TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2024095309
公報種別
公開特許公報(A)
公開日
2024-07-10
出願番号
2022212499
出願日
2022-12-28
発明の名称
情報処理装置、情報処理方法及びプログラム
出願人
日本電気株式会社
代理人
弁理士法人 HARAKENZO WORLD PATENT & TRADEMARK
主分類
G06N
20/00 20190101AFI20240703BHJP(計算;計数)
要約
【課題】正解なしデータを用いる機械学習において推論精度の高い学習モデルを生成する技術を提供する。
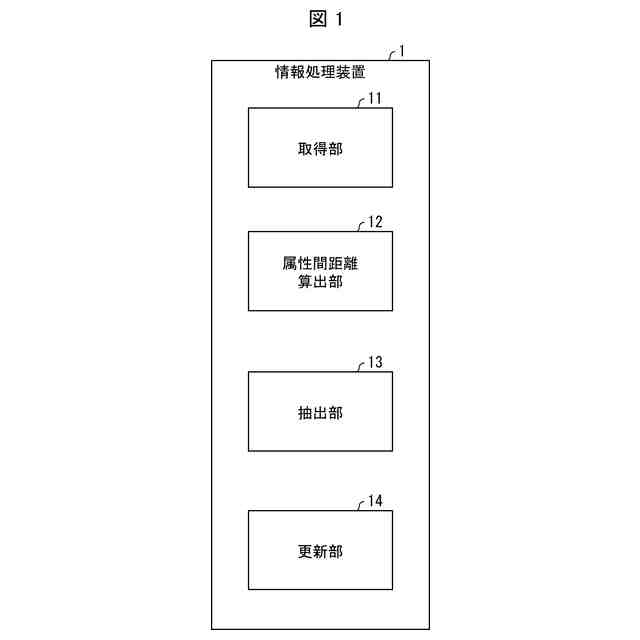
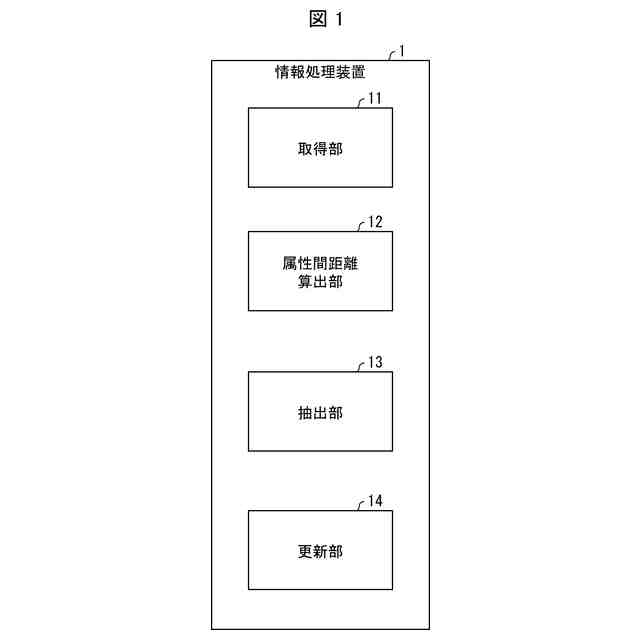
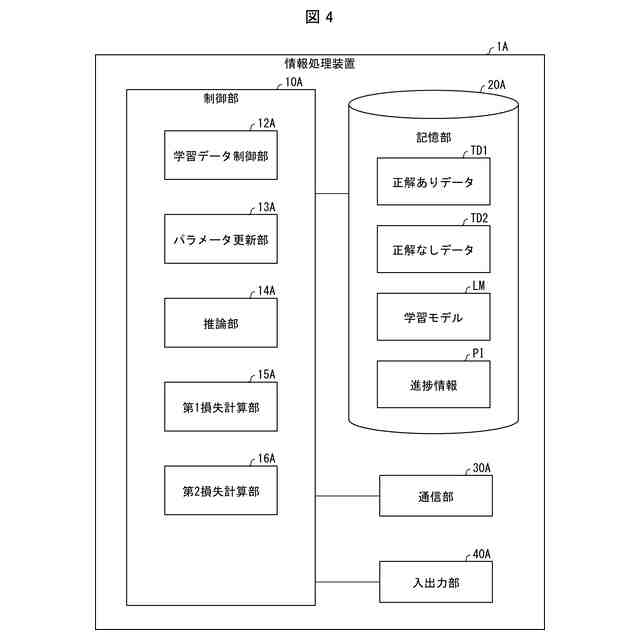
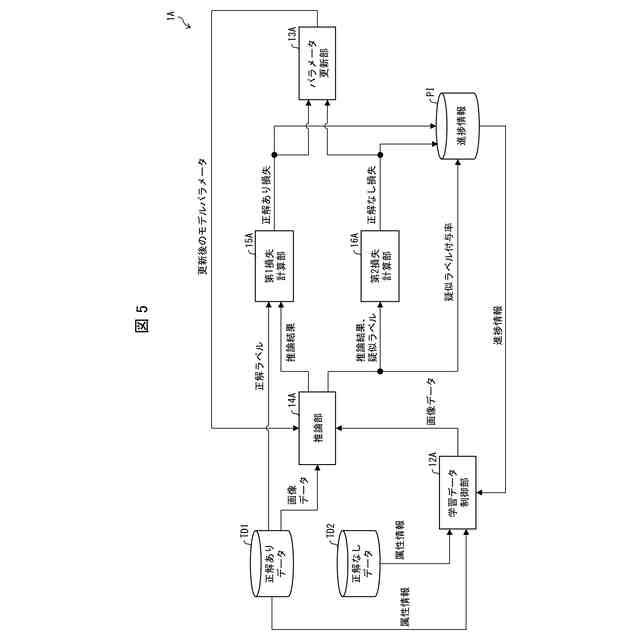
【解決手段】情報処理装置(1)は、画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得する取得部(11)と、上記正解ありデータの属性情報と上記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出する属性間距離算出部(12)と、複数の上記正解なしデータの中から、上記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出する抽出部(13)と、上記正解ありデータと上記抽出部(13)が抽出した正解なしデータとを用いて学習モデルのモデルパラメータを更新する更新部(14)と、を備える。
【選択図】図1
特許請求の範囲
【請求項1】
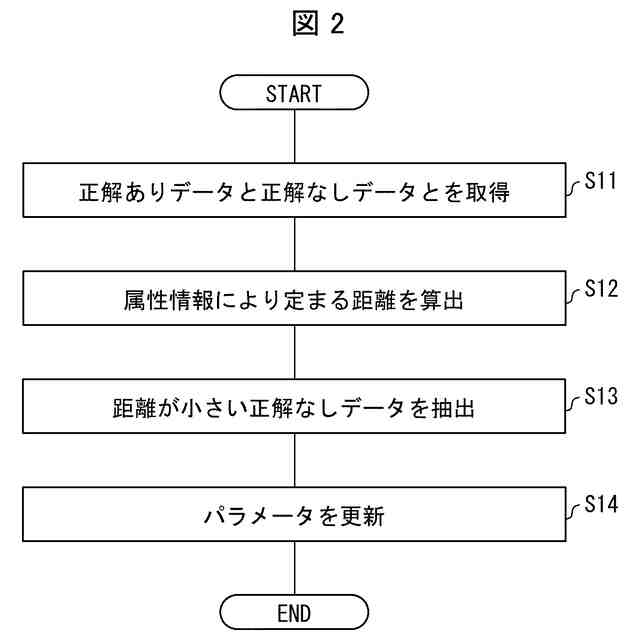
画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得する取得手段と、
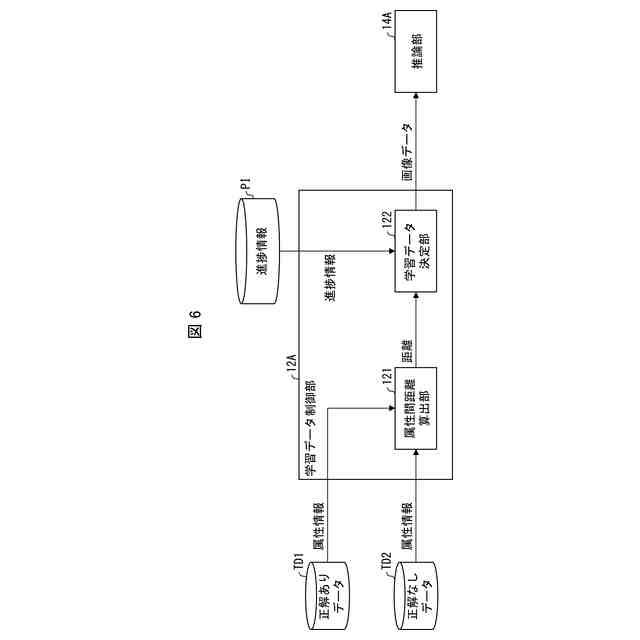
前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出する属性間距離算出手段と、
複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出する抽出手段と、
前記正解ありデータと前記抽出手段が抽出した正解なしデータとを用いて学習モデルのモデルパラメータを更新する更新手段と、
を備える情報処理装置。
続きを表示(約 1,900 文字)
【請求項2】
