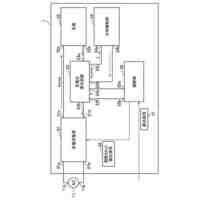
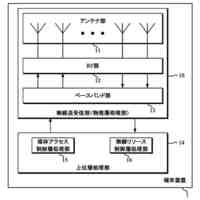
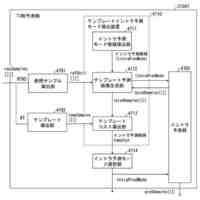
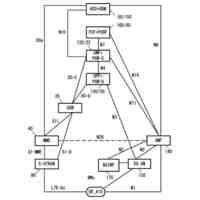
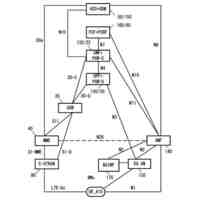
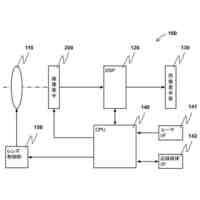
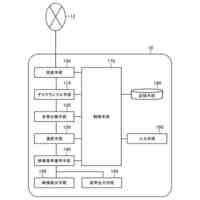
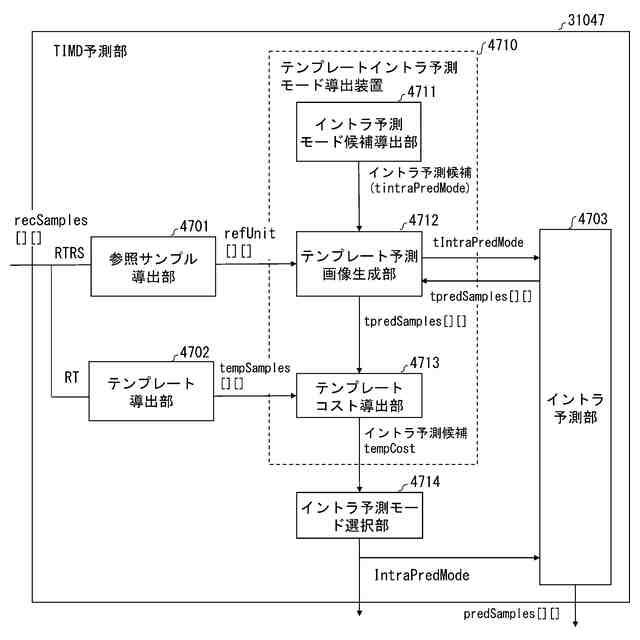
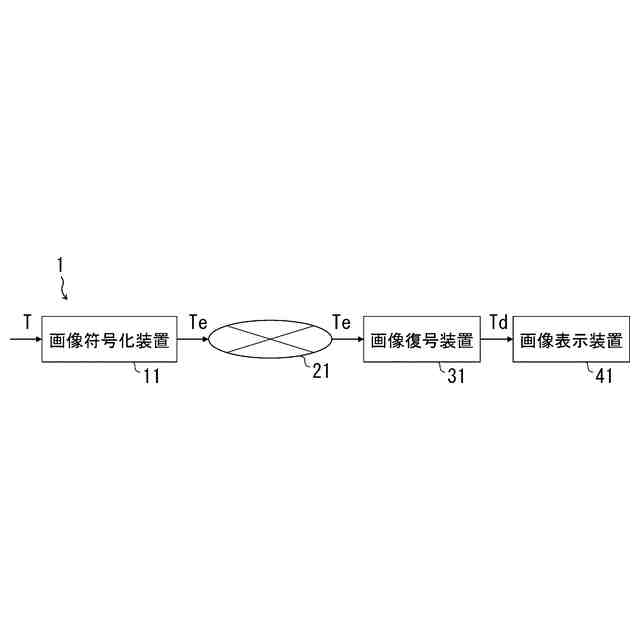
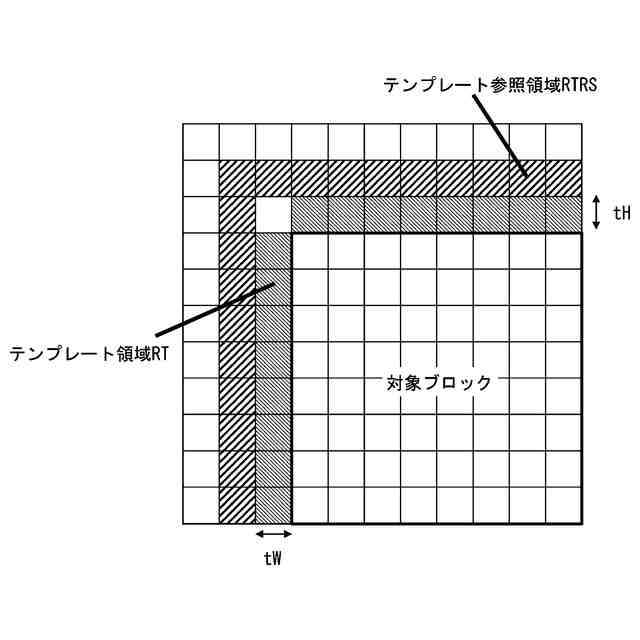
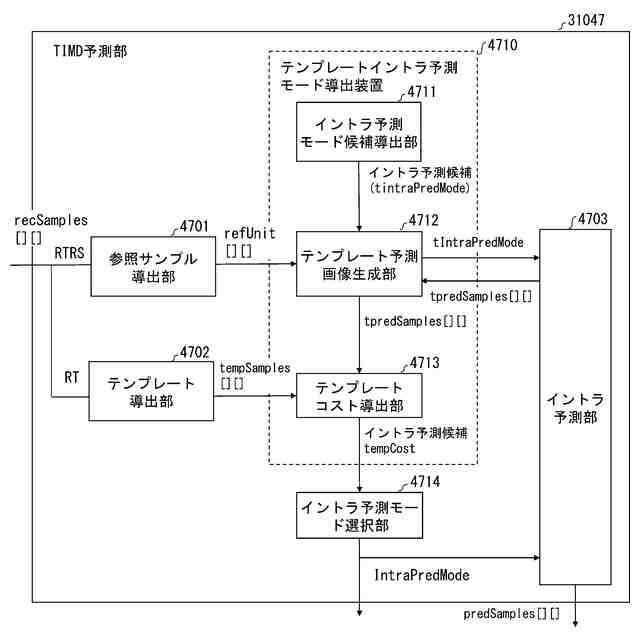
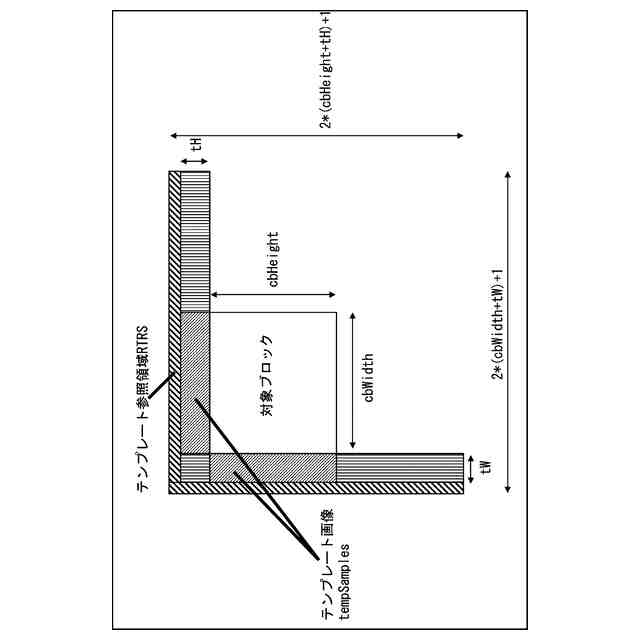
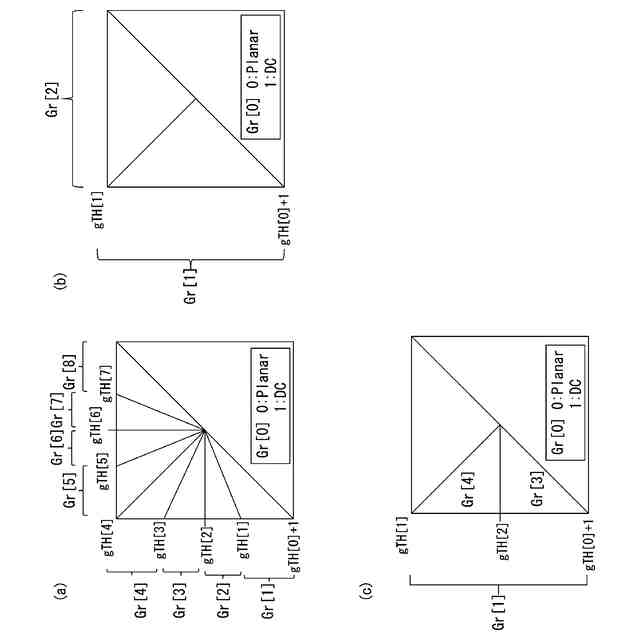
発明の詳細な説明【技術分野】 【0001】 本発明の実施形態は、動画像復号装置および動画像符号化装置に関する。 続きを表示(約 1,800 文字)【背景技術】 【0002】 動画像を効率的に伝送または記録するために、動画像を符号化することによって符号化データを生成する動画像符号化装置、および、当該符号化データを復号することによって復号画像を生成する動画像復号装置が用いられている。 【0003】 具体的な動画像符号化方式としては、例えば、H.264/AVCやHEVC(High-Efficiency Video Coding)、VVC(Versatile Video Coding)方式などが挙げられる。 