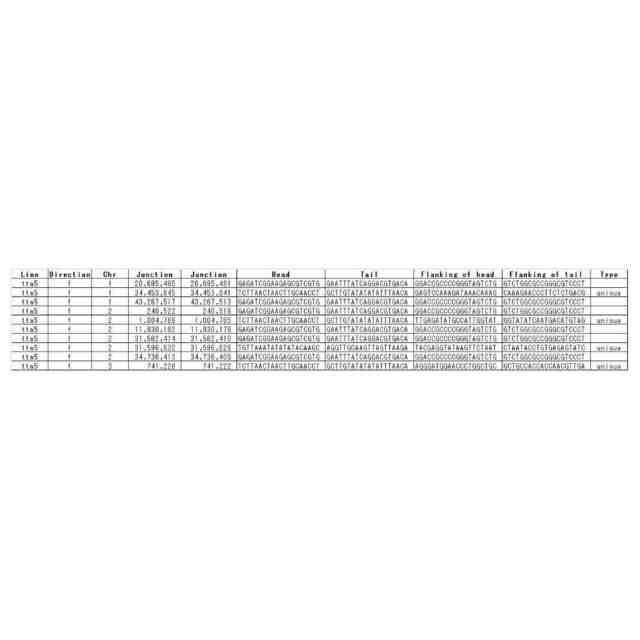
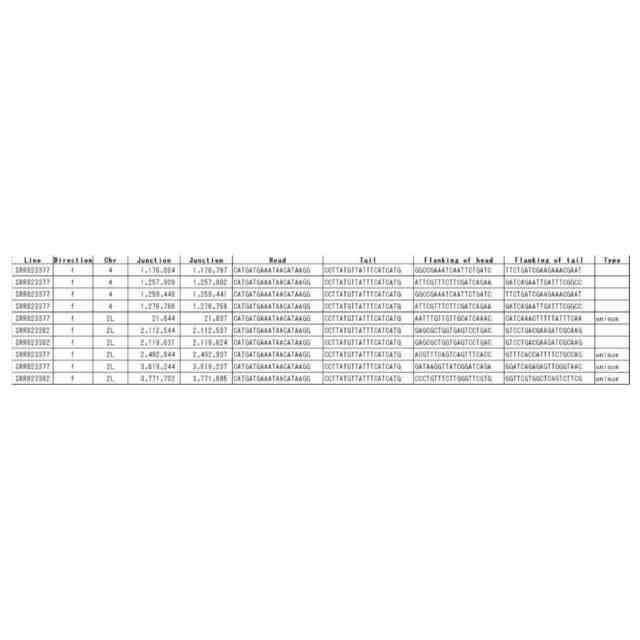
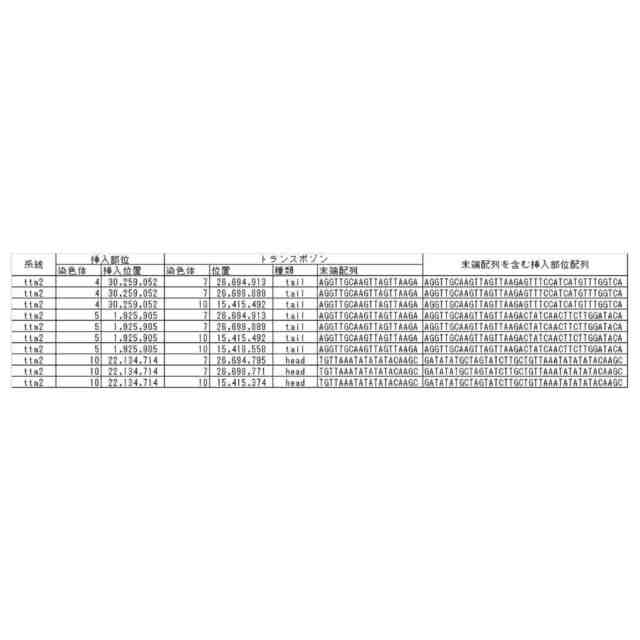
転移因子が転移する際に、標的部位に数塩基の配列の重複(Target Site Duplication、TSD)が起こる場合があることが知られている。例えばTSDのサイズが5塩基の転移因子の場合、転移因子の5’末端の上流5塩基と3’末端の下流5塩基の配列は同じになる。トランスポゾンの両末端とTSDに着目すると、新たに転移したトランスポゾンでは、転移ごとに標的部位の塩基配列が異なるので、その結果としてTSDの配列が異なると考えられる。2つの試料から得られた塩基配列より、TSDの配列が異なるトランスポゾンの5’末端と3’末端のペアを検出することにより、参照配列を用いないで直接転移を検出することが可能であることを本開示において見出した。
【0004】
本開示において、配列中の転移因子を特定する方法であって、(A)ゲノム配列データから一定長の配列を1塩基ずつずらして切り出して、切り出し配列のセットを生成するステップ、(B)切り出し配列のそれぞれを、n塩基長の部分とそれ以外の部分に切り分け、5’末端のn塩基長の部分と3’末端のn塩基長の部分とが同一である切り出し配列のペアを選抜するステップ、(C)選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップ、および/または(D)対応する転移因子部分配列を有する切り出し配列のペアから、ゲノム配列データによってn塩基長部分が異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップを含む方法が提供される。方法は、本明細書に記載される追加的な工程をさらに含んでもよい。本開示において、当該方法を実装するプログラムもしくはそれを格納する記録媒体、あるいはそのためのシステムもまた提供され得る。本開示の別の態様は、特定された転移因子、またはその使用に関する。
【0005】
本開示の例として、以下の項目が挙げられる。
(項目1) 配列中の転移因子を特定する方法であって、
(A)第1のゲノム配列データおよび第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(B)該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップと、
(C)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(D)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとにおいて、該TSDが異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップと
を含む、方法。
(項目2) 前記ステップ(B)の前に、前記第1のゲノム配列データからの切り出し配列のセットと、前記第2のゲノム配列データからの切り出し配列のセットとで異なる切り出し配列を選抜するステップを含み、
5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアの選抜が、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとで異なる切り出し配列の中から行われる、前記項目に記載の方法。
(項目3) 前記切り出し配列のセットにおいて、同一の切り出し配列の頻度を計算するステップをさらに含む、前記項目のいずれかに記載の方法。
(項目4) 前記切り出し配列のセットにおいて、一定以下の頻度の切り出し配列を除外するステップをさらに含む、前記項目のいずれかに記載の方法。