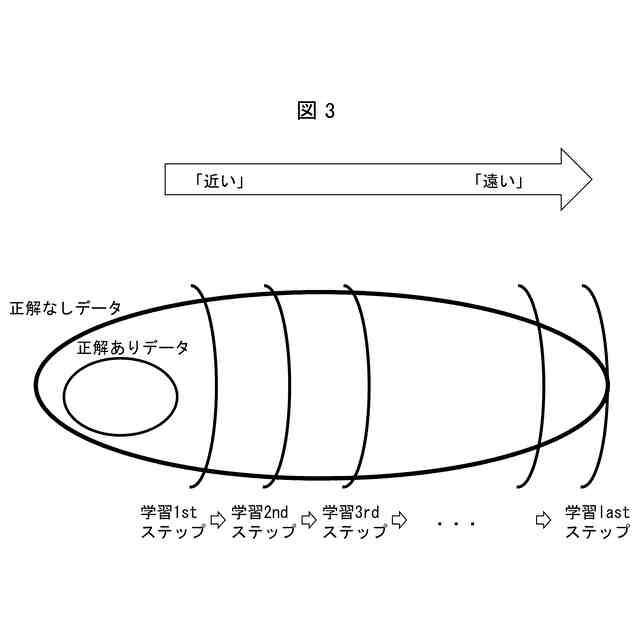
前記抽出手段は、前記学習モデルの学習が進むにつれて抽出する正解なしデータの距離の最大値が大きくなるように前記正解なしデータの抽出を行う、
請求項1に記載の情報処理装置。
【請求項3】
前記抽出手段が抽出した正解なしデータを前記学習モデルに入力して得られる推論結果に基づき、当該正解なしデータに擬似ラベルを付与する擬似ラベル付与手段を更に備え、
前記更新手段は、前記擬似ラベルが付与された正解なしデータと、前記正解ありデータとを用いて前記学習モデルのモデルパラメータを更新する、
請求項1又は2に記載の情報処理装置。
【請求項4】
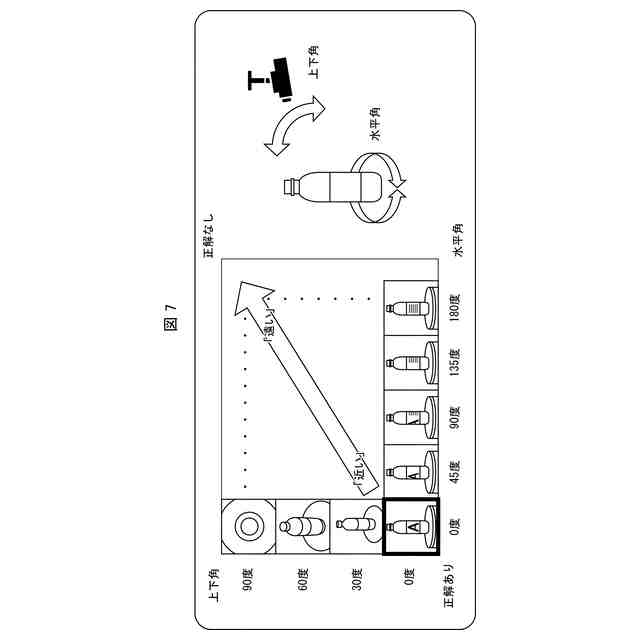
前記属性情報は、前記画像に含まれる物体の姿勢及び位置、撮影時刻、撮影時間帯、撮影装置の種類及び位置、並びに画質、の少なくともいずれかを示す情報を含み、
前記距離は、前記画像に含まれる物体の姿勢差及び位置の差、撮影時刻差、撮影時間帯の近さ、撮影装置の種類の類似の度合い、撮影装置の位置の差、並びに画質差、の少なくともいずれかに基づき算出される値である、
請求項1又は2に記載の情報処理装置。
【請求項5】
前記抽出手段が抽出した正解なしデータを前記学習モデルに入力して得られる推論結果が所定の条件を満たす正解なしデータに擬似ラベルを付与する擬似ラベル付与手段を更に備え、
前記抽出手段は、抽出した正解なしデータに対する前記擬似ラベルの付与率が所定の収束判定条件を満たす度に、抽出する正解なしデータの数を増加させる、
請求項2に記載の情報処理装置。
【請求項6】
前記抽出手段が抽出した正解なしデータを前記学習モデルに入力して得られる推論結果が所定の条件を満たす正解なしデータに擬似ラベルを付与する擬似ラベル付与手段を更に備え、
前記抽出手段は、抽出した正解なしデータに対する前記擬似ラベルの付与率が所定の閾値を超える度に、抽出する正解なしデータの数を増加させる、
請求項2に記載の情報処理装置。
【請求項7】
前記抽出手段は、前記学習モデルの学習時間が所定の閾値に達する毎に、抽出する正解なしデータの数を増加させる、
請求項2に記載の情報処理装置。
【請求項8】
前記抽出手段が抽出した正解なしデータを前記学習モデルに入力して得られる推論結果に基づき当該正解なしデータに擬似ラベルを付与する擬似ラベル付与手段と、
前記正解ありデータと前記学習モデルとを用いた推論結果と、当該正解ありデータの正解ラベルと、を用いて損失を算出する第1損失算出手段と、
前記正解なしデータと前記学習モデルとを用いた推論結果と、当該正解なしデータの擬似ラベルと、を用いて損失を算出する第2損失算出手段と、
を更に備え、