【0004】 このような動画像符号化方式においては、動画像を構成する画像(ピクチャ)は、画像を分割することにより得られるスライス、スライスを分割することにより得られる符号化ツリーユニット(CTU:Coding Tree Unit)、符号化ツリーユニットを分割することで得られる符号化単位(符号化ユニット(Coding Unit:CU)と呼ばれることもある)、及び、符号化単位を分割することより得られる変換ユニット(TU:Transform Unit)からなる階層構造により管理され、CU毎に符号化/復号される。 【0005】 また、このような動画像符号化方式においては、通常、入力画像を符号化/復号することによって得られる局所復号画像に基づいて予測画像が生成され、当該予測画像を入力画像(原画像)から減算して得られる予測誤差(「差分画像」または「残差画像」と呼ぶこともある)が符号化される。予測画像の生成方法としては、画面間予測(インター予測)、および、画面内予測(イントラ予測)が挙げられる。 【0006】 また、近年の動画像符号化及び復号の技術として非特許文献1が挙げられる。非特許文献1には、デコーダが隣接領域の画素を用いてイントラ方向予測モード番号を導出することにより予測画像を生成するテンプレートベースイントラモード導出(Template based Intra Mode Derivation, TIMD)予測が開示されている。 【先行技術文献】 【非特許文献】 【0007】 K. Cao, N. Hu, V. Seregin, M. Karczewicz, Y. Wang, K. Zhang, L. Zhang, “EE2-related: Fusion for