(項目5) 前記転移因子対応ペアに基づいて、転移因子配列を特定するステップをさらに含む、前記項目のいずれかに記載の方法。
(項目6) 前記転移因子の転移活性を確認するステップをさらに含む、前記項目のいずれかに記載の方法。
(項目7) 前記転移因子の転移活性の確認が、PCR、配列決定、およびハイブリダイゼーションから選択される1つ以上によってなされる、前記項目のいずれかに記載の方法。
(項目8) ステップ(B)~(D)を、nを変更して繰り返すステップをさらに含む、前記項目のいずれかに記載の方法。
(項目9) nが3~20である、前記項目のいずれかに記載の方法。
(項目10) 前記一定長が17~50塩基長である、前記項目のいずれかに記載の方法。
(項目11) 前記対応する転移因子部分配列が、少なくとも90%の同一性を有する転移因子部分配列である、前記項目のいずれかに記載の方法。
(項目12) 前記対応する転移因子部分配列が、少なくとも95%の同一性を有する転移因子部分配列である、前記項目のいずれかに記載の方法。
(項目13) 前記対応する転移因子部分配列が、同一の転移因子部分配列である、前記項目のいずれかに記載の方法。
(項目14) 前記切り出し配列のセットを生成するステップが、第1のゲノム配列データおよび第2のゲノム配列データの相補鎖について前記一定長の配列を1塩基ずつずらして切り出すことを含む、前記項目のいずれかに記載の方法。
(項目15) 配列中の転移因子を特定する方法をコンピュータに実行させるためのプログラムであって、該方法が、
(a)第1のゲノム配列データおよび第2のゲノム配列データを受け取るステップと、
(b)該第1のゲノム配列データおよび該第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(c)該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップと、
(d)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(e)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとにおいて、該TSDが異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップと
を含む、プログラム。
(項目15-1) 前記項目のいずれか1つまたは複数に記載の特徴をさらに備える、前記項目に記載のプログラム。
(項目16) 配列中の転移因子を特定する方法をコンピュータに実行させるためのプログラムを格納する記録媒体であって、該方法が、
(a)第1のゲノム配列データおよび第2のゲノム配列データを受け取るステップと、
(b)該第1のゲノム配列データおよび該第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(c)該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップと、
(d)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(e)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとにおいて、該TSDが異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップと
を含む、記録媒体。
(項目16-1) 前記項目のいずれか1つまたは複数に記載の特徴をさらに備える、前記項目に記載の記録媒体。
(項目17) 配列中の転移因子を特定するためのシステムであって、該システムは、1つ以上のプロセッサと、メモリと、プログラムを格納する記録媒体とを備え、該プログラムは、該1つ以上のプロセッサによって実行されると、以下:
(a)第1のゲノム配列データおよび第2のゲノム配列データを受け取るステップと、
(b)該第1のゲノム配列データおよび該第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(c)該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列
と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップと、
(d)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(e)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとにおいて、該TSDが異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップと
を含む方法を実装する、システム。
(項目17-1) 前記項目のいずれか1つまたは複数に記載の特徴をさらに備える、前記項目に記載のシステム。
(項目18) 配列中の転移因子を特定するためのシステムであって、該システムは、以下:
(A)第1のゲノム配列データおよび第2のゲノム配列データを受け取る配列データ受信部と、
(B)該配列データ受信部で得られた該第1のゲノム配列データおよび該第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成し、
該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜し、
【0006】
さらに本開示は以下を提供する。
(項目A1) 配列中の転移因子を特定する方法であって、
(A)第1のゲノム配列データおよび第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(B)該切り出し配列のそれぞれについて、n塩基長の標的部位重複(TSD)に該当する配列を含む部分と、該TSDに該当する配列を含まない部分とに区別し、同一のTSD
を含む切り出し配列のペアを選抜するステップと、
(C)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(D)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとにおいて、該TSDが異なる配列を有する切り出し配列のペアを転移因子対応ペアとして選抜するステップと
を含む、方法。
(項目A2) ステップ(B)が、前記TSDに該当する配列と前記TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップである、上記項目に記載の方法。
(項目A3) ステップ(B)が、前記TSDに該当する配列を含む部分と前記TSDに該当する配列を含まない部分とに区別し、前半部分の3’末端にTSDに該当する配列を含む切り出し配列と後半部分の5’末端にTSDに該当する配列を含む切り出し配列とにおいて、同一のTSDを含む切り出し配列のペアを選抜するステップである、上記項目のいずれかに記載の方法。
(項目A4) 前記TSDに該当する配列を含む部分と前記TSDに該当する配列を含まない部分との区別が、前記切り出し配列の半分で区別することを含む、上記項目のいずれかに記載の方法。
(項目A5) ステップ(B)が、さらに、前記切り出し配列をリファレンス配列上にマッピングすることにより、前記TSDに該当する配列を含む部分および前記TSDに該当する配列を含まない部分のゲノム上の位置を特定するステップを含む、上記項目のいずれかに記載の方法。
(項目A6) 前記ステップ(B)の前に、前記第1のゲノム配列データからの切り出し配列のセットと、前記第2のゲノム配列データからの切り出し配列のセットとで異なる切り出し配列を選抜するステップを含み、