前記抽出手段は、前記第1損失算出手段が算出した損失と前記第2損失算出手段が算出した損失との和又は重み付き和が所定の収束判定条件を満たす度に、抽出する正解なしデータの数を増加させる、
請求項2に記載の情報処理装置。
【請求項9】
少なくとも1つのプロセッサが、
画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得することと、
前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出することと、
複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出することと、
前記正解ありデータと前記抽出された正解なしデータとを用いて学習モデルのモデルパラメータを更新することと、
を含む、情報処理方法。
【請求項10】
コンピュータに、
画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得する処理と、
前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出する処理と、
複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出する処理と、
前記正解ありデータと前記抽出された正解なしデータとを用いて学習モデルのモデルパラメータを更新する処理と、
を実行させるためのプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、機械学習により学習モデルを生成する技術に関する。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
教師あり学習では、正解ラベルが付された大量の教師データを用いて学習を行うことで高精度な学習済モデルを構築することができる。しかしながら、教師データを大量に用意するためには大量の画像収集及び正解ラベル付け等を行う必要があり、作業コストが高いという問題がある。そこで、少ない正解ありデータと大量の正解なしデータとから学習済モデルを高精度に実現する手法が提案されている(例えば非特許文献1、特許文献1等参照)。
【先行技術文献】
【特許文献】
【0003】
国際公開第2014/136316号
【非特許文献】
【0004】
Kihyuk Sohn et al., FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence, NeurIPS (2020)
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、非特許文献1及び特許文献1に記載の技術では、正解なしデータについて誤った擬似ラベルが生成されたり、学習がうまく進まなかったりするという問題があり、学習モデルの推論精度を高くするという観点において改善の余地がある。