template-based intra mode derivation”, JVET-W0123, July 2021 【発明の概要】 【発明が解決しようとする課題】 【0008】 非特許文献1のようなテンプレートベースイントラモード導出では、対象ブロックの付近のテンプレート参照領域の画像を用いて、イントラ予測モード候補に対する対象ブロックの隣接画像(テンプレート画像)からテンプレート予測画像を生成する。そして、テンプレート画像とテンプレート予測画像のコストが小さくなるイントラ予測モード候補を、対象ブロックのイントラ予測モードとして選択する。しかしながら、複数のイントラ予測モード候補に対するテンプレート予測画像の導出とコスト計算が必要であり、計算量が非常に大きいという課題がある。 【0009】 本発明は、テンプレートベースイントラモード導出の複雑度を低減することを目的とする。 【課題を解決するための手段】 【0010】 本実施例の動画像復号装置は、テンプレート領域とテンプレート参照領域の画像を用いて、テンプレート画像と所定のイントラ予測モード候補に対するテンプレート予測画像を生成し、テンプレート予測画像とテンプレート画像から導出したコストに基づいて、対象ブロックのイントラ予測モードを選択するTIMD予測において、所定のイントラ予測モード候補を予測方向に基づいて複数のグループに分割し、各グループから選択したイントラ予測モード候補毎にテンプレート予測画像を生成してコストを評価し、最もコストが低いイントラ予測モード候補が属するグループでは、前記選択したイントラ予測モード候補以外の候補についてもコストの導出と選択を行うことを特徴とする。 【発明の効果】 (【0011】以降は省略されています) この特許をJ-PlatPatで参照する
 特許ウォッチ
特許ウォッチ