5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアの選抜が、該第1のゲノム配列データからの切り出し配列のセットと、該第2のゲノム配列データからの切り出し配列のセットとで異なる切り出し配列の中から行われる、上記項目のいずれかに記載の方法。
(項目A7) 前記切り出し配列のセットにおいて、同一の切り出し配列の頻度を計算するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A8) 前記切り出し配列のセットにおいて、一定以下の頻度の切り出し配列を除外するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A9) 前記転移因子対応ペアに基づいて、転移因子配列を特定するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A10) 前記転移因子の転移活性を確認するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A11) 前記転移因子の転移活性の確認が、PCR、配列決定、およびハイブリダイゼーションから選択される1つ以上によってなされる、上記項目のいずれかに記載の方法。
(項目A12) ステップ(B)~(D)を、nを変更して繰り返すステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A13) nが3~20である、上記項目のいずれかに記載の方法。
(項目A14) 前記一定長が17~50塩基長である、上記項目のいずれかに記載の方法。
(項目A15) 前記対応する転移因子部分配列が、少なくとも90%の同一性を有する転移因子部分配列である、上記項目のいずれかに記載の方法。
(項目A16) 前記対応する転移因子部分配列が、少なくとも95%の同一性を有する転移因子部分配列である、上記項目のいずれかに記載の方法。
(項目A17) 前記対応する転移因子部分配列が、同一の転移因子部分配列である、上記項目のいずれかに記載の方法。
(項目A18) 前記切り出し配列のセットを生成するステップが、第1のゲノム配列データおよび第2のゲノム配列データの相補鎖について前記一定長の配列を1塩基ずつずらして切り出すことを含む、上記項目のいずれかに記載の方法。
(項目A19) nが5または8であり、かつ前記一定長が25塩基長である、上記項目のいずれかに記載の方法。
(項目A20) nが5または8であり、かつ前記一定長が40塩基長である、上記項目のいずれかに記載の方法。
(項目A21) 前記転移因子対応ペアに基づいて、前記転移因子の挿入位置を、前記TSDを含む個体とは異なる個体における参照配列と比較することにより、前記転移因子部分配列の挿入の有無および/または前記転移因子部分配列の挿入位置を特定するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A22) 前記転移因子対応ペアに基づいて、前記転移因子の挿入位置をリファレンス配列上にマッピングすることにより、前記転移因子部分配列の挿入の有無および/または前記転移因子部分配列の挿入位置を特定するステップをさらに含む、上記項目のいずれかに記載の方法。
(項目A23) 配列中の転移因子を特定する方法であって、
(A)2種類のサンプル由来のショートリードから、X塩基の配列を1塩基ずつずらして切り出す工程と、
(B)得られた複数のX塩基の各配列の頻度を取得する工程と、
(C)得られた複数のX塩基の配列において、ぞれぞれの配列の前半部分および後半部分のリファレンス配列上での位置を取得して比較する工程と、
を含む、方法。