【0006】
本発明の一態様は、上記の問題に鑑みてなされたものであり、その目的の一例は、正解なしデータを用いる機械学習において推論精度の高い学習モデルを生成する技術を提供することである。
【課題を解決するための手段】
【0007】
本発明の一態様に係る情報処理装置は、画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得する取得手段と、前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出する属性間距離算出手段と、複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出する抽出手段と、前記正解ありデータと前記抽出手段が抽出した正解なしデータとを用いて学習モデルのモデルパラメータを更新する更新手段とを備える。
【0008】
本発明の一態様に係る情報処理方法は、少なくとも1つのプロセッサが、画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得することと、前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出することと、複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出することと、前記正解ありデータと前記抽出された正解なしデータとを用いて学習モデルのモデルパラメータを更新することと、を含む。
【0009】
本発明の一態様に係るプログラムは、コンピュータに、画像データに画像の属性を示す属性情報及び正解ラベルが付された正解ありデータと、画像データに画像の属性を示す属性情報が付された正解なしデータとを取得する処理と、前記正解ありデータの属性情報と前記正解なしデータの属性情報とにより定まる、当該正解ありデータと当該正解なしデータとの距離を算出する処理と、複数の前記正解なしデータの中から、前記正解ありデータとの距離が他の正解なしデータよりも小さい正解なしデータを抽出する処理と、前記正解ありデータと前記抽出された正解なしデータとを用いて学習モデルのモデルパラメータを更新する処理と、を実行させるためのプログラムである。
【発明の効果】
【0010】
本発明の一態様によれば、正解なしデータを用いる機械学習において推論精度の高い学習モデルを生成することができる。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
他の特許を見る
 特許ウォッチ
特許ウォッチ