(項目A24) 前記前半部分および前記後半部分の塩基長がX/2塩基である、上記項目のいずれかに記載の方法。
(項目A25) Xは20塩基以上である、上記項目のいずれかに記載の方法。
(項目A26) 配列中の転移因子の標的部位重複(TSD)及び/またはジャンクションを検出する方法であって、
(A)2種類のサンプル由来のショートリードから、X塩基の配列を1塩基ずつずらして切り出す工程と、
(B)得られた複数のX塩基の各配列の頻度を取得する工程と、
(C)得られた複数のX塩基の配列において、ぞれぞれの配列の前半部分および後半部分のリファレンス配列上での位置を取得して比較する工程と、
を含む、方法。
(項目A27) 前記前半部分および前記後半部分の塩基長がX/2塩基である、上記項目のいずれかに記載の方法。
(項目A28) Xは20塩基以上である、上記項目のいずれかに記載の方法。
(項目A29) 配列中の転移因子を特定する方法をコンピュータに実行させるためのプログラムであって、該方法が、
(a)第1のゲノム配列データおよび第2のゲノム配列データを受け取るステップと、
(b)該第1のゲノム配列データおよび該第2のゲノム配列データから、一定長の配列を1塩基ずつずらして切り出し、第1のゲノム配列データからの切り出し配列のセットと第2のゲノム配列データからの切り出し配列のセットを生成するステップと、
(c)該切り出し配列のそれぞれを、n塩基長の標的部位重複(TSD)に該当する配列と該TSD以外の配列(転移因子部分配列)とに区別し、5’末端のTSDと3’末端のTSDとが同一である切り出し配列のペアを選抜するステップと、
(d)該選抜されたペアから、対応する転移因子部分配列を有する切り出し配列のペアを選抜するステップと、
(e)該対応する転移因子部分配列を有する切り出し配列のペアから、該第1のゲノム配
【0007】
本開示において、上記1または複数の特徴は、明示された組み合わせに加え、さらに組み合わせて提供され得ることが意図される。本開示のなおさらなる実施形態および利点は、必要に応じて以下の詳細な説明を読んで理解すれば、当業者に認識される。
【発明の効果】
【0008】
本開示の方法は、リファレンス配列との比較を行う必要なく、次世代シーケンサーの配列解析のみから、新規の活性のある転移因子の転移を検出できる。塩基配列情報を用いて配列既知のトランスポゾンの転移を検出する手法はいくつか公知であるが、本開示の方法は、配列自体も分からなかった新規の転移因子の新たな転移を正確に捉えることが可能である。
【0009】
リファレンスゲノム配列がまだ存在しない生物の場合でも活性のあるトランスポゾンを見つけることができるので、作物に加えて野菜、果樹、花き等でのトランスポゾン検出とその育種に利用され得る。花きでは斑入りのコントロール、作物、果樹、野菜では、耐病性・耐乾燥性の付与等、収量の増大、食味の向上、収穫時期の改変等の様々な応用が想定される。動物などの分野では、トランスポゾンが関与する種々の特性(例えば、疾患、障害などを含む状態、あるいは、個性に関連する特性等)を特定することや、それに基づく診断、特性改変等に応用することができる。
【図面の簡単な説明】
【0010】
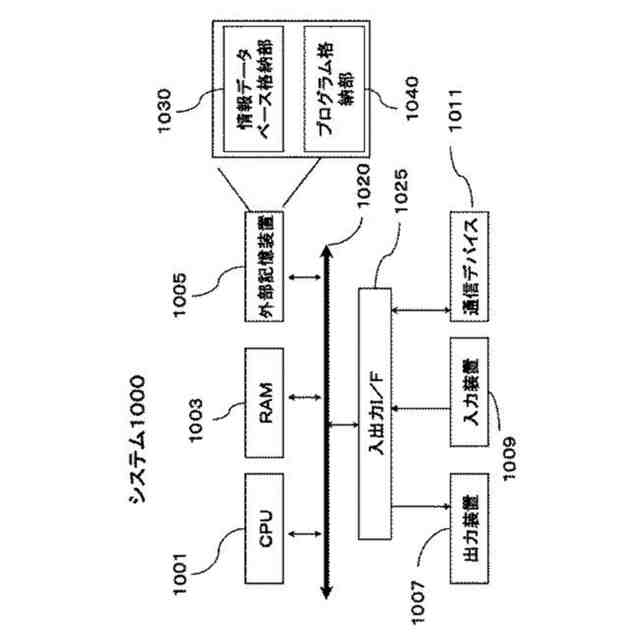
図1は、本開示のシステムの実施形態を模式的に示した図である。
図2は、本開示のシステムのさらなる実施形態を模式的に示した図である。
図3は、本開示の一実施形態に係るアルゴリズム1の方法によって特定される転移配列の模式図である。
図4は、本開示の一実施形態に係るアルゴリズム2の方法によって特定される転移配列の模式図である。
図5は、レトロトランスポゾンTos17のLTR配置を示す模式図である。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る





 特許ウォッチ
特許ウォッチ